Индекси- това е първото нещо, което трябва да разберете добре в работата си SQL сървър, но странно, основните въпроси не се задават много често във форумите и не получават много отговори.
Роб Шелдънотговаря на тези въпроси, които предизвикват объркване в професионалните среди относно индексите в SQL сървър: някои от тях просто ни е неудобно да попитаме, но преди да попитаме други, първо ще помислим два пъти.
Използвана терминология:
| индекс | индекс |
| купчина | куп |
| маса | маса |
| изглед | производителност |
| B-дърво | балансирано дърво |
| клъстерен индекс | клъстерен индекс |
| неклъстъриран индекс | неклъстъриран индекс |
| съставен индекс | съставен индекс |
| покривен индекс | покривен индекс |
| ограничение за първичен ключ | ограничение за първичен ключ |
| уникално ограничение | ограничение на уникалността на стойностите |
| заявка | искане |
| машина за заявки | подсистема за заявки |
| база данни | база данни |
| двигател на база данни | подсистема за съхранение |
| фактор на запълване | коефициент на запълване на индекса |
| сурогатен първичен ключ | сурогатен първичен ключ |
| оптимизатор на заявки | оптимизатор на заявки |
| селективност на индекса | селективност на индекса |
| филтриран индекс | филтрируем индекс |
| план за изпълнение | план за изпълнение |
Основи на индексите в SQL Server.
Един от най-важните начини за постигане на висока производителност SQL сървъре използването на индекси. Индексът ускорява процеса на заявка, като предоставя бърз достъп до редове с данни в таблица, подобно на индекса в книга, който ви помага бързо да намерите информацията, от която се нуждаете. В тази статия ще направя кратък преглед на индексите в SQL сървъри обяснете как са организирани в базата данни и как спомагат за ускоряване на заявките към базата данни.
Индексите се създават върху колони на таблица и изглед. Индексите предоставят начин за бързо търсене на данни въз основа на стойностите в тези колони. Например, ако създадете индекс на първичен ключ и след това търсите ред от данни, като използвате стойностите на първичния ключ, тогава SQL сървърпърво ще намери стойността на индекса и след това ще използва индекса, за да намери бързо целия ред от данни. Без индекс ще се извърши пълно сканиране на всички редове в таблицата, което може да има значително въздействие върху производителността.
Можете да създадете индекс на повечето колони в таблица или изглед. Изключение правят главно колоните с типове данни за съхранение на големи обекти ( LOB), като изображение, текстили varchar(макс.). Можете също така да създавате индекси на колони, предназначени да съхраняват данни във формата XML, но тези индекси са структурирани малко по-различно от стандартните и тяхното разглеждане е извън обхвата на тази статия. Освен това статията не обсъжда columnstoreиндекси. Вместо това се фокусирам върху онези индекси, които се използват най-често в базите данни SQL сървър.
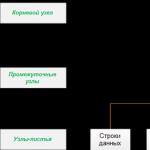
Индексът се състои от набор от страници, индексни възли, които са организирани в дървовидна структура - балансирано дърво. Тази структура е йерархична по природа и започва с основен възел в горната част на йерархията и листови възли, листата, в долната част, както е показано на фигурата:
Когато правите заявка за индексирана колона, машината за заявки започва от горната част на основния възел и преминава надолу през междинните възли, като всеки междинен слой съдържа по-подробна информация за данните. Машината за заявки продължава да се движи през индексните възли, докато достигне най-долното ниво с листата на индекса. Например, ако търсите стойността 123 в индексирана колона, машината за заявки първо ще определи страницата на първото междинно ниво на основното ниво. В този случай първата страница сочи към стойност от 1 до 100, а втората от 101 до 200, така че системата за заявки ще има достъп до втората страница от това междинно ниво. След това ще видите, че трябва да обърнете към третата страница от следващото междинно ниво. От тук подсистемата за заявки ще прочете стойността на самия индекс на по-ниско ниво. Листовете на индекса могат да съдържат или самите данни от таблицата, или просто указател към редове с данни в таблицата, в зависимост от типа на индекса: клъстерен индекс или неклъстерен индекс.
Клъстерен индекс
Клъстърираният индекс съхранява действителните редове от данни в листата на индекса. Връщайки се към предишния пример, това означава, че редът от данни, свързан с ключовата стойност 123, ще бъде съхранен в самия индекс. Важна характеристика на клъстерирания индекс е, че всички стойности са сортирани в определен ред, възходящ или низходящ. Следователно една таблица или изглед може да има само един клъстерен индекс. Освен това трябва да се отбележи, че данните в таблица се съхраняват в сортирана форма само ако в тази таблица е създаден клъстерен индекс.
Таблица, която няма клъстерен индекс, се нарича куп.
Неклъстъриран индекс
За разлика от клъстерния индекс, листата на неклъстерния индекс съдържат само тези колони ( ключ), по който се определя този индекс, а също така съдържа указател към редове с реални данни в таблицата. Това означава, че системата за подзапитване изисква допълнителна операция за намиране и извличане на необходимите данни. Съдържанието на указателя на данни зависи от това как се съхраняват данните: клъстерна таблица или куп. Ако указател сочи към клъстерирана таблица, той сочи към клъстерен индекс, който може да се използва за намиране на действителните данни. Ако указателят препраща към купчина, тогава той сочи към конкретен идентификатор на ред с данни. Неклъстерираните индекси не могат да бъдат сортирани като клъстерираните индекси, но можете да създадете повече от един неклъстерен индекс в таблица или изглед, до 999. Това не означава, че трябва да създадете възможно най-много индекси. Индексите могат или да подобрят, или да влошат производителността на системата. В допълнение към възможността да създавате множество негрупирани индекси, можете също да включите допълнителни колони ( включена колона) в неговия индекс: листата на индекса ще съхраняват не само стойността на самите индексирани колони, но и стойностите на тези неиндексирани допълнителни колони. Този подход ще ви позволи да заобиколите някои от ограниченията, поставени върху индекса. Например, можете да включите неиндексируема колона или да заобиколите ограничението за дължина на индекса (900 байта в повечето случаи).
Видове индекси
Освен че е клъстерен или неклъстериран, индексът може да бъде допълнително конфигуриран като съставен индекс, уникален индекс или покриващ индекс.
Композитен индекс
Такъв индекс може да съдържа повече от една колона. Можете да включите до 16 колони в индекс, но общата им дължина е ограничена до 900 байта. И клъстерираните, и неклъстерираните индекси могат да бъдат съставни.
Уникален индекс
Този индекс гарантира, че всяка стойност в индексираната колона е уникална. Ако индексът е съставен, тогава уникалността се отнася за всички колони в индекса, но не и за всяка отделна колона. Например, ако създадете уникален индекс на колоните ИМЕИ ФАМИЛИЯ, тогава пълното име трябва да е уникално, но са възможни дубликати в собственото или фамилното име.
Уникален индекс се създава автоматично, когато дефинирате ограничение за колона: първичен ключ или ограничение за уникална стойност:
- Първичен ключ
Когато дефинирате ограничение за първичен ключ за една или повече колони, тогава SQL сървъравтоматично създава уникален клъстерен индекс, ако клъстерен индекс не е бил създаден преди това (в този случай уникален неклъстериран индекс се създава на първичния ключ) - Уникалност на ценностите
Когато дефинирате ограничение за уникалността на стойностите тогава SQL сървъравтоматично създава уникален негрупиран индекс. Можете да укажете да бъде създаден уникален клъстерен индекс, ако в таблицата все още не е създаден клъстерен индекс
Индекс на покритие
Такъв индекс позволява на конкретна заявка незабавно да получи всички необходими данни от листата на индекса без допълнителен достъп до записите на самата таблица.
Проектиране на индекси
Колкото и полезни да са индексите, те трябва да бъдат проектирани внимателно. Тъй като индексите могат да заемат значително дисково пространство, не искате да създавате повече индекси от необходимото. В допълнение, индексите се актуализират автоматично, когато се актуализира самият ред с данни, което може да доведе до допълнителни разходи за ресурси и влошаване на производителността. При проектирането на индекси трябва да се вземат предвид няколко съображения относно базата данни и заявките към нея.
База данни
Както беше отбелязано по-рано, индексите могат да подобрят производителността на системата, защото... те предоставят на машината за заявки бърз начин за намиране на данни. Трябва обаче също така да вземете предвид колко често възнамерявате да вмъквате, актуализирате или изтривате данни. Когато промените данни, индексите също трябва да бъдат променени, за да отразяват съответните действия върху данните, което може значително да намали производителността на системата. Имайте предвид следните насоки, когато планирате своята стратегия за индексиране:
- За таблици, които се актуализират често, използвайте възможно най-малко индекси.
- Ако таблицата съдържа голямо количество данни, но промените са незначителни, тогава използвайте толкова индекси, колкото е необходимо, за да подобрите производителността на вашите заявки. Въпреки това, помислете внимателно, преди да използвате индекси на малки таблици, защото... Възможно е използването на индексно търсене да отнеме повече време от простото сканиране на всички редове.
- За групирани индекси се опитайте да запазите полетата възможно най-кратки. Най-добрият подход е да използвате клъстерен индекс върху колони, които имат уникални стойности и не позволяват NULL. Ето защо първичен ключ често се използва като клъстерен индекс.
- Уникалността на стойностите в колона влияе върху производителността на индекса. Като цяло, колкото повече дубликати имате в колона, толкова по-лошо се представя индексът. От друга страна, колкото повече уникални стойности има, толкова по-добра е производителността на индекса. Използвайте уникален индекс, когато е възможно.
- За съставен индекс вземете под внимание реда на колоните в индекса. Колони, които се използват в изрази КЪДЕТО(Например, WHERE FirstName = 'Чарли') трябва да е първи в индекса. Следващите колони трябва да бъдат изброени въз основа на уникалността на техните стойности (колоните с най-голям брой уникални стойности са първи).
- Можете също да зададете индекс за изчисляеми колони, ако отговарят на определени изисквания. Например, изразите, използвани за получаване на стойността на колона, трябва да бъдат детерминирани (винаги да връщат един и същ резултат за даден набор от входни параметри).
Заявки към бази данни
Друго съображение при проектирането на индекси е какви заявки се изпълняват към базата данни. Както беше посочено по-рано, трябва да имате предвид колко често се променят данните. Освен това трябва да се използват следните принципи:
- Опитайте се да вмъкнете или промените възможно най-много редове в една заявка, вместо да го правите в няколко отделни заявки.
- Създайте негрупиран индекс на колони, които често се използват като думи за търсене във вашите заявки. КЪДЕТОи връзки в ПРИСЪЕДИНЯВАНЕ.
- Помислете за индексиране на колони, използвани в заявки за търсене на редове за точни съвпадения на стойности.
Защо една таблица не може да има два групирани индекса?
Искате ли кратък отговор? Клъстърираният индекс е таблица. Когато създадете клъстерен индекс на таблица, механизмът за съхранение сортира всички редове в таблицата във възходящ или низходящ ред, според дефиницията на индекса. Клъстерираният индекс не е отделен обект като другите индекси, а механизъм за сортиране на данни в таблица и улесняване на бърз достъп до редове с данни.
Нека си представим, че имате таблица, съдържаща историята на транзакциите за продажба. Таблицата Продажби включва информация като ID на поръчката, позиция на продукта в поръчката, номер на продукта, количество на продукта, номер на поръчка и дата и т.н. Създавате групиран индекс на колони OrderIDИ LineID, сортирани във възходящ ред, както е показано по-долу T-SQLкод:
Когато стартирате този скрипт, всички редове в таблицата ще бъдат физически сортирани първо по колоната OrderID и след това по LineID, но самите данни ще останат в един логически блок, таблицата. Поради тази причина не можете да създадете два клъстерирани индекса. Може да има само една таблица с едни данни и тази таблица може да бъде сортирана само веднъж в определен ред.
Ако една клъстерирана таблица предоставя много предимства, тогава защо да използвате купчина?
Прав си. Клъстерираните таблици са страхотни и повечето от вашите заявки ще се представят по-добре на таблици, които имат клъстерен индекс. Но в някои случаи може да искате да оставите масите в тяхното естествено, девствено състояние, т.е. под формата на купчина и създавайте само неклъстерирани индекси, за да поддържате вашите заявки изпълнявани.
Купчината, както си спомняте, съхранява данни в произволен ред. Обикновено подсистемата за съхранение добавя данни към таблица в реда, в който са вмъкнати, но подсистемата за съхранение също обича да мести редове за по-ефективно съхранение. В резултат на това нямате шанс да предвидите в какъв ред ще се съхраняват данните.
Ако машината за заявки трябва да намери данни без ползата от неклъстъриран индекс, тя ще направи пълно сканиране на таблицата, за да намери нужните редове. На много малки маси това обикновено не е проблем, но тъй като купчината нараства по размер, производителността бързо пада. Разбира се, неклъстъриран индекс може да помогне, като използва указател към файла, страницата и реда, където се съхраняват необходимите данни - това обикновено е много по-добра алтернатива на сканирането на таблица. Въпреки това е трудно да се сравняват предимствата на клъстерен индекс, когато се разглежда производителността на заявките.
Въпреки това купчината може да помогне за подобряване на производителността в определени ситуации. Помислете за таблица с много вмъквания, но малко актуализации или изтривания. Например, таблица, съхраняваща регистрационен файл, се използва предимно за вмъкване на стойности, докато не бъде архивирана. В купчината няма да видите страниране и фрагментиране на данни, както бихте направили с клъстерен индекс, защото редовете просто се добавят в края на купчината. Твърде честото разделяне на страници може да окаже значително влияние върху производителността, и то не по добър начин. Като цяло, купчината ви позволява да вмъквате данни сравнително безболезнено и няма да ви се налага да се справяте с режийните разходи за съхранение и поддръжка, както бихте направили с клъстерен индекс.
Но липсата на актуализиране и изтриване на данни не трябва да се счита за единствената причина. Начинът, по който данните са извадени, също е важен фактор. Например, не трябва да използвате купчина, ако често правите заявки за диапазони от данни или данните, които заявявате, често трябва да бъдат сортирани или групирани.
Всичко това означава, че трябва да обмислите използването на купчината само когато работите с много малки таблици или цялото ви взаимодействие с таблицата е ограничено до вмъкване на данни и вашите заявки са изключително прости (и използвате неклъстерирани индекси така или иначе). В противен случай се придържайте към добре проектиран клъстерен индекс, като такъв, дефиниран на просто възходящо ключово поле, като широко използвана колона с ИДЕНТИЧНОСТ.
Как да променя коефициента на запълване на индекса по подразбиране?
Промяната на коефициента на запълване на индекса по подразбиране е едно нещо. Разбирането как работи съотношението по подразбиране е друг въпрос. Но първо направете няколко крачки назад. Коефициентът на запълване на индекса определя количеството пространство на страницата за съхраняване на индекса на най-долното ниво (ниво на листа), преди да започне да попълва нова страница. Например, ако коефициентът е зададен на 90, тогава, когато индексът расте, той ще заема 90% от страницата и след това ще премине към следващата страница.
По подразбиране стойността на коефициента на запълване на индекса е включена SQL сървъре 0, което е същото като 100. В резултат на това всички нови индекси автоматично наследяват тази настройка, освен ако изрично не посочите стойност във вашия код, която е различна от системната стандартна стойност или промените поведението по подразбиране. Можеш да използваш SQL Server Management Studioза да коригирате стойността по подразбиране или да изпълните системна съхранена процедура sp_configure. Например следният набор T-SQLзадава стойността на коефициента на 90 (първо трябва да преминете към режим на разширени настройки):
EXEC sp_configure "покажи разширени опции ", 1; GO RECONFIGURE; GO EXEC sp_configure "коефициент на запълване", 90; GO RECONFIGURE; GO
След като промените стойността на коефициента на запълване на индекса, трябва да рестартирате услугата SQL сървър. Вече можете да проверите зададената стойност, като стартирате sp_configure без посочения втори аргумент:
EXEC sp_configure "фактор на запълване" GO
Тази команда трябва да върне стойност 90. В резултат на това всички новосъздадени индекси ще използват тази стойност. Можете да тествате това, като създадете индекс и направите заявка за стойността на фактора на запълване:
ИЗПОЛЗВАЙТЕ AdventureWorks2012; -- вашата база данни GO CREATE NONCLUSTERED INDEX ix_people_lastname ON Person.Person(LastName); GO SELECT fill_factor FROM sys .indexes WHERE object_id = object_id("Person.Person" ) AND name ="ix_people_lastname" ;В този пример създадохме неклъстъриран индекс на таблица Лицев базата данни AdventureWorks 2012. След като създадем индекса, можем да получим стойността на фактора на запълване от системните таблици sys.indexes. Заявката трябва да върне 90.
Нека обаче си представим, че сме изтрили индекса и сме го създали отново, но сега сме посочили конкретна стойност на коефициента на запълване:
Този път сме добавили инструкции СЪСи опция коефициент на запълванеза нашата операция по създаване на индекс СЪЗДАВАНЕ НА ИНДЕКСи посочи стойността 80. Оператор ИЗБЕРЕТЕсега връща съответната стойност.
Дотук всичко беше доста ясно. Където наистина можете да се изгорите в целия този процес е, когато създадете индекс, който използва стойност на коефициента по подразбиране, ако приемем, че знаете тази стойност. Например, някой бърника в настройките на сървъра и е толкова упорит, че е задал коефициента на запълване на индекса на 20. Междувременно вие продължавате да създавате индекси, като приемате, че стойността по подразбиране е 0. За съжаление, няма начин да разберете коефициента на запълване фактор, докато не създадете индекс и след това проверите стойността, както направихме в нашите примери. В противен случай ще трябва да изчакате момента, в който производителността на заявките спадне толкова много, че да започнете да подозирате нещо.
Друг проблем, с който трябва да сте наясно, е повторното изграждане на индекси. Както при създаването на индекс, можете да укажете стойността на фактора на запълване на индекса, когато го изграждате отново. Въпреки това, за разлика от командата create index, rebuild не използва настройките по подразбиране на сървъра, независимо от това, което може да изглежда. Още повече, ако не посочите конкретно стойността на коефициента на запълване на индекса, тогава SQL сървърще използва стойността на коефициента, с който е съществувал този индекс преди неговото преструктуриране. Например следната операция ПРОМЕНЯ ИНДЕКСвъзстановява индекса, който току-що създадохме:
Когато проверим стойността на фактора на запълване, ще получим стойност 80, защото това е, което сме посочили при последното създаване на индекса. Стойността по подразбиране се игнорира.
Както можете да видите, промяната на стойността на фактора на запълване на индекса не е толкова трудна. Много по-трудно е да се знае текущата стойност и да се разбере кога се прилага. Ако винаги конкретно указвате коефициента, когато създавате и преизграждате индекси, тогава винаги знаете конкретния резултат. Освен ако не трябва да се притеснявате да се уверите, че някой друг няма да прецака отново настройките на сървъра, причинявайки възстановяването на всички индекси с абсурдно нисък коефициент на запълване на индекса.
Възможно ли е да се създаде клъстериран индекс върху колона, която съдържа дубликати?
Да и не. Да, можете да създадете клъстерен индекс върху ключова колона, която съдържа дублиращи се стойности. Не, стойността на ключова колона не може да остане в неуникално състояние. Нека обясня. Ако създадете неуникален клъстериран индекс на колона, машината за съхранение добавя уникализатор към дублиращата се стойност, за да осигури уникалност и следователно да може да идентифицира всеки ред в клъстерната таблица.
Например, можете да решите да създадете клъстериран индекс върху колона, съдържаща данни за клиента Фамилиязапазване на фамилията. Колоната съдържа стойностите Франклин, Хенкок, Вашингтон и Смит. След това вмъквате отново стойностите Adams, Hancock, Smith и Smith. Но стойността на ключовата колона трябва да е уникална, така че машината за съхранение ще промени стойността на дубликатите, така че да изглеждат по следния начин: Адамс, Франклин, Хенкок, Хенкок1234, Вашингтон, Смит, Смит4567 и Смит5678.
На пръв поглед този подход изглежда добре, но целочислената стойност увеличава размера на ключа, което може да се превърне в проблем, ако има голям брой дубликати, и тези стойности ще станат основата на неклъстъриран индекс или чужд ключова справка. Поради тези причини винаги трябва да се опитвате да създавате уникални клъстерирани индекси, когато е възможно. Ако това не е възможно, опитайте поне да използвате колони с много високо уникално съдържание.
Как се съхранява таблицата, ако не е създаден клъстерен индекс?
SQL сървърподдържа два типа таблици: клъстерирани таблици, които имат клъстерен индекс и купчина таблици или само купчини. За разлика от клъстерираните таблици, данните в купчината не се сортират по никакъв начин. По същество това е куп (купчина) от данни. Ако добавите ред към такава таблица, системата за съхранение просто ще го добави в края на страницата. Когато страницата се запълни с данни, тя ще бъде добавена към нова страница. В повечето случаи ще искате да създадете групиран индекс на таблица, за да се възползвате от възможността за сортиране и скоростта на заявките (опитайте да си представите, че търсите телефонен номер в несортирана адресна книга). Въпреки това, ако решите да не създавате клъстерен индекс, все пак можете да създадете неклъстериран индекс в купчината. В този случай всеки индексен ред ще има указател към купчина ред. Индексът включва идентификатора на файла, номера на страницата и номера на реда за данни.
Каква е връзката между ограниченията за уникалност на стойността и първичния ключ с индексите на таблицата?
Първичен ключ и уникално ограничение гарантират, че стойностите в колона са уникални. Можете да създадете само един първичен ключ за таблица и той не може да съдържа стойности НУЛА. Можете да създадете няколко ограничения за уникалността на стойност за таблица и всяко от тях може да има един запис с НУЛА.
Когато създавате първичен ключ, системата за съхранение също създава уникален клъстериран индекс, ако вече не е създаден клъстерен индекс. Можете обаче да замените поведението по подразбиране и ще бъде създаден неклъстерен индекс. Ако съществува клъстерен индекс, когато създавате първичния ключ, ще бъде създаден уникален неклъстерен индекс.
Когато създадете уникално ограничение, машината за съхранение създава уникален, неклъстъриран индекс. Можете обаче да посочите създаването на уникален клъстерен индекс, ако такъв не е бил създаден преди това.
Като цяло, ограничение за уникална стойност и уникален индекс са едно и също нещо.
Защо клъстерираните и неклъстерираните индекси се наричат B-дърво в SQL Server?
Основните индекси в SQL Server, клъстерирани или неклъстерирани, се разпределят между набори от страници, наречени индексни възли. Тези страници са организирани в специфична йерархия с дървовидна структура, наречена балансирано дърво. На най-горното ниво има кореновия възел, на дъното има листовите възли, с междинни възли между горното и долното ниво, както е показано на фигурата:
Основният възел осигурява основната входна точка за заявки, опитващи се да извлекат данни чрез индекса. Започвайки от този възел, машината за заявки инициира навигация надолу по йерархичната структура до подходящия листов възел, съдържащ данните.
Например, представете си, че е получена заявка за избор на редове, съдържащи стойност на ключ 82. Подсистемата за заявки започва да работи от основния възел, който препраща към подходящ междинен възел, в нашия случай 1-100. От междинния възел 1-100 има преход към възел 51-100, а оттам към крайния възел 76-100. Ако това е клъстериран индекс, тогава листът на възела съдържа данните от реда, свързан с ключа, равен на 82. Ако това е неклъстериран индекс, тогава листът на индекса съдържа указател към клъстерираната таблица или конкретен ред в купчината.
Как един индекс може дори да подобри производителността на заявките, ако трябва да преминете през всички тези възли на индекса?
Първо, индексите не винаги подобряват производителността. Твърде много неправилно създадени индекси превръщат системата в блато и влошават производителността на заявките. По-точно е да се каже, че ако индексите се прилагат внимателно, те могат да осигурят значителни печалби в производителността.
Помислете за огромна книга, посветена на настройката на производителността SQL сървър(хартиен вариант, не електронен). Представете си, че искате да намерите информация за конфигурирането на Resource Governor. Можете да плъзгате с пръст страница по страница през цялата книга или да отворите съдържанието и да разберете точния номер на страницата с информацията, която търсите (при условие, че книгата е правилно индексирана и съдържанието има правилните индекси). Това със сигурност ще ви спести значително време, въпреки че първо трябва да получите достъп до напълно различна структура (индекса), за да получите необходимата информация от основната структура (книгата).
Като книжен индекс, индекс в SQL сървърви позволява да изпълнявате прецизни заявки за данните, от които се нуждаете, вместо да сканирате напълно всички данни, съдържащи се в таблица. За малки таблици пълното сканиране обикновено не е проблем, но големите таблици заемат много страници с данни, което може да доведе до значително време за изпълнение на заявка, освен ако не съществува индекс, който да позволи на машината за заявки незабавно да получи правилното местоположение на данните. Представете си да се изгубите на кръстовище на много нива пред голям метрополис без карта и ще схванете идеята.
Ако индексите са толкова страхотни, защо просто не създадете по един за всяка колона?
Никое добро дело не трябва да остава ненаказано. Поне така е при индексите. Разбира се, индексите работят чудесно, стига да изпълнявате заявки за извличане на оператори ИЗБЕРЕТЕ, но веднага щом започнат чести обаждания към операторите ВМЪКНЕТЕ, АКТУАЛИЗИРАНЕИ ИЗТРИЙ, така че пейзажът се променя много бързо.
Когато инициирате заявка за данни от оператора ИЗБЕРЕТЕ, машината за заявки намира индекса, преминава през неговата дървовидна структура и открива данните, които търси. Какво може да бъде по-просто? Но нещата се променят, ако инициирате изявление за промяна като АКТУАЛИЗИРАНЕ. Да, за първата част от оператора, машината за заявки може отново да използва индекса, за да намери реда, който се променя - това е добра новина. И ако има проста промяна в данните в ред, която не засяга промените в ключови колони, тогава процесът на промяна ще бъде напълно безболезнен. Но какво ще стане, ако промяната доведе до разделяне на страниците, съдържащи данните, или стойността на ключова колона се промени, причинявайки преместването й в друг индексен възел - това ще доведе до евентуална нужда от реорганизация на индекса, засягаща всички свързани индекси и операции , което води до широко разпространен спад в производителността.
Подобни процеси се случват при обаждане на оператор ИЗТРИЙ. Индексът може да помогне за намиране на данните, които се изтриват, но изтриването на самите данни може да доведе до пренареждане на страницата. Относно оператора ВМЪКНЕТЕ, основният враг на всички индекси: започвате да добавяте голямо количество данни, което води до промени в индексите и тяхната реорганизация и всички страдат.
Така че помислете за типовете заявки към вашата база данни, когато мислите какъв тип индекси и колко да създадете. Повече не означава по-добро. Преди да добавите нов индекс към таблица, помислете за цената не само на основните заявки, но и за количеството консумирано дисково пространство, разходите за поддържане на функционалност и индекси, което може да доведе до ефект на доминото върху други операции. Вашата стратегия за проектиране на индекс е един от най-важните аспекти на вашето внедряване и трябва да включва много съображения, от размера на индекса, броя на уникалните стойности до вида на заявките, които индексът ще поддържа.
Необходимо ли е да се създаде клъстерен индекс на колона с първичен ключ?
Можете да създадете клъстерен индекс на всяка колона, която отговаря на необходимите условия. Вярно е, че клъстериран индекс и ограничение за първичен ключ са създадени един за друг и са съвпадение, направено на небето, така че разберете факта, че когато създавате първичен ключ, автоматично ще бъде създаден клъстерен индекс, ако такъв не е бил създаден преди. Въпреки това може да решите, че клъстерният индекс би се представил по-добре другаде и често решението ви ще бъде оправдано.
Основната цел на клъстерирания индекс е да сортира всички редове във вашата таблица въз основа на ключовата колона, посочена при дефинирането на индекса. Това осигурява бързо търсене и лесен достъп до данни от таблици.
Първичният ключ на таблицата може да бъде добър избор, тъй като той уникално идентифицира всеки ред в таблиците, без да се налага да добавяте допълнителни данни. В някои случаи най-добрият избор ще бъде сурогатен първичен ключ, който е не само уникален, но и малък по размер и чиито стойности се увеличават последователно, което прави неклъстерираните индекси, базирани на тази стойност, по-ефективни. Оптимизаторът на заявките също харесва тази комбинация от клъстерен индекс и първичен ключ, защото свързването на таблици е по-бързо от свързването по друг начин, който не използва първичен ключ и свързания с него клъстерен индекс. Както казах, това е съвпадение, направено на небето.
Накрая обаче си струва да се отбележи, че при създаването на клъстериран индекс има няколко аспекта, които трябва да се вземат предвид: колко не-клъстерирани индекса ще се базират на него, колко често ще се променя стойността на колоната на ключовия индекс и колко голяма. Когато стойностите в колоните на клъстериран индекс се променят или индексът не работи според очакванията, тогава всички други индекси в таблицата могат да бъдат засегнати. Клъстерираният индекс трябва да се основава на най-постоянната колона, чиито стойности се увеличават в определен ред, но не се променят по случаен начин. Индексът трябва да поддържа заявки към най-често достъпваните данни на таблицата, така че заявките да се възползват напълно от факта, че данните са сортирани и достъпни в основните възли, листата на индекса. Ако първичният ключ отговаря на този сценарий, използвайте го. Ако не, тогава изберете различен набор от колони.
Ами ако индексирате изглед, той все още ли е изглед?
Изгледът е виртуална таблица, която генерира данни от една или повече таблици. По същество това е наименувана заявка, която извлича данни от основните таблици, когато правите заявка за този изглед. Можете да подобрите производителността на заявката, като създадете клъстериран индекс и неклъстерирани индекси в този изглед, подобно на това как създавате индекси на таблица, но основното предупреждение е, че първо създавате клъстерен индекс и след това можете да създадете неклъстерен.
Когато се създаде индексиран изглед (материализиран изглед), тогава самата дефиниция на изглед остава отделен обект. В крайна сметка това е само твърдо кодиран оператор ИЗБЕРЕТЕ, съхранявани в базата данни. Но индексът е съвсем различна история. Когато създадете клъстерен или неклъстериран индекс на доставчик, данните се записват физически на диск, точно като обикновен индекс. Освен това, когато данните се променят в базовите таблици, индексът на изгледа се променя автоматично (това означава, че може да искате да избегнете индексиране на изгледи на таблици, които се променят често). Така или иначе изгледът си остава изглед - поглед към таблиците, но изпълняван в момента, със съответстващи му индекси.
Преди да можете да създадете индекс на изглед, той трябва да отговаря на няколко ограничения. Например един изглед може да препраща само към базови таблици, но не и към други изгледи и тези таблици трябва да са в същата база данни. Всъщност има много други ограничения, така че не забравяйте да проверите документацията за SQL сървърза всички мръсни подробности.
Защо да използвате покриващ индекс вместо съставен индекс?
Първо, нека се уверим, че разбираме разликата между двете. Съставният индекс е просто обикновен индекс, който съдържа повече от една колона. Множество ключови колони могат да се използват, за да се гарантира, че всеки ред в таблица е уникален, или може да имате множество колони, за да сте сигурни, че първичният ключ е уникален, или може да се опитвате да оптимизирате изпълнението на често извиквани заявки за множество колони. Като цяло обаче, колкото повече ключови колони съдържа един индекс, толкова по-малко ефективен ще бъде индексът, което означава, че съставните индекси трябва да се използват разумно.
Както беше посочено, една заявка може да бъде от голяма полза, ако всички необходими данни са незабавно разположени в листата на индекса, точно както самия индекс. Това не е проблем за клъстерен индекс, защото всички данни вече са там (ето защо е толкова важно да обмислите внимателно, когато създавате клъстерен индекс). Но неклъстъриран индекс на листа съдържа само ключови колони. За достъп до всички други данни, оптимизаторът на заявки изисква допълнителни стъпки, които могат да добавят значителни разходи за изпълнение на вашите заявки.
Тук на помощ идва покривният индекс. Когато дефинирате неклъстъриран индекс, можете да посочите допълнителни колони към вашите ключови колони. Например, да кажем, че вашето приложение често прави заявки за данни от колони OrderIDИ Дата на поръчкана масата Продажби:
Можете да създадете съставен неклъстъриран индекс и в двете колони, но колоната OrderDate само ще добави допълнителни разходи за поддръжка на индекса, без да служи като особено полезна ключова колона. Най-доброто решение би било да се създаде покриващ индекс на ключовата колона OrderIDи допълнително включена колона Дата на поръчка:
CREATE NONCLUSTERED INDEX ix_orderid ON dbo.Sales(OrderID) INCLUDE (OrderDate);По този начин се избягват недостатъците на индексирането на излишни колони, като същевременно се запазват предимствата на съхраняването на данни в листа при изпълнение на заявки. Включената колона не е част от ключа, но данните се съхраняват на листовия възел, индексния лист. Това може да подобри производителността на заявките без допълнителни разходи. В допълнение, колоните, включени в покриващия индекс, са предмет на по-малко ограничения от ключовите колони на индекса.
Има ли значение броят на дубликатите в ключова колона?
Когато създавате индекс, трябва да опитате да намалите броя на дубликатите във вашите ключови колони. Или по-точно: опитайте се да поддържате честотата на повторение възможно най-ниска.
Ако работите със съставен индекс, тогава дублирането се прилага към всички ключови колони като цяло. Една колона може да съдържа много дублиращи се стойности, но трябва да има минимално повторение сред всички индексни колони. Например създавате съставен неклъстериран индекс върху колони Първо имеИ Фамилия, можете да имате много стойности на John Doe и много стойности на Doe, но искате да имате възможно най-малко стойности на John Doe или за предпочитане само една стойност на John Doe.
Коефициентът на уникалност на стойностите на ключова колона се нарича селективност на индекса. Колкото повече уникални стойности има, толкова по-висока е селективността: уникалният индекс има възможно най-голямата селективност. Машината за заявки наистина харесва колони с високи стойности на селективност, особено ако тези колони са включени в клаузите WHERE на вашите най-често изпълнявани заявки. Колкото по-селективен е индексът, толкова по-бързо машината за заявки може да намали размера на получения набор от данни. Недостатъкът, разбира се, е, че колони с относително малко уникални стойности рядко ще бъдат добри кандидати за индексиране.
Възможно ли е да се създаде негрупиран индекс само върху конкретно подмножество от данни на ключова колона?
По подразбиране неклъстърният индекс съдържа един ред за всеки ред в таблицата. Разбира се, можете да кажете същото за клъстерен индекс, ако приемем, че такъв индекс е таблица. Но когато става въпрос за неклъстъриран индекс, връзката едно към едно е важна концепция, защото, започвайки с версия SQL Server 2008, имате възможност да създадете филтрируем индекс, който ограничава редовете, включени в него. Филтрираният индекс може да подобри производителността на заявките, защото... той е по-малък по размер и съдържа филтрирани, по-точни статистики от всички таблични – това води до създаването на подобрени планове за изпълнение. Филтрираният индекс също така изисква по-малко място за съхранение и по-ниски разходи за поддръжка. Индексът се актуализира само когато данните, които отговарят на филтъра, се променят.
Освен това лесно се създава филтрируем индекс. В оператора СЪЗДАВАНЕ НА ИНДЕКСпросто трябва да посочите в КЪДЕТОсъстояние на филтъра. Например, можете да филтрирате всички редове, съдържащи NULL от индекса, както е показано в кода:
Всъщност можем да филтрираме всички данни, които не са важни при критични заявки. Но внимавайте, защото... SQL сървърналага няколко ограничения върху индексите, които могат да се филтрират, като например невъзможността да се създаде индекс, който може да се филтрира върху изглед, така че прочетете документацията внимателно.
Възможно е също така да постигнете подобни резултати чрез създаване на индексиран изглед. Въпреки това, филтрираният индекс има няколко предимства, като например способността да намалите разходите за поддръжка и да подобрите качеството на вашите планове за изпълнение. Филтрираните индекси също могат да бъдат възстановени онлайн. Опитайте това с индексиран изглед.
6. Индекси и оптимизиране на производителността
Индекси в бази данни: предназначение, влияние върху производителността, принципи на създаване на индекси
6.1 За какво са индексите?
Индексите са специални структури в базите данни, които ви позволяват да ускорите търсенето и сортирането по конкретно поле или набор от полета в таблица, а също така се използват за гарантиране на уникалността на данните. Най-лесният начин за сравняване на индексите е с индексите в книгите. Ако няма индекс, тогава ще трябва да прегледаме цялата книга, за да намерим правилното място, но с индекс същото действие може да се извърши много по-бързо.
Обикновено, колкото повече индекси, толкова по-добра е производителността на заявките към базата данни. Въпреки това, ако броят на индексите се увеличи прекомерно, производителността на операциите за модифициране на данни (вмъкване/промяна/изтриване) намалява и размерът на базата данни се увеличава, така че добавянето на индекси трябва да се третира с повишено внимание.
Някои общи принципи, свързани със създаването на индекси:
· трябва да се създадат индекси за колони, които се използват в съединения, които често се използват за операции за търсене и сортиране. Моля, имайте предвид, че индексите винаги се създават автоматично за колони, които са предмет на ограничение на първичен ключ. Най-често те се създават за колони с външен ключ (в Access - автоматично);
· трябва автоматично да се създава индекс за колони, които са предмет на ограничение за уникалност;
· Най-добре е да създадете индекси за тези полета, в които има минимален брой повтарящи се стойности и данните са равномерно разпределени. Oracle има специални битови индекси за колони с голям брой дублиращи се стойности; SQL Server и Access не предоставят този тип индекс;
· ако търсенето се извършва постоянно върху определен набор от колони (едновременно), тогава в този случай може да има смисъл да се създаде съставен индекс (само в SQL Server) - един индекс за група колони;
· Когато се правят промени в таблици, индексите, насложени върху тази таблица, се променят автоматично. В резултат на това индексът може да бъде силно фрагментиран, което оказва влияние върху производителността. Трябва периодично да проверявате степента на фрагментация на индекса и да ги дефрагментирате. Когато зареждате голямо количество данни, понякога има смисъл първо да изтриете всички индекси и да ги създадете отново, след като операцията приключи;
· могат да се създават индекси не само за таблици, но и за изгледи (само в SQL Server). Предимства - възможността за изчисляване на полета не по време на заявката, а в момента, в който се появят нови стойности в таблиците.
Тази статия обсъжда индексите и тяхната роля за оптимизиране на времето за изпълнение на заявка. Първата част на статията обсъжда различните форми на индекси и как да ги съхранявате. След това разглеждаме трите основни оператора на Transact-SQL, използвани за работа с индекси: CREATE INDEX, ALTER INDEX и DROP INDEX. След това се разглежда фрагментацията на индексите за неговото въздействие върху производителността на системата. След това предоставя някои общи насоки за създаване на индекси и описва няколко специални типа индекси.
Главна информация
Системите за бази данни обикновено използват индекси, за да осигурят бърз достъп до релационни данни. Индексът е отделна физическа структура от данни, която позволява бърз достъп до един или повече редове от данни. По този начин правилното настройване на индексите е ключов аспект за подобряване на производителността на заявките.
Индексът на базата данни е в много отношения подобен на индекс (азбучен индекс) на книга. Когато трябва бързо да намерим тема в книга, първо гледаме в индекса на кои страници от книгата се обсъжда тази тема и веднага след това отваряме желаната страница. По същия начин, когато търси конкретен ред в таблица, Database Engine осъществява достъп до индекса, за да намери физическото му местоположение.
Но има две съществени разлики между индекс на книги и индекс на база данни:
Читателят на книгата има възможност сам да реши дали да използва индекса във всеки конкретен случай или не. Потребителят на базата данни няма тази възможност и това решение се взема вместо него от системен компонент, т.нар оптимизатор на заявки. (Потребителят може да манипулира използването на индекси чрез съвети за индекси, но тези съвети се препоръчват за използване само в ограничен брой специални случаи.)
Индексът за конкретна работна книга се създава заедно с работната книга, след което вече не се променя. Това означава, че индексът за определена тема винаги ще сочи към същия номер на страница. Обратно, индексът на базата данни може да се промени всеки път, когато се променят съответните данни.
Ако дадена таблица няма подходящ индекс, системата използва метод за сканиране на таблица, за да извлече редове. Изразяване сканиране на масаозначава, че системата последователно извлича и проверява всеки ред от таблицата (от първия до последния) и поставя реда в набора от резултати, ако условието за търсене в клаузата WHERE е изпълнено за него. По този начин всички редове се извличат според тяхното физическо местоположение в паметта. Този метод е по-малко ефективен от достъпа с помощта на индекси, както е обяснено по-долу.
Индексите се съхраняват в допълнителни структури на бази данни, наречени индексни страници. За всеки индексиран ред има запис в индекса, който се записва на индексната страница. Всеки индексен елемент се състои от индексен ключ и индекс. Ето защо индексният елемент е значително по-къс от реда на таблицата, към който сочи. Поради тази причина броят на индексните елементи във всяка индексна страница е много по-голям от броя на редовете в страницата с данни.
Това свойство на индексите е много важно, тъй като броят на I/O операциите, необходими за преминаване през индексните страници, е значително по-малък от броя на I/O операциите, необходими за преминаване през съответните страници с данни. С други думи, сканирането на таблица вероятно ще изисква много повече I/O операции, отколкото сканирането на индекса на таблицата.
Индексите на Database Engine се създават с помощта на B+ дървовидна структура от данни. B+ дърво има дървовидна структура, в която всички най-долни възли са на същия брой нива от върха (основния възел) на дървото. Това свойство се поддържа дори когато данните се добавят или премахват от индексираната колона.
Фигурата по-долу показва B+ дървовидна структура за таблицата Employee и директен достъп до реда в тази таблица със стойност 25348 за колоната Id. (Предполагаме, че таблицата Employee е индексирана от колоната Id.) Можете също така да видите на тази фигура, че B+ дърво се състои от основен възел, възли на дърво и нула или повече междинни възли:
Можете да търсите в това дърво за стойността 25348, както следва. Започвайки от корена на дървото, той търси най-малката стойност на ключ, по-голяма или равна на желаната стойност. Така в основния възел тази стойност ще бъде 29346, така че се прави преход към междинния възел, свързан с тази стойност. В този възел стойността 28559 отговаря на посочените изисквания, в резултат на което се прави преход към дървовидния възел, свързан с тази стойност. Този възел съдържа желаната стойност 25348. След като определим необходимия индекс, можем да извлечем неговия ред от таблицата с данни, като използваме подходящите указатели. (Алтернативен еквивалентен подход би бил да се търси стойност, по-малка или равна на индекса.)
Индексираното търсене обикновено е предпочитаният метод за търсене в таблици с голям брой редове поради очевидните му предимства. Използвайки индексирано търсене, можем да намерим всеки ред в таблица за много кратко време, използвайки само няколко I/O операции. И последователното търсене (т.е. сканиране на таблица от първия ред до последния) отнема повече време, колкото по-далеч е необходимият ред.
В следващите раздели ще разгледаме двата съществуващи типа индекси, клъстерирани и неклъстерирани, и ще научим как да създаваме индекси.
Клъстерни индекси
Клъстерен индексопределя физическия ред на данните в таблица. Database Engine ви позволява да създадете само един клъстериран индекс за таблица, тъй като Редовете на една таблица не могат да бъдат физически подредени по повече от един начин. Търсене с помощта на клъстериран индекс се извършва от коренния възел на B+ дърво към възли в дървото, които са свързани заедно в двойно свързан списък, наречен страница верига.
Важно свойство на клъстерен индекс е, че неговите дървовидни възли съдържат страници с данни. (Всички други нива на клъстерирани индексни възли съдържат индексни страници.) Таблица, която има дефиниран клъстерен индекс (изрично или косвено), се нарича клъстерна таблица. B+ дървовидната структура на клъстерен индекс е показана на фигурата по-долу:

Клъстъриран индекс се създава по подразбиране за всяка таблица, която има първичен ключ, дефиниран от ограничение за първичен ключ. Освен това всеки клъстерен индекс е уникален по подразбиране, т.е. В колона, която има дефиниран клъстерен индекс, всяка стойност на данните може да се появи само веднъж. Ако се създаде групиран индекс върху колона, която съдържа дублирани стойности, системата от бази данни налага недвусмисленост чрез добавяне на четирибайтов идентификатор към редове, които съдържат дублирани стойности.
Клъстерираните индекси осигуряват много бърз достъп до данни, когато дадена заявка търси диапазон от стойности.
Неклъстърирани индекси
Структурата на неклъстериран индекс е точно същата като на клъстерен индекс, но с две важни разлики:
неклъстъриран индекс не променя физическото подреждане на редовете на таблицата;
Страниците с неклъстерирани индексни възли се състоят от индексни ключове и отметки.
Ако дефинирате един или повече неклъстерирани индекси в таблица, физическият ред на редовете на таблицата няма да бъде променен. За всеки неклъстъриран индекс, Database Engine създава допълнителна структура на индекс, която се съхранява в индексните страници. B+ дървовидната структура на неклъстъриран индекс е показана на фигурата по-долу:

Отметка в неклъстъриран индекс показва къде се намира редът, съответстващ на ключа на индекса. Компонентът на показалеца на индексен ключ може да бъде от два типа в зависимост от това дали таблицата е клъстерна таблица или купчина. (В терминологията на SQL Server купчината е таблица без клъстерен индекс.) Ако съществува клъстерен индекс, разделът за неклъстериран индекс показва B+ дървото на клъстерирания индекс на таблицата. Ако таблицата няма клъстериран индекс, маркерът е идентичен идентификатор на ред (RID - идентификатор на ред), състоящ се от три части: адреса на файла, в който се съхранява таблицата, адреса на физическия блок (страница), в който се съхранява редът, и отместването на реда в страницата.
Както бе споменато по-рано, търсенето на данни с помощта на неклъстериран индекс може да се извърши по два различни начина в зависимост от типа на таблицата:
heap - преминава през структурата за търсене на неклъстъриран индекс, след което редът се извлича с помощта на идентификатора на реда;
клъстерирана таблица - обхождане на търсене на структура на неклъстерен индекс, последвано от обхождане на съответния клъстерен индекс.
И в двата случая обемът I/O операции е доста голям, така че трябва да проектирате неклъстъриран индекс с повишено внимание и да го използвате само ако сте уверени, че използването му значително ще подобри производителността.
Transact-SQL език и индекси
Сега, след като сме запознати с физическата структура на индексите, в този раздел ще разгледаме как да създаваме, модифицираме и изтриваме индекси, както и как да получаваме информация за фрагментиране на индекси и да редактираме информация за индекси. Всичко това ще ни подготви за последващото обсъждане на използването на индекси за подобряване на производителността на системата.
Създаване на индекси
Индекс на таблица се създава с помощта на израза СЪЗДАВАНЕ НА ИНДЕКС. Тази инструкция има следния синтаксис:
CREATE INDEX index_name ON table_name (колона1 ,...) [ INCLUDE (колона_име [ ,... ]) ] [[, ] PAD_INDEX = (ON | OFF)] [[, ] DROP_EXISTING = (ON | OFF)] [[ , ] SORT_IN_TEMPDB = (ON | OFF)] [[, ] IGNORE_DUP_KEY = (ON | OFF)] [[, ] ALLOW_ROW_LOCKS = (ON | OFF)] [[, ] ALLOW_PAGE_LOCKS = (ON | OFF)] [[, ] STATISTICS_NORECOMPUTE = (ВКЛ. | ИЗКЛ.)] [[, ] ОНЛАЙН = (ВКЛ. | ИЗКЛ.)]] Синтактични конвенции
Параметърът index_name указва името на индекса, който ще бъде създаден. Индекс може да бъде създаден върху една или повече колони на една таблица, идентифицирана от параметъра table_name. Колоната, върху която се създава индексът, се определя от параметъра column1. Числовият суфикс на този параметър показва, че индексът може да бъде създаден върху множество колони на таблицата. Database Engine също поддържа създаване на индекси на изгледи.
Можете да индексирате всяка колона на таблицата. Това означава, че колони, съдържащи стойности на тип данни VARBINARY(max), BIGINT и SQL_VARIANT, също могат да бъдат индексирани.
Индексът може да бъде прост или съставен. Прост индекс се създава в една колона, докато съставен индекс се създава в множество колони. Съставният индекс има определени ограничения, свързани с неговия размер и брой колони. Един индекс може да има максимум 900 байта и максимум 16 колони.
УНИКАЛЕН параметъруказва, че индексираната колона може да съдържа само стойности с една стойност (т.е. неповтарящи се). В съставен индекс с една стойност уникалното трябва да бъде комбинацията от стойностите на всички колони на всеки ред. Ако ключовата дума UNIQUE не е посочена, тогава се допускат дублиращи се стойности в индексираната колона(и).
CLUSTERED параметъруказва групиран индекс и НЕКЛУСТРИРАН параметър(по подразбиране) указва, че индексът не променя реда на редовете в таблицата. Database Engine позволява максимум 249 неклъстерирани индекса в таблица.
Database Engine е подобрен, за да поддържа индекси с низходящ ред на стойностите на колоните. Параметърът ASC след името на колоната указва, че индексът е създаден с възходящ ред на стойностите на колоната, а параметърът DESC указва низходящ ред на стойностите на колоната на индекса. Това осигурява по-голяма гъвкавост при използването на индекса. С низходящ ред трябва да създадете съставни индекси на колони, чиито стойности са подредени в противоположни посоки.
INCLUDE параметърПозволява ви да посочите неключови колони, които се добавят към страниците на възлите на неклъстъриран индекс. Имената на колони в списъка INCLUDE не трябва да се повтарят и една колона не може да се използва едновременно като ключова и неключова колона.
За да разберете наистина полезността на параметъра INCLUDE, трябва да разберете какво представлява той покривен индекс. Ако всички колони на заявка са включени в индекса, можете да получите значителни подобрения на производителността, защото Оптимизаторът на заявки може да намери всички стойности на колони в индексните страници, без да има достъп до данните в таблицата. Тази възможност се нарича покривен индекс или покриваща заявка. Следователно включването на допълнителни неключови колони в страниците на неклъстърирани индексни възли ще ви позволи да получите повече заявки за покритие и значително да подобрите тяхната производителност.
Параметър FILLFACTORуказва процента на запълване на всяка индексна страница към момента на създаване на индекса. Стойността на параметъра FILLFACTOR може да бъде зададена в диапазона от 1 до 100. При стойност n=100 всяка индексна страница се запълва на 100%, т.е. съществуваща възлова страница, както и невъзлова страница няма да имат свободно място за вмъкване на нови редове. Поради това се препоръчва тази стойност да се използва само за статични таблици. (Стойността по подразбиране, n=0, означава, че страниците на индексния възел са пълни и всяка от междинните страници съдържа свободно място за един запис.)
Ако параметърът FILLFACTOR е зададен на стойности между 1 и 99, страниците на възлите на структурата на индекса, която се създава, ще съдържат свободно пространство. Колкото по-голяма е стойността на n, толкова по-малко свободно пространство има в страниците на индексния възел. Например, с n=60, всяка страница с индексен възел ще има 40% свободно пространство за бъдещи вмъквания на индексни редове. (Индексните редове се вмъкват с помощта на оператор INSERT или UPDATE.) Следователно стойност от n=60 би била разумна за таблици, чиито данни се променят доста често. Със стойности на FILLFACTOR между 1 и 99, междинните индексни страници съдържат свободно място за един запис всяка.
След като се създаде индекс, стойността FILLFACTOR не се поддържа по време на употреба. С други думи, той показва само количеството място, запазено с наличните данни, когато задавате процента за свободно пространство. За да възстановите параметъра FILLFACTOR до първоначалната му стойност, използвайте оператора ALTER INDEX.
Параметър PAD_INDEXе тясно свързан с параметъра FILLFACTOR. Параметърът FILLFACTOR основно определя количеството свободно пространство като процент от общия размер на страницата на индексните възли. А параметърът PAD_INDEX указва, че стойността на параметъра FILLFACTOR се прилага както към страниците на индекса, така и към страниците с данни в индекса.
DROP_EXISTING параметърПозволява ви да подобрите производителността, когато възпроизвеждате клъстерен индекс върху таблица, която също има неклъстерен индекс. За повече информация вижте раздела „Преизграждане на индекса“ по-долу.
SORT_IN_TEMPDB параметъризползвани за поставяне на данни от междинни операции за сортиране, използвани при създаване на индекс в системната база данни tempdb. Това може да подобри производителността, ако tempdb се намира на различен диск от данните.
Параметър IGNORE_DUP_KEYПозволява на системата да игнорира опит за вмъкване на дублиращи се стойности в индексирани колони. Тази опция трябва да се използва само за избягване на прекъсване на дълготрайна транзакция, когато оператор INSERT вмъква дублиращи се данни в индексирана колона. Когато тази опция е активирана, когато оператор INSERT се опитва да вмъкне редове в таблица, които нарушават уникалността на индекса, системата от бази данни просто издава предупреждение, вместо да срине целия оператор. В този случай Database Engine не вмъква редове с дублиращи се ключови стойности, а просто ги игнорира и добавя правилните редове. Ако този параметър не е зададен, тогава изпълнението на цялата инструкция ще приключи необичайно.
Кога параметър ALLOW_ROW_LOCKSактивирано (настроено на включено), системата прилага заключване на редове. По същия начин, когато се активира параметър ALLOW_PAGE_LOCKS, системата прилага заключване на страници по време на едновременен достъп. Параметър STATISTICS_NORECOMPUTEопределя състоянието на автоматично преизчисляване на статистиката за посочения индекс.
Активиран ОНЛАЙН параметърви позволява да създавате, пресъздавате и изтривате индекс в диалогов режим. Тази опция ви позволява едновременно да променяте данните на основната таблица или клъстерния индекс и всички свързани индекси, докато променяте индекса. Например, докато клъстерен индекс се създава отново, можете да продължите да актуализирате неговите данни и да изпълнявате заявки за тези данни.
Параметър ВКЛсъздава посочения индекс или в файловата група по подразбиране (стойност по подразбиране), или в указаната файлова група (стойност на file_group).
Примерът по-долу показва как да създадете негрупиран индекс в колоната Id на таблицата Employee:
ИЗПОЛЗВАЙТЕ SampleDb; CREATE INDEX ix_empid ON Employee(Id);
Създаването на съставен индекс с една стойност е показано в примера по-долу:
ИЗПОЛЗВАЙТЕ SampleDb; CREATE UNIQUE INDEX ix_empid_prnu ON Works_on (EmpId, ProjectNumber) С FILLFACTOR= 80;
В този пример стойностите във всяка колона трябва да са едноцифрени. Когато се създаде индекс, 80% от пространството на всяка страница на индексен възел се запълва.
Не можете да създадете уникален индекс на колона, ако колоната съдържа дублиращи се стойности. Такъв индекс може да бъде създаден само ако всяка стойност (включително NULL стойности) се появява точно веднъж в колоната. Освен това всеки опит за вмъкване или промяна на съществуваща стойност на данни в колона, включена в съществуващ уникален индекс, ще бъде отхвърлен от системата, ако стойността се дублира.
Получаване на информация за фрагментацията на индекса
По време на живота на индекса той може да стане фрагментиран, което прави процеса на съхраняване на данни в страниците на индекса неефективен. Има два вида фрагментация на индекса: вътрешна фрагментация и външна фрагментация. Вътрешната фрагментация определя количеството данни, съхранявани във всяка страница, докато външната фрагментация възниква, когато страниците не са в логически ред.
За да получите информация за вътрешната фрагментация на индекса, се извиква динамичен изглед за управление на DMV sys.dm_db_index_physical_stats. Този DMV връща информация за обема и фрагментацията на данните и индексите на посочената страница. За всяка страница се връща по един ред за всяко ниво на B+ дървото. С помощта на този DMV можете да получите информация за степента на фрагментация на редовете в страниците с данни, въз основа на която можете да решите дали да реорганизирате данните.
Използването на изгледа sys.dm_db_index_physical_stats е показано в примера по-долу. (Преди да стартирате пакетния пример, трябва да премахнете всички съществуващи индекси в таблицата Works_on. За да премахнете индекси, използвайте оператора DROP INDEX, който е показан по-късно.)
ИЗПОЛЗВАЙТЕ SampleDb; DECLARE @dbId INT; DECLARE @tabId INT; DECLARE @indId INT; SET @dbId = DB_ID("SampleDb"); SET @tabId = OBJECT_ID("Служител"); ИЗБЕРЕТЕ avg_fragmentation_in_percent, avg_page_space_used_in_percent FROM sys.dm_db_index_physical_stats (@dbId, @tabId, NULL, NULL, NULL);
Както можете да видите от примера, изгледът sys.dm_db_index_physical_stats има пет параметъра. Първите три параметъра дефинират идентификаторите съответно на текущата база данни, таблица и индекс. Четвъртият параметър определя ID на дяла, а последният параметър определя нивото на сканиране, използвано за получаване на статистическа информация. (Стойността по подразбиране за конкретен параметър може да бъде зададена с помощта на стойността NULL.)
Най-важните от колоните в този изглед са колоните avg_fragmentation_in_percent и avg_page_space_used_in_percent. Първият показва средното ниво на фрагментация като процент, а вторият определя количеството заето пространство като процент.
Редактиране на индексна информация
След като се запознаете с информацията за фрагментиране на индекса, както беше обсъдено в предишния раздел, можете да редактирате тази и друга информация за индекса, като използвате следните системни инструменти:
изгледи на директория sys.indexes;
каталожни изгледи sys.index_columns;
системна процедура sp_helpindex;
функции свойства на обекта;
Среда за управление на Management Studio за SQL Server;
Изглед на динамично управление на DMV sys.dm_db_index_usage_stats;
Изглед на динамично управление на DMV sys.dm_db_missing_index_details.
Изглед на каталог sys.indexesсъдържа ред за всеки индекс и ред за всяка таблица без клъстерен индекс. Най-важните колони на този изглед на каталог са колоните object_id, name и index_id. Колоната object_id съдържа името на обекта на базата данни, който притежава индекса, а колоните name и index_id съдържат съответно името и ID на този индекс.
Изглед на каталог sys.index_columnsсъдържа ред за всяка колона, която е част от индекса или купчината. Тази информация може да се използва заедно с информация, получена чрез каталожния изглед на sys.indexes, за да се получи допълнителна информация за свойствата на посочения индекс.
Системна процедура sp_helpindexвръща информация за индексите на таблици, както и статистическа информация за колони. Тази процедура има следния синтаксис:
sp_helpindex [@db_object = ] "име"
Тук променливата @db_object представлява името на таблицата.
Във връзка с индексите, функция свойство на обектаима две свойства: IsIndexed и IsIndexable. Първото свойство предоставя информация дали таблицата или изгледът има индекс, а второто свойство показва дали таблицата или изгледът може да се индексира.
За да редактирате съществуваща индексна информация с помощта на SQL Server Management Studio, изберете желаната база данни в папката Databases, разгънете възела Tables и в този възел разгънете желаната таблица и нейната папка Indexes. Папката Indexes на таблицата ще покаже списък на всички съществуващи индекси за тази таблица. Двойното щракване върху индекс ще отвори диалоговия прозорец Свойства на индекса със свойствата на този индекс. (Можете също да създадете нов индекс или да изтриете съществуващ с помощта на Management Studio.)
производителност sys.dm_db_index_usage_statsвръща брой на различните типове операции с индекси и последния път, когато всеки тип операция е извършена. Всяка отделна операция за търсене, търсене или актуализиране на определен индекс в една заявка се счита за използване на индекса и увеличава съответния брояч в този DMV с единица. По този начин можете да получите обща информация за това колко често се използва даден индекс, така че да можете да го използвате, за да определите кои индекси се използват повече и кои се използват по-малко.
производителност sys.dm_db_missing_index_detailsВръща подробна информация за колоните на таблицата, за които няма индекси. Най-важните колони на този DMV са колоните index_handle и object_id. Стойността в първата колона идентифицира конкретния липсващ индекс, а стойността във втората колона идентифицира таблицата, в която индексът липсва.
Промяна на индексите
Database Engine е една от малкото системи за бази данни, които поддържат твърдението ПРОМЕНЯ ИНДЕКС. Този оператор може да се използва за извършване на операции по поддръжка на индекс. Синтаксисът на оператора ALTER INDEX е много подобен на синтаксиса на оператора CREATE INDEX. С други думи, този оператор ви позволява да промените стойностите на параметрите ALLOW_ROW_LOCKS, ALLOW_PAGE_LOCKS, IGNORE_DUP_KEY и STATISTICS_NORECOMPUTE, които бяха описани по-рано в оператора CREATE INDEX.
В допълнение към горните опции операторът ALTER INDEX поддържа три други опции:
Параметър REBUILD, използван за пресъздаване на индекса;
Параметър REORGANIZE, използвани за реорганизиране на страниците на индексни възли;
DISABLE параметър, използван за деактивиране на индекса. Тези три опции се обсъждат в следващите подраздели.
Възстановяване на индекса
Всяка промяна на данни чрез изрази INSERT, UPDATE или DELETE може да доведе до фрагментиране на данните. Ако тези данни са индексирани, тогава е възможно и фрагментирането на индекса, като информацията за индекса е разпръсната в различни физически страници. В резултат на фрагментирането на данните на индекса, Database Engine може да бъде принуден да извърши допълнителни операции за четене на данни, което намалява цялостната производителност на системата. В този случай трябва да ПЪРВАТЕ всички фрагментирани индекси.
Това може да стане по два начина:
чрез параметъра REBUILD на оператора ALTER INDEX;
чрез параметъра DROP_EXISTING на оператора CREATE INDEX.
Параметърът REBUILD се използва за повторно изграждане на индекси. Ако укажете ВСИЧКИ вместо името на индекса за този параметър, всички индекси в таблицата ще бъдат създадени отново. (Позволявайки динамично пресъздаване на индекси, няма да се налага да ги премахвате и създавате отново.)
Опцията DROP_EXISTING на оператора CREATE INDEX може да подобри производителността при повторно създаване на клъстерен индекс на таблица, която също има неклъстерирани индекси. Той указва, че съществуващ клъстерен или неклъстерен индекс трябва да бъде премахнат и посоченият индекс трябва да бъде създаден отново. Както бе споменато по-рано, всеки неклъстериран индекс на клъстерирана таблица съдържа в своите дървовидни възли съответните стойности на клъстерирания индекс на таблицата. Поради тази причина, когато пуснете клъстерен индекс върху таблица, трябва да създадете отново всички нейни неклъстерирани индекси. Използването на параметъра DROP_EXISTING избягва повторното създаване на неклъстерирани индекси.
Опцията DROP_EXISTING е по-мощна от опцията REBUILD, защото е по-гъвкава и предоставя няколко опции, като например промяна на колоните, които съставляват индекса, и промяна на неклъстъриран индекс в клъстерен.
Реорганизиране на страниците на индексния възел
Параметърът REORGANIZE на оператора ALTER INDEX реорганизира страниците на възлите в посочения индекс, така че физическият ред на страниците да съвпада с техния логически ред отляво надясно. Това премахва известна част от фрагментацията на индекса, подобрявайки производителността на индекса.
Деактивиране на индекса
Опцията DISABLE деактивира посочения индекс. Деактивиран индекс не е достъпен за използване, докато не бъде активиран отново. Имайте предвид, че деактивиран индекс не се променя, когато се правят промени в свързаните данни. Поради тази причина, за да използвате повторно деактивиран индекс, той трябва да бъде напълно пресъздаден. За да разрешите деактивиран индекс, използвайте опцията REBUILD на оператора ALTER TABLE.
Когато клъстерен индекс на таблица е деактивиран, данните на таблицата няма да бъдат достъпни, тъй като всички страници с данни на таблицата с клъстерен индекс се съхраняват в нейните дървовидни възли.
Премахване и преименуване на индекси
За да премахнете индекси в текущата база данни, използвайте Инструкция DROP INDEX. Имайте предвид, че премахването на клъстерен индекс върху таблица може да бъде много ресурсоемка операция, защото Всички неклъстърирани индекси ще трябва да бъдат създадени отново. (Всички неклъстерирани индекси използват ключа на индекса на клъстерирания индекс като указател в техните страници на възли.) Използването на оператора DROP INDEX за премахване на индекс е илюстрирано в примера по-долу:
ИЗПОЛЗВАЙТЕ SampleDb; DROP INDEX ix_empid ON Employee;
Инструкцията DROP INDEX има доп ПРЕМЕСТВАНЕ КЪМ параметър, чието значение е същото като параметъра ON на оператора CREATE INDEX. С други думи, можете да използвате този параметър, за да посочите къде да преместите редовете с данни, които са в страниците на клъстерирания индексен възел. Данните се преместват на ново място като купчина. Можете да посочите файлова група по подразбиране или наименувана файлова група за новото място за съхранение на данни.
Операторът DROP INDEX не може да се използва за премахване на индекси, които са създадени имплицитно от системата за ограничения на целостта, като PRIMARY KEY и UNIQUE индекси. За да премахнете такива индекси, трябва да премахнете съответното ограничение.
Индексите могат да бъдат преименувани чрез системната процедура sp_rename.
Индексите също могат да се създават, модифицират и изтриват в Management Studio с помощта на диаграми на бази данни или Object Explorer. Но най-лесният начин е да използвате папката Indexes на необходимата таблица. Управлението на индекси в Management Studio е подобно на управлението на таблици в Management Studio.
Въпреки че Database Engine не поставя практически ограничения върху броя на индексите, има няколко причини, поради които трябва да ограничите броя. Първо, всеки индекс заема определено количество дисково пространство, така че има възможност общият брой на индексните страници на базата данни да надвишава броя на страниците с данни в базата данни. Второ, за разлика от ползата от използването на индекс за извличане на данни, вмъкването и изтриването на данни не предоставя такава полза поради необходимостта от поддържане на индекса. Колкото повече индекси има една таблица, толкова повече работа е необходима за реорганизирането ѝ. Като общо правило е разумно да изберете индекси за чести заявки и след това да оцените тяхното използване.
В този раздел са предоставени някои насоки за създаване и използване на индекси. Следващите препоръки са само общи правила. В крайна сметка тяхната ефективност ще зависи от това как базата данни се използва на практика и вида на най-често изпълняваните заявки. Индексирането на колона, която никога няма да бъде използвана, няма да помогне.
Индекси и условия на клауза WHERE
Ако клаузата WHERE на оператор SELECT съдържа условие за търсене с една колона, тогава трябва да се създаде индекс на тази колона. Това е особено препоръчително при условия на висока селективност. Под селективност на дадено условие разбираме отношението на броя на редовете, които удовлетворяват условието, към общия брой редове в таблицата. Високата селективност съответства на по-ниска стойност на това съотношение. Обработката на търсене с помощта на индексирана колона ще бъде най-успешна, когато селективността на условието е по-малка от 5%.
Една колона не трябва да се индексира, ако нивото на селективност на условието е постоянно на 80% или повече. В този случай индексните страници ще изискват допълнителни входно/изходни операции, което ще намали всяко спестяване на време, постигнато чрез използване на индекси. В този случай е по-бързо да се извърши търсене чрез сканиране на таблицата, което обикновено избира оптимизаторът на заявки, което прави индекса безполезен.
Ако условието за търсене на често използвана заявка съдържа оператори И, най-добре е да създадете съставен индекс на всички колони на таблицата, посочени в клаузата WHERE на оператора SELECT. Създаването на такъв съставен индекс е показано в примера по-долу:
Този пример създава съставен индекс на всички колони на клаузата WHERE. В тази заявка две условия са AND заедно, така че трябва да създадете съставен неклъстерен индекс и на двете колони в тези условия.
Индекси и оператор за присъединяване
За операция за свързване се препоръчва да се създаде индекс за всяка колона, която се свързва. Колоните, които са обединени, често представляват първичния ключ на една таблица и съответния външен ключ на друга таблица. Ако зададете ограничения за целостта на PRIMARY KEY и FOREIGN KEY на съответните колони за присъединяване, трябва да създадете неклъстерен индекс само на колоната с външен ключ, защото системата имплицитно ще създаде клъстерен индекс в колоната с първичен ключ.
Примерът по-долу показва как да създадете индексите, които биха били използвани, ако имате заявка с операция за присъединяване и допълнителен филтър:
Индекс на покритие
Както бе споменато по-рано, включването на всички колони на заявка в индекс може значително да подобри производителността на заявката. Създаването на такъв индекс, наречен покриване, е показано в примера по-долу:
ИЗПОЛЗВАЙТЕ AdventureWorks2012; GO DROP INDEX Person.Address.IX_Address_StateProvinceID; GO CREATE INDEX ix_address_zip ON Person.Address(PostalCode) INCLUDE(City, StateProvinceID); ИЗБЕРЕТЕ City, StateProvinceID FROM Person.Address WHERE PostalCode = 84407;
Този пример първо премахва индекса IX_Address_StateProvinceID от таблицата с адреси. След това се създава нов индекс, който включва две допълнителни колони в допълнение към колоната PostalCode. И накрая, операторът SELECT в края на примера показва заявката, обхваната от индекса. За тази заявка системата не трябва да търси данни в страниците с данни, тъй като оптимизаторът на заявки може да намери всички стойности на колони в неклъстерираните индексни възлови страници.
Препоръчват се покриващи индекси, тъй като индексните страници обикновено съдържат много повече записи от съответните страници с данни. Освен това, за да използвате този метод, филтрираните колони трябва да са първите ключови колони в индекса.
Индекси на изчислени колони
Database Engine ви позволява да създавате следните специални типове индекси:
индексирани изгледи;
филтрируеми индекси;
индекси на изчислени колони;
разделени индекси;
индекси за устойчивост на колони;
XML индекси;
пълнотекстови индекси.
Този раздел обсъжда изчислените колони и свързаните с тях индекси.
Изчислена колонае колона на таблица, в която се съхраняват резултатите от изчисленията на данните от таблицата. Такава колона може да бъде виртуална или постоянна. Тези два типа колони се обсъждат в следващите подраздели.
Виртуални изчисляеми колони
Изчислявана колона, която няма съответен клъстерен индекс, е логическа колона, т.е. не се съхранява физически на твърдия диск. По този начин се оценява всеки път, когато се осъществи достъп до реда. Използването на виртуални изчисляеми колони е показано в примера по-долу:
ИЗПОЛЗВАЙТЕ SampleDb; CREATE TABLE Orders (OrderId INT NOT NULL, Price MONEY NOT NULL, Quantity INT NOT NULL, OrderDate DATETIME NOT NULL, Total AS Price * Quantity, ShippedDate AS DATEADD (DAY, 7, orderdate));
Таблицата „Поръчки“ в този пример има две виртуални изчисляеми колони: обща сума и дата на доставка. Общата колона се изчислява с помощта на две други колони, цена и количество, а колоната с дата на доставка се изчислява с помощта на функцията DATEADD и колоната с дата на поръчката.
Постоянни изчисляеми колони
Database Engine ви позволява да създавате индекси на детерминистични изчислени колони, където базовите колони имат точни типове данни. (Изчислената колона се нарича детерминистична, ако винаги връща едни и същи стойности за едни и същи данни от таблица.)
Индексирана изчисляема колона може да бъде създадена само ако следните параметри на оператора SET са зададени на ON (тези параметри гарантират, че колоната е детерминистична):
QUOTED_IDENTIFIER
CONCAT_NULL_YIELDS_NULL
Освен това параметърът NUMERIC_ROUNDABORT трябва да бъде изключен.
Ако създадете клъстериран индекс върху изчисляема колона, стойностите на колоната ще съществуват физически в съответните редове на таблицата, тъй като страниците на възлите на клъстерирания индекс съдържат редовете с данни. Следният пример създава клъстерен индекс върху изчислена обща стойност на колона от таблицата Поръчки:
ИЗПОЛЗВАЙТЕ SampleDb; CREATE CLUSTERED INDEX ix1 ON Orders (Total);
След изпълнение на оператора CREATE INDEX, изчислената обща колона ще присъства физически в таблицата. Това означава, че всички актуализации на основните колони на изчисляема колона ще доведат до нейното актуализиране.
Колоната може да бъде направена постоянна по друг начин, използвайки ПОСТОЯН параметър. Тази опция ви позволява да укажете физическото присъствие на изчисляема колона, без дори да създавате съответен клъстерен индекс. Тази възможност е необходима за създаване на физически изчислени колони, които се създават върху колони с приблизителен тип данни (float или real). (Както споменахме по-рано, индекс може да бъде създаден само върху изчисляема колона, ако подлежащите й колони са от точния тип данни.)
В тази статия за начинаещи ще разгледам как да определям необходимите индекси за увеличаване на скоростта на изпълнение на SQL заявки.
Всъщност има много тънкости, свързани с индексите, които могат значително да повлияят на ефективността както в едната, така и в обратната посока. В интернет можете да намерите много статии за това. Обемни статии, обясняващи разликите в адресирането, съхранението на паметта и много други неща.
Това, разбира се, са наистина полезни неща, но често пропускат един малък нюанс - обемите данни, при които всички тези функции наистина имат забележим ефект. И тази цифра обикновено се измерва в стотици хиляди записи. С прости думи, ако имате около 1-30 хиляди записа във вашите таблици и говорим за уебсайт (или подобен ресурс), а не за някакво междинно хранилище на данни за натоварени системи, тогава най-често е по-важно да просто изградете правилните индекси. Тук е важно да се отбележи, че не е нужно да сте много технически подковани. Много полезни индекси могат да бъдат изградени с помощта на проста логика.
Забележка: Това предполага, че самите заявки са конструирани повече или по-малко оптимално, например, няма допълнителни полета в select и т.н.
Индекс за целочислени идентификаторни полета.
Ако имате поле с целочислен идентификатор (няма значение дали е идентификаторът на самата таблица или идентификатор, сочещ към ред в друга таблица), тогава изградете отделен индекс за него.
Въпросът е следният. Ако полето е идентификатор на записи в самата таблица, тогава говорим за първичен ключ (също е и индекс). Ползите от такъв индекс са много, тъй като сайтовете най-често работят с идентификатори. Ако това е идентификатор на ред от таблица с директории, тогава е необходим и индекс. Тъй като ако имате нужда от филтрирани данни, тогава без индекси тези директории не са от голяма полза (е, може би само размера на базата данни).
Ако с първия случай всичко е съвсем просто и ясно, то за втория случай (със справочна книга) ще дам прост пример.
Да кажем, че има две таблици: статии (статия - id, име, текст) и коментари (коментар - id, article_id, текст). Първата таблица съдържа 200 записа (статии), втората таблица съдържа 2000 записа (10 коментара за всяка статия). Съответно, когато всеки потребител отвори статия, се изпълнява следната заявка:
Ако sql заявката се изпълни без индекс за полето article_id, тогава цялата таблица с коментари (всичките 2000 записа) ще бъдат напълно сканирани всеки път. Ако се добави индекс за полето article_id, тогава базата данни ще трябва да разглежда не повече от 20 записа (за да бъдем точни, около 18 в най-лошия случай). Изчислението тук е просто. В най-лошия случай търсенето в индекс се извършва приблизително със скоростта на двоичния логаритъм от броя на записите + броя на записите със същата стойност на индексното поле. В този случай всяка статия има 10 записа (стойностите им се повтарят) + log2 от 200 (тъй като има само 200 статии = 2000 / 10) = 10 + 8 (закръглено) = 18.
Разбира се, всеки такъв индекс, в допълнение към дисковото пространство, което заема, въвежда и допълнителни разходи за база данни за вмъквания, актуализации и изтривания. В края на краищата, в допълнение към промяната на данните на самата таблица, има и необходимост от възстановяване на нейните индекси. Но, както вече казах, за обема на обикновените уебсайтове това не е голяма работа. И дори ако създадете индекс на таблица, която не използвате във вашите sql заявки, това няма да причини забележими проблеми. Освен това винаги е възможно чрез инсталиране на допълнителен модул или добавяне на заявки сами, този индекс да бъде много полезен.
Забележка: Не забравяйте обаче, че това се отнася специално за целочислени индекси, а не за опцията „нека да направя индекси за всички възможни полета“.
Прости и съставни индекси за най-често срещаните заявки.
Много бази данни имат кеш с резултати за заявки. Опитайте се да изпълните една и съща заявка два пъти подред - в първия случай заявката ще отнеме много време, за да бъде изпълнена, а във втория път бързо. Първият път данните ще бъдат изчислени, вторият път данните ще бъдат предоставени от кеша. Това обаче не помага много в случаите, когато кешът не е изграден за заявки (например, когато филтърът съдържа изчислени условия, използващи вградени функции на базата данни), в случаите, когато заявките, макар и от един и същи тип, се използват с различни параметри и в тези случаи, когато има много заявки и следователно данните се съхраняват в кеша за много кратък период от време.
Следователно, периодично може да има смисъл допълнително да се изграждат редовни и съставни индекси за често изпълнявани заявки. Нека разгледаме два примера.
Прост индекс.
Да приемем, че имате таблица - продукти (продукт - идентификатор, код, име, текст). И се случва така, че потребителите на сайта често търсят продукти по техните буквено-цифрови кодове (статии - поле за код). Съответно заявката изглежда така:
В тази ситуация има смисъл да се създаде отделен индекс за полето "код", тъй като с него базата данни няма да трябва да сканира напълно всички записи в таблицата. Все пак имайте предвид, че базите данни може да имат ограничения за типовете и размерите на полетата. Затова първо трябва да проверите дали е възможно да създадете индекс за такива полета.
Съставен индекс.
Преди да дам пример със съставен индекс, бих искал малко да изясня един важен момент - важен е редът на полетата в индекса. Тъй като търсенето се извършва първо от първото поле, а след това от следващото (и т.н.). Следователно, ако знаете конкретната стойност само на последното поле, тогава такъв индекс няма да е подходящ, тъй като без да знаете конкретната стойност на първото поле, е невъзможно да определите кой набор от записи трябва да се провери, което е защо базата данни ще трябва да сканира всички записи в таблицата. С прости думи, индекс (колона_1, колона_2) не е равен на индекс (колона_2, колона_1).
Сега нека приемем следната ситуация. Има три таблици: потребител (user - id, име), категория (cat - id, име) и статия (article - id, cat_id, user_id, име, текст). И вие направихте такова нещо на сайта - в долната част на статията се показва пълен списък със статии от същия потребител от дадена категория. В същото време потребителите се оказаха толкова плодовити, че пишат много статии, макар и в различни категории (например малки истории, кратки бележки и т.н.). В този случай заявката ще изглежда така:
Ако сте направили индекси за полета с идентификатор, тогава това ще ви помогне, но не много. Първо, има два еднакво вероятни индекса. Един за категории, а вторият за потребители. Кое ще бъде по-добро, обикновено не се знае. Освен това това може да не помогне много, тъй като потребителите може да имат 1000 статии, а категориите може да имат 1000 статии. Второ, дори и да намалите записите за конкретен потребител (или категория), те пак ще трябва да бъдат сканирани с помощта на второто поле, тоест пълно сканиране (макар и за по-малък обем записи). Например, ако потребителите имат 1000 записа, тогава ще трябва да проверите за всички 1000 записа дали принадлежат към категорията или не.
За голям брой записи и чести обаждания това е много скъпа sql заявка. Следователно в този случай си струва да направите съставен индекс, например (user_id, cat_id). В този случай след търсене по потребител последващото търсене по категория ще бъде по-бързо, тъй като ще има и индекс за получения резултат. записи. Съответно, вместо проверка на 1000 записа, ще бъдат проверени значително по-малко (проверките се изчисляват по същия начин, както при обикновен индекс - логаритъм + брой записи).
Как можете да определите реда на полетата в такива ситуации? Всичко тук е доста просто и подобно на това, което описах в статията за филтрирането (вижте връзката в началото). Нека ви напомня, че въпросът е, че с всеки прилаган филтър броят на записите става възможно най-малък. Следователно има смисъл да проверявате средния брой записи за всяка стойност на полето в таблицата. И полето с това число по-малко трябва да е първо. Например, за дадена SQL заявка си струва да проверите следното:
Изчислете средния брой записи за избор на потребители -- Среден брой записи avg(data.count) като avg от -- Групирайте всички записи по идентификатор (изберете count(*) като `count` от статия -- Групирайте по потребители групирайте по user_id) като данни; -- Изчислете средния брой записи за категории изберете -- Среден брой записи avg(data.count) като avg от -- Групирайте всички записи по id (изберете count(*) като `count` от статия -- Групирайте по категория група по cat_id) като данни;
Съответно, ако средният брой за потребителите е по-малък, тогава това поле трябва да бъде първо, тъй като след първото търсене ще има малко записи за проверка. В противен случай идентификаторът на категорията трябва да е на първо място.
Струва си обаче да се разбере, че в такава ситуация също си струва да се провери дали записите са разпределени повече или по-малко равномерно. В крайна сметка може да се окаже, че 1 потребител е написал 2000 статии, а останалите само 100. В такава ситуация може да е за предпочитане филтър по категория, тъй като повечето читатели ще видят статиите на този конкретен потребител. Следователно понякога си струва да се изчисли само групирането по идентификатори (без да се изчисли ср.) и бързо да се видят резултатите.
Ако трябва да създадете индекс за три или повече полета, трябва да направите същото, като само увеличите броя на полетата, за които групирането се извършва по идентификатор. С прости думи, първо проверете първото поле и определете най-малкото число, след това вместо „групиране по колона_1“ посочете различни опции с останалите полета под формата на „групиране по колона_1, колона_2“, след това „групиране по колона_1, колона_3“ и така нататък. В този случай всеки избира тези комбинации, в които средният брой записи става все по-малък.
И индекси, това специални справочни таблици, които търсачката на бази данни може да използва за ускоряване на извличането на данни. Просто казано, индексът е указател към данни в таблица. Индексът в базата данни е много подобен на индекса в края на книгата.
Например, ако искате връзки към всички страници в книга по определена тема, първо се консултирайте с индекса, който изброява всички теми по азбучен ред и след това препраща към един или повече конкретни номера на страници.
Индексът помага за ускоряване на заявките и изреченията, но забавя въвеждането на данни с изявления АКТУАЛИЗИРАНЕИ ВМЪКНЕТЕ. Индексите могат да се създават или изтриват, без това да засяга данните.
Създаването на индекс включва изявление СЪЗДАВАНЕ НА ИНДЕКС, което ви позволява да наименувате индекс, за да посочите таблицата и коя колона или колони да индексирате и да посочите дали индексът е във възходящ или низходящ ред.
Индексите също могат да бъдат уникални, с ограничението ЕДИНСТВЕН ПО РОДА СИ, така че индексът да предотвратява дублиращи се записи в колона или комбинация от колони, които имат индекс върху нея.
Команда CREATE INDEX
Основен синтаксис СЪЗДАВАНЕ НА ИНДЕКСкакто следва:
CREATE INDEX index_name ON table_name;
Индекси с една колона
Индекс с една колона се създава само върху една колона в таблицата. Основният синтаксис е както следва.
CREATE INDEX index_name ON table_name(column_name);
Уникални индекси
Уникалните индекси се използват не само за работа, но и за осигуряване на целостта на данните. Уникалният индекс не позволява дублиращи се стойности да бъдат вмъкнати в таблицата. Основният синтаксис е както следва.
CREATE UNIQUE INDEX index_name на table_name(column_name);
Композитни индекси
Съставният индекс е индекс на две или повече колони на таблица. Неговият основен синтаксис е както следва.
CREATE INDEX index_name на table_name (колона1, колона2);
Независимо дали създавате индекс на една колона или съставен индекс, вземете под внимание колоната(ите), която може да използвате много често в WHERE заявка като условие за филтър.
Ако има само една използвана колона, трябва да се избере индекс на една колона. Ако има две или повече колони, които често се използват като филтри в клаузата WHERE, съставният индекс би бил по-добър избор.
Неявни индекси
Неявните индекси са индекси, които се създават автоматично на сървъра на базата данни, когато се създава обект. Индексите се създават автоматично върху първичния ключ и уникалното ограничение.
Команда DROP INDEX
Индексът може да бъде изтрит с помощта на SQL команда ИЗПУСКАЙТЕ. Трябва да внимавате, когато изтривате индекс, защото производителността може или да е по-бавна, или по-добра.
Основният синтаксис е както следва:
DROP INDEX index_name;
Можете да разгледате примера за ограничение INDEX, за да видите някои реални примери за индекси.
Кога трябва да избягвате индексите?
Въпреки че индексите са предназначени да подобрят производителността на базата данни, има моменти, когато те трябва да се избягват.
Следващите инструкции показват кога трябва да се преразгледа използването на индекса.
- Индексите не трябва да се използват на малки таблици.
- Таблици, които имат чести големи операции за актуализиране или вмъкване.
- Индексите не трябва да се използват за колони, които съдържат голям брой нулеви стойности.
- Колони, които често се манипулират, не трябва да се индексират.