В начале каждого семестра студенты магистерской программы кафедры МиИТ Академического университета (СПб) и представители компаний-партнеров собираются вместе. Представители рассказывают о проектах, над которыми можно будет работать, а студенты выбирают их.
В одном из проектов, сделанных в Parallels Labs , наш студент исследовал возможность реализации виртуального Hardware Security Module (HSM) . В результате он добавил свою реализацию VHSM в open-source проект OpenVZ . Подробнее о его решении читайте под катом.
Что такое HSM
Представим себе приложение, которое подписывает отправляемые на сервер данные с помощью приватного ключа. Пусть утеря данного ключа неприемлема для его собственника. Как защитить такой ценный ключ от утечки в результате удаленного взлома системы? Подход с использованием HSM предлагает нам вообще не давать уязвимой части системы доступ к содержимому ключа. HSM – это физическое устройство, которое само хранит цифровые ключи или другие секретные данные, управляет ими, генерирует их, а также производит с их помощью криптографические операции. Все операции над данными производятся внутри HSM, а пользователь имеет доступ только к результатам этих операций. Внутренняя память устройства защищена от физического доступа и взлома. При попытке проникновения все секретные данные уничтожаются.Чтобы начать использовать HSM, пользователь должен себя аутентифицировать. Если аутентификация выполняется через приложение-клиент HSM, работающее в уязвимой части системы, то возможен перехват пароля HSM злоумышленником. Перехваченный пароль даст возможность злоумышленнику использовать HSM без получения секретных данных, хранящихся в нем. Таким образом, аутентификацию желательно выполнять в обход уязвимой части системы, например, при помощи физического ввода PIN.
Основным барьером в использовании HSM является их высокая стоимость. В зависимости от класса устройства цена может варьироваться от 10$ (USB токены, smart карты) до 30000+$ (устройства с аппаратным ускорением криптографии, защитой от взлома, high availability функциями). Провайдеры cloud решений не оставили без внимания рынок HSM. Например, Amazon продает свой облачный HSM по средней цене 1373$ в месяц.
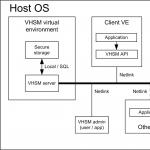
Одной из основных особенностей HSM является изоляция уязвимой части системы, использующей криптографические сервисы, от HSM, исполняющей эти сервисы. Заметим, что отдельные инстансы (виртуальные машины, контейнеры и т.д.), в облаке изолированы друг от друга, поэтому если вынести функции HSM за пределы уязвимого инстанса в другой изолированный от внешнего мира инстанс, то мы достаточно точно воспроизведем функциональность физического HSM. Такой подход мы назвали Virtual HSM (VHSM) . Рассмотрим как он был реализован нашим студентом для проекта OpenVZ .
Что такое OpenVZ
OpenVZ – это одна из технологий для запуска множества изолированных ОС Linux на одном ядре Linux. При этом говорят, что каждая ОС Linux работает в отдельном контейнере. Если сильно упрощать, то фактически в ядро Linux встроена функциональность, которая позволяет изолировать приложения, приписанные разным контейнерам так, чтобы они не подозревали о существовании друг друга. Приложения не могут сменить свой контейнер. Для лучшей изоляции и безопасности коммуникация между приложениями из разных контейнеров при помощи средств IPC запрещена. Обычно она осуществляется с помощью сетевых соединений. В итоге мы видим сходство контейнеров с “обычными” виртуальными машинами. OpenVZ и технологии на ее основе популярны у хостинг провайдеров для создания VPS. В Академическом университете уже делались проекты, связанные с контейнерной виртуализацией. Например . Parallels – главный разработчик OpenVZ. Вполне закономерной стала реализация VHSM именно для OpenVZ.Архитектура Virtual HSM

- Client VE – контейнер OpenVZ, в котором выполняются пользовательские приложения, требующие для своей работы криптографические сервисы, такие как шифрование, подпись и т.д. Контейнер доступен для удаленных атак с целью кражи цифровых ключей.
- VHSM virtual environment (VHSM VE) - контейнер OpenVZ, в котором запущен VHSM server – демон, принимающий команды от приложений в Client VE и исполняющий их. Никаких других приложений в VHSM VE не запущено. VHSM VE изолирован от обычных пользовательских контейнеров при помощи OpenVZ. У контейнера нет сетевых интерфейсов и он не доступен по сети.
- Transport – модуль ядра Linux, предназначенный для передачи сообщений из Client VE в VHSM VE и обратно.
- VHSM API – библиотека, реализующая часть стандартного для HSM интерфейса PKCS #11, передающая команды приложений из ClientVE в VHSM server при помощи transport, и возвращающая результат выполнения команды приложению в ClientVE.
VHSM virtual environment
Сервер VHSM отвечает за аутентификацию пользователей, взаимодействие с хранилищем секретных данных и выполнение криптографических операций. Кроме сервера VHSM, VHSM VE содержит Secure Storage – базу данных, хранящую важную информацию в зашифрованном виде. Каждый пользователь VHSM имеет свой мастер ключ, которым шифруются его данные. Мастер ключ генерируется из пароля пользователя при помощи функции PBKDF2 . Передаваемая ей на вход соль хранится в незашифрованном виде в базе данных. Таким образом, VHSM не хранит мастер ключ пользователя в БД, а использование PBKDF2 существенно снижает скорость перебора исходного пароля пользователя при краже БД.Пользователь регистрируется в VHSM администратором, в роли которого может выступать как человек, так и программа. При регистрации пользователя VHSM генерирует 256-битный ключ аутентификации и шифрует его мастер ключом с помощью AES-GCM . Далее, перед использованием VHSM, пользователь аутентифицирует себя парой логин-пароль. Во время аутентификации, мастер-ключ, сформированный из пароля и соли, используется для расшифровывания ключа аутентификации пользователя. Использование GCM позволяет проверить правильность мастер-ключа при расшифровке. Мастер-ключ получается из пароля пользователя, и потому проверка его правильности позволяет проверить и сам пароль пользователя, переданный при аутентификации. После успешной аутентификации пользователю становятся доступны криптографические сервисы, использующие хранящиеся в VHSM цифровые ключи пользователя.
VHSM требует явного выбора контейнеров, из которых конкретный пользователь может работать с VHSM. Информация о контейнере, из которого получена команда пользователя, предоставляется OpenVZ.
VHSM API
Это C-библиотека, находящаяся в пользовательских контейнерах и реализующая часть стандартного для HSM интерфейса PKCS#11, позволяющего управлять ключами, данными, сессиями, цифровой подписью, шифрованием и т.д. Рассмотрим конкретный пример использования VHSM API:- Приложению в пользовательском контейнере необходимо подписать отправляемое сообщение.
- При помощи VHSM API приложение генерирует пару открытый-закрытый ключ, получает ID закрытого ключа и открытый ключ.
- Приложение передает сообщение в VHSM API для подписывания закрытым ключом с нужным ID. VHSM API возвращает подписанное сообщение.
- Подписанное сообщение и открытый ключ передаются получателю сообщения. При этом закрытый ключ не доступен клиентскому контейнеру.
VHSM Transport
Как было сказано выше, приложения, исполняющиеся в разных контейнерах, не могут взаимодействовать друг с другом при помощи механизмов IPC Linux. Поэтому для транспортировки сообщений от клиентов к серверу и обратно был реализован свой загружаемый модуль ядра Linux. Модуль запускает Netlink-сервер в ядре, а VHSM-клиенты и VHSM-сервер соединяются с ним. Netlink-сервер отвечает за передачу сообщений от источника (клиента VHSM) к приемнику (серверу VHSM) и обратно. Попутно к сообщениям добавляется ID контейнера источника сообщения, чтобы, например, сервер мог отклонить запросы от контейнеров, из которых конкретному пользователю запрещено использовать VHSM.Заключение
Основной целью создания VHSM было исключение возможности кражи секретных ключей из памяти пользовательских приложений, работающих в пользовательском контейнере. Эта цель была достигнута, т.к. секретные данные доступны только в изолированном контейнере (VHSM VE). Изоляция реализуется OpenVZ.Утечка БД из VHSM VE не приведет к немедленной утрате секретных данных, т.к. они хранятся в зашифрованном виде. Ключ шифрования не хранится в БД, а генерируется из пароля пользователя, передающегося при его аутентификации.
Как и любая технология защиты иформации, приведенное решение является еще одним барьером на пути злоумышленника и не обеспечивает полной защиты информации.
По-английски расшифровывается как Uniform Resource Locator, что в переводе на русский язык обозначает «единый указатель ресурсов». По-русски эту аббревиатуру обычно произносят как «у-эр-эл», «ю-ар-эл», или просто «урл». Попробуем разобраться подробнее в том, что такое URL. Каждый документ (веб-страница) в сети Интернет имеет определенное местонахождение, на которое можно точно указать. С помощью URL адреса как раз и указывается точный путь к определенной вебстранице. Аналогично тому, как указывается путь к любому файлу на компьютере, URL адрес строится по определенной схеме, которая обычно выглядит приблизительно так:
http://name.ru/papka/document.html
Где http - указывает на тип протокола, по которому осуществляется передача данных, name.ru - означает доменное имя сайта, papka представляет собой папку, а document.html - конкретную страницу, на которую и ведет данный URL адрес.
Поскольку наш URL адрес http://name.ru/papka/document.html является вымышленным, дается только для примера, и, соответственно, ни к какой вебстранице не ведет, то, попытавшись перейти по нему, мы попадем на страницу, содержащую информацию об ошибке. Выглядеть она может по-разному, однако мы обязательно встретим надпись «404 not found ». «Not found» в переводе означает «не найдено», а появление страницы 404 означает, что URL адрес вебстраницы был введен не полностью, неверно (с ошибкой или опечаткой), либо запрошенная страница больше не находится по данному адресу, так как была удалена или переименована.
Ошибка 404 часто возникает при переходе по ссылке, найденной на другой странице, в том случае, если ссылка является устаревшей. Автор сайта мог переместить нужный нам документ, переименовать его или удалить. Что же делать, если при переходе возникает 404 страница? Во-первых, проверить правильность URL адреса, если он нам известен. Исправить ошибки или опечатки и попробовать перейти снова. Если же ошибка 404 возникает при переходе по ссылке на незнакомый ресурс, следует попробовать перейти на главную и воспользоваться поиском по сайту - возможно, что нужная информация все же найдется.
Кстати, многие разработчики сайтов заботятся о том, чтобы страница 404 на их сайте не выглядела устрашающе безнадежно. Здесь размещают юмористический текст с забавной картинкой, чтобы подбодрить заблудившегося пользователя, а также ссылки на главную сайта, строку поиска либо карту сайта. Если страница 404 выглядит недружелюбно и ссылок для перехода на ней нет, можно попробовать вручную сократить URL адрес, оставив только имя сайта - в нашем примере это будет http://name.ru/ и таким образом попытаться попасть на главную страницу сайта, откуда можно будет перейти на искомую страницу.
URL (УРЛ, от англ. Uniform Resource Locator) - указатель размещения сайта в интернете. URL-адрес содержит доменное имя и указание пути к странице, включая название файла этой страницы.
Тим Бернерс-Ли (участник Европейского совета по ядерно-военным проблемам в Женеве) в 1990 году изобрел URL, который на тот период являлся просто адресом размещения файлов в системе.
Наряду с большими достоинствами (доступность навигации в интернете) у URL-адреса страницы есть и недостаток – это работа только с латинскими буквами, цифрами и некоторыми символами. Если требуется использовать, например, кириллицу, то URL должен быть перекодирован специальным способом..ru/wiki/%D1%87%D1%82%D0%BE-%D1%82%D0%B0%D0%BA%D0%BE%D0%B5-url/. Подобное кодирование проходит в два шага: сначала происходит преобразование каждого символа в последовательность из двух байтов, потом каждый байт переписывается в шестнадцатеричной системе.
Как много значит URL-адрес сайта в SEO?
Поисковые системы учитывают вхождения ключевых фраз в URL-адреса. Наибольшее влияние оказывают вхождения в адрес домена и поддоменов, меньшее, но все же весьма значимое значение, играют вхождения в путь до страницы и название файла страницы. В связи с чем, в интернете активно развивается вид заработка, называемый киберсквоттинг. Его суть заключается в регистрации доменных имен по рыночной стоимости с целью последующей перепродажи по завышенной цене.
HTTP - это протокол передачи гипертекста между распределёнными системами. По сути, http является фундаментальным элементом современного Web-а. Как уважающие себя веб разработчики, мы должны знать о нём как можно больше.
Давайте взглянем на этот протокол через призму нашей профессии. В первой части пройдёмся по основам, посмотрим на запросы/ответы. В следующей статье разберём уже более детальные фишки, такие как кэширование, обработка подключения и аутентификация.
Также в этой статье я буду, в основном, ссылаться на стандарт RFC 2616 : Hypertext Transfer Protocol -- HTTP/1.1.
Основы HTTP
HTTP обеспечивает общение между множеством хостов и клиентов, а также поддерживает целый ряд сетевых настроек.
В основном, для общения используется TCP/IP, но это не единственный возможный вариант. По умолчанию, TCP/IP использует порт 80, но можно заюзать и другие.
Общение между хостом и клиентом происходит в два этапа: запрос и ответ. Клиент формирует HTTP запрос, в ответ на который сервер даёт ответ (сообщение). Чуть позже, мы более подробно рассмотрим эту схему работы.
Текущая версия протокола HTTP - 1.1, в которой были введены некоторые новые фишки. На мой взгляд, самые важные из них это: поддержка постоянно открытого соединения, новый механизм передачи данных chunked transfer encoding, новые заголовки для кэширования. Что-то из этого мы рассмотрим во второй части данной статьи.
URL
Сердцевиной веб-общения является запрос, который отправляется через Единый указатель ресурсов (URL). Я уверен, что вы уже знаете, что такое URL адрес, однако для полноты картины, решил всё-таки сказать пару слов. Структура URL очень проста и состоит из следующих компонентов:

Протокол может быть как http для обычных соединений, так и https для более безопасного обмена данными. Порт по умолчанию - 80. Далее следует путь к ресурсу на сервере и цепочка параметров.
Методы
С помощью URL, мы определяем точное название хоста, с которым хотим общаться, однако какое действие нам нужно совершить, можно сообщить только с помощью HTTP метода. Конечно же существует несколько видов действий, которые мы можем совершить. В HTTP реализованы самые нужные, подходящие под нужды большинства приложений.
Существующие методы:
GET : получить доступ к существующему ресурсу. В URL перечислена вся необходимая информация, чтобы сервер смог найти и вернуть в качестве ответа искомый ресурс.
POST : используется для создания нового ресурса. POST запрос обычно содержит в себе всю нужную информацию для создания нового ресурса.
PUT : обновить текущий ресурс. PUT запрос содержит обновляемые данные.
DELETE : служит для удаления существующего ресурса.
Данные методы самые популярные и чаще всего используются различными инструментами и фрэймворками. В некоторых случаях, PUT и DELETE запросы отправляются посредством отправки POST, в содержании которого указано действие, которое нужно совершить с ресурсом: создать, обновить или удалить.
Также HTTP поддерживает и другие методы:
HEAD : аналогичен GET. Разница в том, что при данном виде запроса не передаётся сообщение. Сервер получает только заголовки. Используется, к примеру, для того чтобы определить, был ли изменён ресурс.
TRACE : во время передачи запрос проходит через множество точек доступа и прокси серверов, каждый из которых вносит свою информацию: IP, DNS. С помощью данного метода, можно увидеть всю промежуточную информацию.
OPTIONS : используется для определения возможностей сервера, его параметров и конфигурации для конкретного ресурса.
Коды состояния
В ответ на запрос от клиента, сервер отправляет ответ, который содержит, в том числе, и код состояния. Данный код несёт в себе особый смысл для того, чтобы клиент мог отчётливей понять, как интерпретировать ответ:
1xx: Информационные сообщения
Набор этих кодов был введён в HTTP/1.1. Сервер может отправить запрос вида: Expect: 100-continue, что означает, что клиент ещё отправляет оставшуюся часть запроса. Клиенты, работающие с HTTP/1.0 игнорируют данные заголовки.
2xx: Сообщения об успехе
Если клиент получил код из серии 2xx, то запрос ушёл успешно. Самый распространённый вариант - это 200 OK. При GET запросе, сервер отправляет ответ в теле сообщения. Также существуют и другие возможные ответы:
- 202 Accepted : запрос принят, но может не содержать ресурс в ответе. Это полезно для асинхронных запросов на стороне сервера. Сервер определяет, отправить ресурс или нет.
- 204 No Content : в теле ответа нет сообщения.
- 205 Reset Content : указание серверу о сбросе представления документа.
- 206 Partial Content : ответ содержит только часть контента. В дополнительных заголовках определяется общая длина контента и другая инфа.
3xx: Перенаправление
Своеобразное сообщение клиенту о необходимости совершить ещё одно действие. Самый распространённый вариант применения: перенаправить клиент на другой адрес.
- 301 Moved Permanently : ресурс теперь можно найти по другому URL адресу.
- 303 See Other : ресурс временно можно найти по другому URL адресу. Заголовок Location содержит временный URL.
- 304 Not Modified : сервер определяет, что ресурс не был изменён и клиенту нужно задействовать закэшированную версию ответа. Для проверки идентичности информации используется ETag (хэш Сущности - Enttity Tag);
4xx: Клиентские ошибки
Данный класс сообщений используется сервером, если он решил, что запрос был отправлен с ошибкой. Наиболее распространённый код: 404 Not Found. Это означает, что ресурс не найден на сервере. Другие возможные коды:
- 400 Bad Request : вопрос был сформирован неверно.
- 401 Unauthorized : для совершения запроса нужна аутентификация. Информация передаётся через заголовок Authorization.
- 403 Forbidden : сервер не открыл доступ к ресурсу.
- 405 Method Not Allowed : неверный HTTP метод был задействован для того, чтобы получить доступ к ресурсу.
- 409 Conflict : сервер не может до конца обработать запрос, т.к. пытается изменить более новую версию ресурса. Это часто происходит при PUT запросах.
5xx: Ошибки сервера
Ряд кодов, которые используются для определения ошибки сервера при обработке запроса. Самый распространённый: 500 Internal Server Error. Другие варианты:
- 501 Not Implemented : сервер не поддерживает запрашиваемую функциональность.
- 503 Service Unavailable : это может случиться, если на сервере произошла ошибка или он перегружен. Обычно в этом случае, сервер не отвечает, а время, данное на ответ, истекает.
Форматы сообщений запроса/ответа
На следующем изображении вы можете увидеть схематично оформленный процесс отправки запроса клиентом, обработка и отправка ответа сервером.

Давайте посмотрим на структуру передаваемого сообщения через HTTP:
Message =
Между заголовком и телом сообщения должна обязательно присутствовать пустая строка. Заголовков может быть несколько:
Тело ответа может содержать полную информацию или её часть, если активирована соответствующая возможность (Transfer-Encoding: chunked). HTTP/1.1 также поддерживает заголовок Transfer-Encoding.
Общие заголовки
Вот несколько видов заголовков, которые используются как в запросах, так и в ответах:
General-header = Cache-Control | Connection | Date | Pragma | Trailer | Transfer-Encoding | Upgrade | Via | Warning
Что-то мы уже рассмотрели в этой статье, что-то подробней затронем во второй части.
Заголовок via используется в запросе типа TRACE, и обновляется всеми прокси-серверами.
Заголовок Pragma используется для перечисления собственных заголовков. К примеру, Pragma: no-cache - это то же самое, что Cache-Control: no-cache. Подробнее об этом поговорим во второй части.
Заголовок Date используется для хранения даты и времени запроса/ответа.
Заголовок Upgrade используется для изменения протокола.
Transfer-Encoding предназначается для разделения ответа на несколько фрагментов с помощью Transfer-Encoding: chunked. Это нововведение версии HTTP/1.1.
Заголовки сущностей
В заголовках сущностей передаётся мета-информация контента:
Entity-header = Allow | Content-Encoding | Content-Language | Content-Length | Content-Location | Content-MD5 | Content-Range | Content-Type | Expires | Last-Modified
Все заголовки с префиксом Content- предоставляют информацию о структуре, кодировке и размере тела сообщения.
Заголовок Expires содержит время и дату истечения сущности. Значение “never expires” означает время + 1 код с текущего момента. Last-Modified содержит время и дату последнего изменения сущности.
С помощью данных заголовков, можно задать нужную для ваших задач информацию.
Формат запроса
Запрос выглядит примерно так:
Request-Line = Method SP URI SP HTTP-Version CRLF Method = "OPTIONS" | "HEAD" | "GET" | "POST" | "PUT" | "DELETE" | "TRACE"
SP - это разделитель между токенами. Версия HTTP указывается в HTTP-Version. Реальный запрос выглядит так:
GET /articles/http-basics HTTP/1.1 Host: www.articles.com Connection: keep-alive Cache-Control: no-cache Pragma: no-cache Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Список возможных заголовков запроса:
Request-header = Accept | Accept-Charset | Accept-Encoding | Accept-Language | Authorization | Expect | From | Host | If-Match | If-Modified-Since | If-None-Match | If-Range | If-Unmodified-Since | Max-Forwards | Proxy-Authorization | Range | Referer | TE | User-Agent
В заголовке Accept определяется поддерживаемые mime типы, язык, кодировку символов. Заголовки From, Host, Referer и User-Agent содержат информацию о клиенте. Префиксы If- предназначены для создания условий. Если условие не прошло, то возникнет ошибка 304 Not Modified.
Формат ответа
Формат ответа отличается только статусом и рядом заголовков. Статус выглядит так:
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
- HTTP версия
- Код статуса
- Сообщение статуса, понятное для человека
Обычный статус выглядит примерно так:
HTTP/1.1 200 OK
Заголовки ответа могут быть следующими:
Response-header = Accept-Ranges | Age | ETag | Location | Proxy-Authenticate | Retry-After | Server | Vary | WWW-Authenticate
- Age время в секундах, когда сообщение было создано на сервере.
- ETag MD5 сущности для проверки изменений и модификаций ответа.
- Location используется для перенаправления и содержит новый URL адрес.
- Server определяет сервер, где было сформирован ответ.
Думаю, на сегодня теории достаточно. Теперь давайте взглянем на инструменты, которыми мы можем пользоваться для мониторинга HTTP сообщений.
Инструменты для определения HTTP трафика
Существует множество инструментов для мониторинга HTTP трафика. Вот несколько из них:
Наиболее часто используемый - это Chrome Developers Tools:

Если говорить об отладчике, можно воспользоваться Fiddler :

Для отслеживания HTTP трафика вам потребуется curl, tcpdump и tshark.
Библиотеки для работы с HTTP - jQuery AJAX
Поскольку jQuery очень популярен, в нём также есть инструментарий для обработки HTTP ответов при AJAX запросах. Информацию о jQuery.ajax(settings) можете найти на официальном сайте .
Передав объект настроек (settings), а также воспользовавшись функцией обратного вызова beforeSend, мы можем задать заголовки запроса, с помощью метода setRequestHeader().
$.ajax({ url: "http://www.articles.com/latest", type: "GET", beforeSend: function (jqXHR) { jqXHR.setRequestHeader("Accepts-Language", "en-US,en"); } });
Если хотите обработать статус запроса, то это можно сделать так:
$.ajax({ statusCode: { 404: function() { alert("page not found"); } } });
Итог
Вот такой вот он, тур по основам протокола HTTP. Во второй части будет ещё больше интересных фактов и примеров.
Практически каждый работающий в Интернете пользователь встречает в сети упоминания о URL , URL-адресах, приглашениях перейти на какой-либо линк и воспользоваться ссылкой. Для тех, кто не знаком или плохо знаком с данными понятиями, я решил написать материал, в котором расскажу, что это такое URL адрес, как использовать URL, на какие части делится УРЛ, а я также поясню, как найти нужную ссылку в сети.
URL — это адрес, указывающий путь к интернет ресурсу, на котором размещены различные виды файлов (документы, картинки, видео, аудио и др.). Аббревиатура URL расшифровывается как «Uniform Resource Locator» (Единый Указатель Ресурсов), по-русски она обычно произносится как «урл», «ю-ар-эл», «у-эр-эл», часто используется просто слово «ссылка».
Помню, искал некоторое время назад что это такое URL адрес, для того чтобы грамотно рассказать братику все тонкости понятия. И самому стало интересно, когда появился данный термин.
Автором понятия URL считается британец Тим Бернес-Ли, а само изобретение (1990г.) ознаменовало качественный скачок в развитии интернет технологий. Сейчас URL является идентификатором адресов практически всех ресурсов в сети, при этом сам термин URL постепенно заменяется более обширным термином URI (Uniform Resource Identifier – Единый Идентификатор Ресурсов).
URL постов в социальных сетях

На какие части делится URL-адрес
Классический пример URL-адреса выглядит примерно так:
http://адрес_сайта/папка/страница.html
Как видим, адрес URL делится на несколько частей:
Первая часть (http://) определяет используемый протокол. Проще говоря, она говорит о методе, который будет использоваться для получения доступа к нужному ресурсу.
Используемый в данном URL протокол «HTTP» расшифровывается как «HyperText Transfer Protocol», и применяется он в абсолютном большинстве случаев. Но можно найти URL c использованием другие протоколов, к примеру, FTP (File Transfer Protocol – протокол для передачи файлов), HTTPS (HyperText Transfer Protocol Secure – безопасная, зашифрованная версия HTTP), mailto (адрес электронной почты) и другие.
Всего же видов протоколов URL насчитывается несколько десятков ftp, http, rtmp, rtsp, https, gopher, mailto, news, nntp, smb, prospero, telnet, wais, xmpp, file, data и др, но используются обычно несколько основных, перечисленных мной чуть выше.

Вторая часть (адрес_сайта ) – это имя домена. Технически это просто линия символов, букв или комбинация слов, позволяющая людям легко запоминать адрес любимой страницы. В ином случае ссылки на ресурсы выглядели бы как http://192.168.384..
Третья часть (папка/страница.html) обычно указывает на какую-либо страницу ресурса, к которой пользователь хочет получить доступ. Она может быть просто в виде названия, или в виде пути к определённому файлу через набор папок, последние обычно разделяются слешом (/). Расширение интернет страниц может быть разным – php, htm, html, shtml, asp и ряд других.
Визуально данные пояснения можно посмотреть на видео:
Используемая перед названием домена аббревиатуры www (World Wide Web – всемирная паутина) не является обязательной, вы можете использовать адрес сайта и без неё, сайт обязательно откроется.
Особенности использования URL адреса
Если указанный пользователем URL не верен, то система покажем нам ошибку 404 с примечанием «Страница не найдена!». Значит, пользователь набрал или не правильный, или устаревший адрес страницы, потому при наборе адреса необходимы точность, аккуратность и внимание. Я бы рекомендовал при наборе URL использовать , скопировав адрес страницы через функции «копировать/вставить». Можно также попробовать набрать урезанный URL адрес в виде только основного имени сайта (без папок и страниц), а уже на главной странице сайта поискать переход на нужную нам страницу.

Недостатки URL
После описания, что это URL ссылка давайте разберём все недостатки УРЛ. Наряду с преимуществами, позволяющими легко вести навигацию в интернете, у URL есть свои недостатки. Это работа только цифрами, латинскими буквами и некоторыми символами, кириллица же обычно должна быть перекодирована (URL Encoding) в два этапа, на первом из которых каждый кириллический символ преобразовывается в два байта, а потом каждый из байтов переписывается с использованием шестнадцатеричной системы.
Кроме того, в адресе рекомендуется использовать преимущественно маленькие буквы (некоторые Unix-системы их заглавные варианты будут воспринимать как разные символы, что может привести к ошибке открытия страницы), также в адресах URL запрещается использовать пробелы.
Как найти URL адрес. Закладки.
Для поиска требуемого URL адреса можно воспользоваться поисковыми системами, в которых необходимо прописать ключевые слова вашего поиска. К примеру, если нужен какой-либо фильм – тогда ввести его название, или имена актёров, если музыка – имена исполнителей и название композиции. Нажав «Поиск» вы получите множество сайтов с URL адресами, кликнув на которые вы можете найти нужный результат.
URL страницы, на которой вы находитесь в данный момент, размещается в адресной строке вашего браузера, расположенной вверху.
Для запоминания URL адреса нужной страницы используйте панель закладок вашего браузера. К примеру, в популярном браузере Mozilla Firefox иконка закладок в виде звёздочки расположена справа сверху на уровне адресной строки. Кликнув на неё, вы получите возможность набрать имя для вашей закладки, а также папку, куда складывать закладки (обычно я использую специальную панель закладок, позволяющая по одному клику получать доступ к любой из них).
Заключение
Использование URL здорово облегчило работу в сети Интернет, позволив множеству пользователей легко и быстро получать доступ к нужным сайтам. Если у вас остались вопросы после прочтений статьи “URL адрес что это такое” пишите их в комментариях к статье.
Всё, что сегодня нужно – это вбить название сайта и его расширение в адресной строке, после чего пользователь получает практически мгновенный доступ к ресурсу. И всё это без необходимости запоминать достаточно сложный ряд трёхзначных цифр, всё делается легко, быстро, эффективно – в общем, то, что нужно, не правда ли.
Вконтакте