Zu Beginn jedes Semesters treffen sich Studierende des Masterstudiengangs der Abteilung MiIT der Akademischen Universität (St. Petersburg) und Vertreter von Partnerunternehmen. Vertreter sprechen über Projekte, an denen sie arbeiten möchten, und die Studenten wählen sie aus.
In einem der bei Parallels Labs durchgeführten Projekte untersuchte unser Student die Möglichkeit der Implementierung eines virtuellen Hardware-Sicherheitsmoduls (HSM). Infolgedessen fügte er seine VHSM-Implementierung dem Open-Source-Projekt OpenVZ hinzu. Lesen Sie mehr über seine Lösung unter dem Schnitt.
Was ist HSM?
Stellen wir uns eine Anwendung vor, die an den Server gesendete Daten mit einem privaten Schlüssel signiert. Lassen Sie den Verlust dieses Schlüssels für seinen Besitzer unzumutbar sein. Wie kann ein so wertvoller Schlüssel vor dem Verlust durch Remote-Hacking des Systems geschützt werden? Der HSM-Ansatz legt nahe, dass wir dem anfälligen Teil des Systems überhaupt keinen Zugriff auf den Inhalt des Schlüssels gewähren sollten. Ein HSM ist ein physisches Gerät, das selbst digitale Schlüssel oder andere geheime Daten speichert, diese verwaltet, generiert und mit ihnen auch kryptografische Operationen durchführt. Alle Vorgänge an Daten werden innerhalb des HSM ausgeführt und der Benutzer hat nur Zugriff auf die Ergebnisse dieser Vorgänge. Der interne Speicher des Geräts ist vor physischem Zugriff und Hacking geschützt. Bei einem Eindringversuch werden alle sensiblen Daten zerstört.Um HSM nutzen zu können, muss sich der Benutzer authentifizieren. Wenn die Authentifizierung über eine HSM-Clientanwendung durchgeführt wird, die in einem anfälligen Teil des Systems ausgeführt wird, besteht für einen Angreifer die Möglichkeit, das HSM-Passwort abzufangen. Ein abgefangenes Passwort ermöglicht es einem Angreifer, das HSM zu nutzen, ohne an die darin gespeicherten geheimen Daten zu gelangen. Daher empfiehlt es sich, die Authentifizierung unter Umgehung des angreifbaren Teils des Systems durchzuführen, beispielsweise durch die physische Eingabe einer PIN.
Das Haupthindernis für den Einsatz von HSMs sind ihre hohen Kosten. Je nach Geräteklasse kann der Preis zwischen 10 US-Dollar (USB-Token, Smartcards) und über 30.000 US-Dollar (Geräte mit Hardware-Kryptographiebeschleunigung, Hacking-Schutz, Hochverfügbarkeitsfunktionen) variieren. Anbieter von Cloud-Lösungen haben den HSM-Markt nicht ignoriert. Beispielsweise verkauft Amazon sein Cloud-HSM zu einem Durchschnittspreis von 1.373 US-Dollar pro Monat.
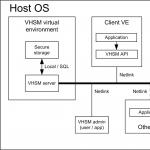
Eines der Hauptmerkmale von HSM ist die Isolierung des anfälligen Teils des Systems, der kryptografische Dienste nutzt, von dem HSM, das diese Dienste ausführt. Beachten Sie, dass einzelne Instanzen (virtuelle Maschinen, Container usw.) in der Cloud voneinander isoliert sind. Wenn wir also die HSM-Funktionen außerhalb der anfälligen Instanz auf eine andere, von der Außenwelt isolierte Instanz verschieben, können wir die Funktionalität ziemlich genau reproduzieren das physische HSM. Wir nennen diesen Ansatz Virtual HSM (VHSM). Schauen wir uns an, wie es von unserem Studenten für das OpenVZ-Projekt implementiert wurde.
Was ist OpenVZ?
OpenVZ ist eine der Technologien zum Ausführen mehrerer isolierter Linux-Betriebssysteme auf einem einzigen Linux-Kernel. Gleichzeitig heißt es, dass jedes Linux-Betriebssystem in einem separaten Container läuft. Um es stark zu vereinfachen: Der Linux-Kernel verfügt tatsächlich über eine integrierte Funktionalität, die es ermöglicht, Anwendungen, die verschiedenen Containern zugewiesen sind, zu isolieren, sodass sie nichts von der Existenz der anderen wissen. Anwendungen können ihren Container nicht ändern. Zur besseren Isolation und Sicherheit ist die Kommunikation zwischen Anwendungen aus verschiedenen Containern über IPC verboten. Dies erfolgt in der Regel über Netzwerkverbindungen. Als Ergebnis sehen wir die Ähnlichkeit von Containern mit „normalen“ virtuellen Maschinen. OpenVZ und darauf basierende Technologien sind bei Hosting-Anbietern für die Erstellung von VPS beliebt. Die Akademische Universität hat bereits Projekte im Zusammenhang mit der Containervirtualisierung durchgeführt. Zum Beispiel . Parallels ist der Hauptentwickler von OpenVZ. Es war ganz natürlich, VHSM speziell für OpenVZ zu implementieren.Virtuelle HSM-Architektur

- Client VE ist ein OpenVZ-Container, in dem Benutzeranwendungen ausgeführt werden, die kryptografische Dienste wie Verschlüsselung, Signierung usw. erfordern. Der Container steht für Remote-Angriffe zum Diebstahl digitaler Schlüssel zur Verfügung.
- Die virtuelle VHSM-Umgebung (VHSM VE) ist ein OpenVZ-Container, in dem der VHSM-Server ausgeführt wird, ein Daemon, der Befehle von Anwendungen in Client VE empfängt und diese ausführt. In VHSM VE werden keine anderen Anwendungen ausgeführt. VHSM VE wird mithilfe von OpenVZ von regulären Benutzercontainern isoliert. Der Container verfügt über keine Netzwerkschnittstellen und ist nicht über das Netzwerk zugänglich.
- Transport ist ein Linux-Kernelmodul, das zum Übertragen von Nachrichten von Client VE zu VHSM VE und zurück entwickelt wurde.
- Die VHSM-API ist eine Bibliothek, die einen Teil der Standard-PKCS #11-Schnittstelle für HSM implementiert, Anwendungsbefehle von ClientVE per Transport an den VHSM-Server überträgt und das Ergebnis des Befehls an die Anwendung in ClientVE zurückgibt.
Virtuelle VHSM-Umgebung
Der VHSM-Server ist für die Authentifizierung von Benutzern, die Interaktion mit dem geheimen Datenspeicher und die Durchführung kryptografischer Vorgänge verantwortlich. Zusätzlich zum VHSM-Server enthält VHSM VE Secure Storage, eine Datenbank, die wichtige Informationen in verschlüsselter Form speichert. Jeder VHSM-Benutzer verfügt über einen eigenen Hauptschlüssel, mit dem seine Daten verschlüsselt werden. Der Hauptschlüssel wird mithilfe der PBKDF2-Funktion aus dem Passwort des Benutzers generiert. Der als Eingabe übergebene Salt wird unverschlüsselt in der Datenbank gespeichert. Daher speichert VHSM den Hauptschlüssel des Benutzers nicht in der Datenbank, und die Verwendung von PBKDF2 verringert die Geschwindigkeit der Brute-Force-Erpressung des ursprünglichen Kennworts des Benutzers bei einem Diebstahl der Datenbank erheblich.Der Benutzer wird in VHSM von einem Administrator registriert, dessen Rolle entweder eine Person oder ein Programm sein kann. Wenn sich ein Benutzer registriert, generiert VHSM einen 256-Bit-Authentifizierungsschlüssel und verschlüsselt ihn mithilfe von AES-GCM mit einem Hauptschlüssel. Als nächstes authentifiziert sich der Benutzer vor der Verwendung von VHSM mit einem Login-Passwort-Paar. Bei der Authentifizierung wird ein aus einem Passwort und einem Salt gebildeter Hauptschlüssel verwendet, um den Authentifizierungsschlüssel des Benutzers zu entschlüsseln. Mithilfe von GCM können Sie die Richtigkeit des Hauptschlüssels während der Entschlüsselung überprüfen. Der Hauptschlüssel wird aus dem Passwort des Benutzers gewonnen. Durch die Überprüfung seiner Richtigkeit können Sie daher das Passwort des Benutzers selbst überprüfen, das bei der Authentifizierung übertragen wird. Nach erfolgreicher Authentifizierung stehen dem Benutzer kryptografische Dienste zur Verfügung, die die im VHSM gespeicherten digitalen Schlüssel des Benutzers verwenden.
VHSM erfordert eine explizite Auswahl von Containern, von denen aus ein bestimmter Benutzer VHSM bedienen kann. Informationen über den Container, von dem der Benutzerbefehl empfangen wird, werden von OpenVZ bereitgestellt.
VHSM-API
Dabei handelt es sich um eine C-Bibliothek, die sich in Benutzercontainern befindet und einen Teil der standardmäßigen PKCS#11-Schnittstelle für HSM implementiert, mit der Sie Schlüssel, Daten, Sitzungen, digitale Signaturen, Verschlüsselung usw. verwalten können. Schauen wir uns ein konkretes Beispiel für die Verwendung der VHSM-API an:- Die Anwendung im benutzerdefinierten Container muss die von ihr gesendete Nachricht signieren.
- Mithilfe der VHSM-API generiert die Anwendung ein öffentlich-privates Schlüsselpaar und erhält die private Schlüssel-ID und den öffentlichen Schlüssel.
- Die Anwendung übergibt die Nachricht an die VHSM-API zum Signieren mit einem privaten Schlüssel mit der erforderlichen ID. Die VHSM-API gibt die signierte Nachricht zurück.
- Die signierte Nachricht und der öffentliche Schlüssel werden an den Empfänger der Nachricht gesendet. In diesem Fall steht der private Schlüssel dem Client-Container nicht zur Verfügung.
VHSM-Transport
Wie oben erwähnt, können Anwendungen, die in verschiedenen Containern ausgeführt werden, nicht über Linux-IPC-Mechanismen miteinander kommunizieren. Um Nachrichten von Clients zum Server und zurück zu transportieren, wurde daher ein ladbares Linux-Kernelmodul implementiert. Das Modul führt den Netlink-Server im Kernel aus, und VHSM-Clients und der VHSM-Server stellen eine Verbindung zu ihm her. Der Netlink-Server ist für die Übertragung von Nachrichten von der Quelle (VHSM-Client) zum Ziel (VHSM-Server) und zurück verantwortlich. Zusammen mit den Nachrichten wird die ID des Nachrichtenquellcontainers angehängt, sodass der Server beispielsweise Anfragen von Containern ablehnen kann, deren Verwendung von VHSM einem bestimmten Benutzer untersagt ist.Abschluss
Der Hauptzweck der Erstellung von VHSM bestand darin, die Möglichkeit auszuschließen, geheime Schlüssel aus dem Speicher von Benutzeranwendungen zu stehlen, die in einem Benutzercontainer ausgeführt werden. Dieses Ziel wurde erreicht, weil Auf geheime Daten kann nur in einem isolierten Container (VHSM VE) zugegriffen werden. Die Isolation wird von OpenVZ implementiert.Ein Datenbankleck von VHSM VE führt nicht zum sofortigen Verlust geheimer Daten, weil sie werden verschlüsselt gespeichert. Der Verschlüsselungsschlüssel wird nicht in der Datenbank gespeichert, sondern aus dem bei der Authentifizierung übermittelten Passwort des Benutzers generiert.
Wie jede Instellt die vorgestellte Lösung eine weitere Barriere für einen Angreifer dar und bietet keinen vollständigen Informationsschutz.
Im Englischen steht es für Uniform Resource Locator, was ins Russische übersetzt „einheitlicher Ressourcen-Locator“ bedeutet. Im Russischen wird diese Abkürzung üblicherweise als „u-er-el“, „yu-ar-el“ oder einfach „url“ ausgesprochen. Versuchen wir genauer zu verstehen, was eine URL ist. Jedes Dokument (Webseite) im Internet hat einen bestimmten Speicherort, der lokalisiert werden kann. Mithilfe einer URL wird der genaue Pfad zu einer bestimmten Webseite angegeben. So wie Sie den Pfad zu einer beliebigen Datei auf Ihrem Computer angeben, wird die URL nach einem bestimmten Muster erstellt, das normalerweise etwa so aussieht:
http://name.ru/papka/document.html
Dabei gibt http die Art des Protokolls an, über das Daten übertragen werden, name.ru bedeutet den Domänennamen der Site, papka ist ein Ordner und document.html ist eine bestimmte Seite, zu der diese URL führt.
Da unsere URL http://name.ru/papka/document.html fiktiv ist, nur als Beispiel dient und dementsprechend zu keiner Webseite führt, werden wir es tun, wenn wir versuchen, darauf zu klicken Sie gelangen auf eine Seite mit Informationen zum Fehler. Es sieht vielleicht anders aus, aber wir werden auf jeden Fall die Aufschrift „404 nicht gefunden“ sehen. „Nicht gefunden“ bedeutet in der Übersetzung „nicht gefunden“, und das Erscheinen einer 404-Seite bedeutet, dass die URL-Adresse der Webseite unvollständig oder falsch (mit einem Fehler oder Tippfehler) eingegeben wurde oder dass sich die angeforderte Seite nicht mehr unter befindet Diese Adresse wurde gelöscht oder umbenannt
Ein 404-Fehler tritt häufig auf, wenn Sie auf einen Link auf einer anderen Seite klicken und der Link veraltet ist. Der Autor der Website hätte das von uns benötigte Dokument verschieben, umbenennen oder löschen können. Was tun, wenn während der Umstellung eine 404-Seite erscheint? Überprüfen Sie zunächst, ob die URL korrekt ist, sofern uns diese bekannt ist. Korrigieren Sie etwaige Fehler oder Tippfehler und versuchen Sie es erneut. Wenn beim Verfolgen eines Links zu einer unbekannten Ressource der Fehler 404 auftritt, sollten Sie versuchen, zur Hauptseite zu gehen und die Site-Suche zu verwenden – es ist möglich, dass die erforderlichen Informationen trotzdem gefunden werden.
Übrigens achten viele Website-Entwickler darauf, dass die 404-Seite auf ihrer Website nicht erschreckend hoffnungslos aussieht. Hier wird ein humorvoller Text mit einem lustigen Bild platziert, um den verlorenen Benutzer aufzumuntern, sowie Links zur Hauptseite, zur Suchleiste oder zur Sitemap. Wenn die 404-Seite unfreundlich aussieht und keine Links darauf vorhanden sind, denen Sie folgen können, können Sie versuchen, die URL manuell zu kürzen und nur den Site-Namen übrig zu lassen – in unserem Beispiel lautet er http://name.ru/ und versuchen Sie daher, ihn abzurufen zur Hauptseite der Website, von wo aus Sie zu der gesuchten Seite gelangen können.
URL(URL, vom englischen Uniform Resource Locator) – ein Index der Website-Platzierung im Internet. Die URL enthält den Domänennamen und den Pfad zur Seite, einschließlich des Dateinamens dieser Seite.
Tim Berners-Lee (Mitglied des European Nuclear Warfare Council in Genf) erfand die URL 1990, die damals lediglich eine Adresse zum Speichern von Dateien im System war.
Neben großen Vorteilen (Verfügbarkeit der Internetnavigation) hat die Seiten-URL auch einen Nachteil: Sie funktioniert nur mit lateinischen Buchstaben, Zahlen und einigen Symbolen. Wenn Sie beispielsweise Kyrillisch verwenden müssen, muss die URL auf besondere Weise neu codiert werden..ru/wiki/%D1%87%D1%82%D0%BE-%D1%82%D0%B0%D0 %BA%D0%BE %D0%B5-url/. Eine solche Kodierung erfolgt in zwei Schritten: Zuerst wird jedes Zeichen in eine Folge von zwei Bytes umgewandelt, dann wird jedes Byte hexadezimal umgeschrieben.
Welche Bedeutung hat die URL einer Website für SEO?
Suchmaschinen berücksichtigen das Vorkommen von Schlüsselphrasen in URLs. Den größten Einfluss haben Vorkommen in der Adresse der Domain und Subdomains; Vorkommen im Pfad zur Seite und im Dateinamen der Seite spielen eine geringere, aber immer noch sehr wichtige Rolle. In diesem Zusammenhang entwickelt sich im Internet aktiv eine Verdienstart namens Cybersquatting. Sein Kern besteht darin, Domainnamen zum Marktwert zu registrieren, um sie anschließend zu einem überhöhten Preis weiterzuverkaufen.
HTTP ist ein Protokoll zur Übertragung von Hypertext zwischen verteilten Systemen. Tatsächlich ist http ein grundlegendes Element des modernen Webs. Als Webentwickler mit Selbstachtung sollten wir so viel wie möglich darüber wissen.
Betrachten wir dieses Protokoll durch die Linse unseres Berufsstandes. Im ersten Teil gehen wir auf die Grundlagen ein und schauen uns Anfragen/Antworten an. Im nächsten Artikel werden wir uns detailliertere Funktionen wie Caching, Verbindungsverarbeitung und Authentifizierung ansehen.
Auch in diesem Artikel werde ich mich hauptsächlich auf den RFC 2616-Standard beziehen: Hypertext Transfer Protocol – HTTP/1.1.
HTTP-Grundlagen
HTTP ermöglicht die Kommunikation zwischen mehreren Hosts und Clients und unterstützt eine Reihe von Netzwerkeinstellungen.
Grundsätzlich wird für die Kommunikation TCP/IP verwendet, dies ist jedoch nicht die einzig mögliche Option. Standardmäßig verwendet TCP/IP Port 80, es können jedoch auch andere verwendet werden.
Die Kommunikation zwischen Host und Client erfolgt in zwei Phasen: Anfrage und Antwort. Der Client generiert eine HTTP-Anfrage, woraufhin der Server eine Antwort (Nachricht) bereitstellt. Etwas später werden wir uns dieses Arbeitsschema genauer ansehen.
Die aktuelle Version des HTTP-Protokolls ist 1.1, in der einige neue Funktionen eingeführt wurden. Meiner Meinung nach sind die wichtigsten davon: Unterstützung einer ständig offenen Verbindung, ein neuer Datenübertragungsmechanismus, Chunked Transfer Encoding, neue Header für das Caching. Einiges davon werden wir uns im zweiten Teil dieses Artikels ansehen.
URL
Der Kern der Webkommunikation ist die Anfrage, die über den Uniform Resource Locator (URL) gesendet wird. Ich bin mir sicher, dass Sie bereits wissen, was eine URL ist, aber der Vollständigkeit halber habe ich beschlossen, ein paar Worte zu sagen. Die URL-Struktur ist sehr einfach und besteht aus folgenden Komponenten:

Das Protokoll kann entweder http für reguläre Verbindungen oder https für einen sichereren Datenaustausch sein. Der Standardport ist 80. Darauf folgt der Pfad zur Ressource auf dem Server und eine Parameterkette.
Methoden
Mithilfe einer URL definieren wir den genauen Namen des Hosts, mit dem wir kommunizieren möchten. Welche Aktion wir ausführen müssen, kann jedoch nur über die HTTP-Methode kommuniziert werden. Natürlich gibt es verschiedene Arten von Maßnahmen, die wir ergreifen können. HTTP implementiert das Notwendigste und ist für die Anforderungen der meisten Anwendungen geeignet.
Bestehende Methoden:
ERHALTEN: Auf eine vorhandene Ressource zugreifen. Die URL listet alle notwendigen Informationen auf, damit der Server die angeforderte Ressource finden und als Antwort zurückgeben kann.
POST: Wird zum Erstellen einer neuen Ressource verwendet. Eine POST-Anfrage enthält normalerweise alle notwendigen Informationen zum Erstellen einer neuen Ressource.
SETZEN: Aktualisiert die aktuelle Ressource. Die PUT-Anfrage enthält die zu aktualisierenden Daten.
LÖSCHEN: Wird zum Löschen einer vorhandenen Ressource verwendet.
Diese Methoden sind die beliebtesten und werden am häufigsten von verschiedenen Tools und Frameworks verwendet. In einigen Fällen werden PUT- und DELETE-Anfragen durch Senden eines POST gesendet, dessen Inhalt die Aktion angibt, die für die Ressource ausgeführt werden muss: Erstellen, Aktualisieren oder Löschen.
HTTP unterstützt auch andere Methoden:
KOPF: Ähnlich wie GET. Der Unterschied besteht darin, dass bei dieser Art der Anfrage keine Nachricht übermittelt wird. Der Server empfängt nur die Header. Wird beispielsweise verwendet, um festzustellen, ob eine Ressource geändert wurde.
VERFOLGEN: Während der Übertragung durchläuft die Anfrage viele Zugangspunkte und Proxyserver, von denen jeder seine eigenen Informationen eingibt: IP, DNS. Mit dieser Methode können Sie alle Zwischeninformationen sehen.
OPTIONEN: Wird zum Definieren von Serverfunktionen, Einstellungen und Konfiguration für eine bestimmte Ressource verwendet.
Statuscodes
Auf eine Anfrage des Clients sendet der Server eine Antwort, die auch einen Statuscode enthält. Dieser Code hat eine besondere Bedeutung, damit der Kunde die Antwort besser verstehen kann:
1xx: Informationsmeldungen
Eine Reihe dieser Codes wurde in HTTP/1.1 eingeführt. Der Server kann eine Anfrage der Form senden: Expect: 100-continue, was bedeutet, dass der Client immer noch den Rest der Anfrage sendet. Clients, die HTTP/1.0 ausführen, ignorieren diese Header.
2xx: Erfolgsmeldungen
Wenn der Client einen Code aus der 2xx-Serie erhalten hat, wurde die Anfrage erfolgreich gesendet. Die häufigste Option ist 200 OK. Bei einer GET-Anfrage sendet der Server eine Antwort im Nachrichtentext. Es gibt auch andere mögliche Antworten:
- 202 Akzeptiert: Die Anfrage wird angenommen, die Ressource ist jedoch möglicherweise nicht in der Antwort enthalten. Dies ist nützlich für asynchrone Anfragen auf der Serverseite. Der Server bestimmt, ob die Ressource gesendet werden soll oder nicht.
- 204 Kein Inhalt: Der Antworttext enthält keine Nachricht.
- 205 Inhalt zurücksetzen: Weist den Server an, die Präsentation des Dokuments zurückzusetzen.
- 206 Teilinhalt: Die Antwort enthält nur einen Teil des Inhalts. Zusätzliche Header bestimmen die Gesamtlänge des Inhalts und anderer Informationen.
3xx: Weiterleiten
Eine Art Mitteilung an den Kunden über die Notwendigkeit, noch eine weitere Maßnahme zu ergreifen. Der häufigste Anwendungsfall besteht darin, den Client an eine andere Adresse umzuleiten.
- 301 Dauerhaft verschoben: Die Ressource ist jetzt unter einer anderen URL zu finden.
- 303 Siehe Andere: Die Ressource ist vorübergehend unter einer anderen URL zu finden. Der Location-Header enthält eine temporäre URL.
- 304 Nicht geändert: Der Server stellt fest, dass die Ressource nicht geändert wurde und der Client die zwischengespeicherte Version der Antwort verwenden muss. Um die Identität von Informationen zu überprüfen, wird ETag (Entity Tag Hash) verwendet.
4xx: Clientfehler
Diese Nachrichtenklasse wird vom Server verwendet, wenn er entscheidet, dass die Anfrage fehlerhaft gesendet wurde. Der häufigste Code ist 404 Nicht gefunden. Dies bedeutet, dass die Ressource nicht auf dem Server gefunden wurde. Weitere mögliche Codes:
- 400 Ungültige Anfrage: Die Frage wurde falsch formuliert.
- 401 nicht Autorisiert: Für eine Anfrage ist eine Authentifizierung erforderlich. Informationen werden über den Authorization-Header übertragen.
- 403 Verboten: Der Server hat den Zugriff auf die Ressource nicht zugelassen.
- 405 Methode nicht zulässig: Für den Zugriff auf die Ressource wurde eine ungültige HTTP-Methode verwendet.
- 409 Konflikt: Der Server kann die Anfrage nicht vollständig verarbeiten, weil versucht, eine neuere Version einer Ressource zu ändern. Dies passiert häufig bei PUT-Anfragen.
5xx: Serverfehler
Eine Reihe von Codes, die zur Erkennung eines Serverfehlers bei der Verarbeitung einer Anfrage verwendet werden. Am häufigsten: 500 Interner Serverfehler. Andere Optionen:
- 501 Nicht implementiert: Der Server unterstützt die angeforderte Funktionalität nicht.
- 503 Dienst nicht verfügbar: Dies kann passieren, wenn der Server einen Fehler hat oder überlastet ist. Normalerweise antwortet der Server in diesem Fall nicht und die für die Antwort angegebene Zeit läuft ab.
Anfrage-/Antwortnachrichtenformate
Im folgenden Bild sehen Sie einen schematischen Ablauf des Sendens einer Anfrage durch den Client, der Verarbeitung und des Sendens einer Antwort durch den Server.

Schauen wir uns den Aufbau einer über HTTP übertragenen Nachricht an:
Nachricht =
Zwischen Kopf und Text der Nachricht muss eine Leerzeile stehen. Es kann mehrere Überschriften geben:
Der Antworttext kann alle oder einen Teil der Informationen enthalten, wenn die entsprechende Funktion aktiviert ist (Transfer-Encoding: chunked). HTTP/1.1 unterstützt auch den Transfer-Encoding-Header.
Allgemeine Überschriften
Hier sind verschiedene Arten von Headern, die sowohl in Anfragen als auch in Antworten verwendet werden:
General-header = Cache-Control | Verbindung | Datum | Pragma | Anhänger | Transfer-Kodierung | Upgrade | Über | Warnung
Einige Dinge haben wir in diesem Artikel bereits behandelt, einige werden wir im zweiten Teil genauer besprechen.
Der Via-Header wird in einer TRACE-Anfrage verwendet und von allen Proxyservern aktualisiert.
Der Pragma-Header wird zum Auflisten benutzerdefinierter Header verwendet. Beispielsweise ist Pragma: no-cache dasselbe wie Cache-Control: no-cache. Wir werden im zweiten Teil mehr darüber sprechen.
Der Date-Header wird zum Speichern von Datum und Uhrzeit der Anfrage/Antwort verwendet.
Der Upgrade-Header wird zum Ändern des Protokolls verwendet.
Transfer-Encoding soll die Antwort mithilfe von Transfer-Encoding: chunked in mehrere Blöcke aufteilen. Dies ist eine neue Funktion in HTTP/1.1.
Entitätsheader
Entitätsheader übermitteln Metainformationen zum Inhalt:
Entity-header = Zulassen | Inhaltskodierung | Inhaltssprache | Inhaltslänge | Inhaltsort | Inhalt-MD5 | Inhaltsbereich | Inhaltstyp | Läuft ab | Zuletzt bearbeitet
Alle Header mit dem Präfix „Content-“ liefern Informationen über die Struktur, Codierung und Größe des Nachrichtentexts.
Der Expires-Header enthält die Ablaufzeit und das Ablaufzeitdatum der Entität. Der Wert „läuft nie ab“ bedeutet Zeit + 1 Code ab dem aktuellen Zeitpunkt. Zuletzt geändert enthält die Uhrzeit und das Datum der letzten Änderung der Entität.
Mithilfe dieser Header können Sie die für Ihre Aufgaben erforderlichen Informationen angeben.
Anfrageformat
Die Anfrage sieht in etwa so aus:
Request-Line = Methode SP URI SP HTTP-Version CRLF Methode = „OPTIONS“ | „KOPF“ | „GET“ | „POST“ | „PUT“ | „LÖSCHEN“ | "VERFOLGEN"
SP ist das Trennzeichen zwischen Token. Die HTTP-Version wird in HTTP-Version angegeben. Die eigentliche Anfrage sieht so aus:
GET /articles/http-basics HTTP/1.1 Host: www.articles.com Verbindung: keep-alive Cache-Steuerung: no-cache Pragma: no-cache Accept: text/html,application/xhtml+xml,application/xml; q=0,9,*/*;q=0,8
Liste möglicher Anforderungsheader:
Anforderungsheader = Akzeptieren | Accept-Charset | Akzeptieren-Kodierung | Accept-Language | Autorisierung | Erwarten | Von | Gastgeber | If-Match | Wenn-geändert-seit | If-None-Match | If-Bereich | Wenn-unverändert-seit | Max-Forwards | Proxy-Autorisierung | Reichweite | Referrer | TE | User-Agent
Der Accept-Header gibt die unterstützten MIME-Typen, die Sprache und die Zeichenkodierung an. Die Header „From“, „Host“, „Referer“ und „User-Agent“ enthalten Informationen über den Client. If-Präfixe sollen Bedingungen schaffen. Wenn die Bedingung nicht erfüllt ist, tritt der Fehler 304 Not Modified auf.
Antwortformat
Das Antwortformat unterscheidet sich lediglich im Status und in einigen Headern. Der Status sieht so aus:
Statuszeile = HTTP-Version SP-Statuscode SP-Grundphrase CRLF
- HTTP-Version
- Statuscode
- Für Menschen lesbare Statusmeldung
Der Normalzustand sieht etwa so aus:
HTTP/1.1 200 OK
Die Antwortheader können wie folgt lauten:
Response-header = Accept-Ranges | Alter | ETag | Standort | Proxy-Authentifizieren | Wiederholen nach | Server | Variieren | WWW-Authentifizieren
- Das Alter ist die Zeit in Sekunden, zu der die Nachricht auf dem Server erstellt wurde.
- Markieren Sie MD5-Entitäten mit einem ETag, um nach Änderungen und Modifikationen an der Antwort zu suchen.
- Der Standort wird für die Umleitung verwendet und enthält die neue URL.
- Server gibt den Server an, auf dem die Antwort generiert wurde.
Ich denke, das ist genug Theorie für heute. Werfen wir nun einen Blick auf die Tools, mit denen wir HTTP-Nachrichten überwachen können.
Tools zur Erkennung von HTTP-Verkehr
Es gibt viele Tools zur Überwachung des HTTP-Verkehrs. Hier sind einige davon:
Am häufigsten werden die Chrome Developers Tools verwendet:

Wenn wir über einen Debugger sprechen, können Sie Fiddler verwenden:

Um den HTTP-Verkehr zu überwachen, benötigen Sie curl, tcpdump und tshark.
Bibliotheken für die Arbeit mit HTTP – jQuery AJAX
Da jQuery so beliebt ist, verfügt es auch über Tools zur Verarbeitung von HTTP-Antworten für AJAX-Anfragen. Informationen zu jQuery.ajax(Einstellungen) finden Sie auf der offiziellen Website.
Durch Übergabe eines Einstellungsobjekts und Verwendung der Callback-Funktion beforeSend können wir die Anforderungsheader mithilfe der Methode setRequestHeader() festlegen.
$.ajax(( URL: „http://www.articles.com/latest“, Typ: „GET“, beforeSend: Funktion (jqXHR) ( jqXHR.setRequestHeader(“Accepts-Language“, „en-US,en "); ) ));
Wenn Sie den Anfragestatus bearbeiten möchten, können Sie dies wie folgt tun:
$.ajax(( statusCode: ( 404: function() ( Alert("Seite nicht gefunden"); ) ) ));
Endeffekt
Hier ist es, eine Tour durch die Grundlagen des HTTP-Protokolls. Der zweite Teil wird noch mehr interessante Fakten und Beispiele enthalten.
Fast jeder Benutzer, der im Internet arbeitet, stößt auf Hinweise darauf URL, URLs, Einladungen, zu einem Link zu gehen und den Link zu verwenden. Für diejenigen, die mit diesen Konzepten nicht vertraut oder neu sind, habe ich beschlossen, ein Material zu schreiben, in dem ich erkläre, was eine URL ist, wie man eine URL verwendet, in welche Teile eine URL unterteilt ist und wie man sie findet den richtigen Link im Internet.
URL- Dies ist eine Adresse, die den Pfad zu einer Internetressource angibt, auf der sich verschiedene Dateitypen befinden (Dokumente, Bilder, Videos, Audio usw.). Die Abkürzung URL steht für „Uniform Resource Locator“, im Russischen wird sie meist als „url“, „yu-ar-el“, „u-er-el“ ausgesprochen, oft wird einfach das Wort „Link“ verwendet.
Ich erinnere mich, dass ich vor einiger Zeit nach einer URL-Adresse gesucht habe, um meinem Bruder kompetent alle Feinheiten des Konzepts zu erklären. Und ich selbst wurde interessiert, als dieser Begriff auftauchte.
Der Autor des URL-Konzepts ist der Brite Tim Bernes-Lee, und die Erfindung selbst (1990) markierte einen qualitativen Sprung in der Entwicklung von Internet-Technologien. Mittlerweile ist die URL eine Kennung der Adressen fast aller Ressourcen im Netzwerk, während der Begriff URL selbst nach und nach durch den umfangreicheren Begriff URI (Uniform Resource Identifier) ersetzt wird.
URLs von Social-Media-Beiträgen

In welche Teile ist eine URL unterteilt?
Ein klassisches Beispiel für eine URL sieht etwa so aus:
http://site_address/folder/page.html
Wie Sie sehen, ist die URL in mehrere Teile unterteilt:
Erster Teil (http://) definiert das zu verwendende Protokoll. Einfach ausgedrückt geht es um die Methode, die verwendet wird, um Zugriff auf die gewünschte Ressource zu erhalten.
Das in dieser URL verwendete „HTTP“-Protokoll steht für „HyperText Transfer Protocol“ und wird in den allermeisten Fällen verwendet. Sie können aber auch URLs finden, die andere Protokolle verwenden, zum Beispiel FTP (File Transfer Protocol), HTTPS (HyperText Transfer Protocol Secure – eine sichere, verschlüsselte Version von HTTP), mailto (E-Mail-Adresse) und andere.
Insgesamt gibt es mehrere Dutzend Arten von URL-Protokollen: FTP, http, RTMP, RTSP, https, Gopher, Mailto, News, NNTP, SMB, Prospero, Telnet, Wais, XMPP, File, Data usw., normalerweise jedoch mehrere Es werden grundlegende verwendet, die von mir etwas weiter oben aufgeführt sind.

Zweiter Teil(Webseitenadressse) ist der Domänenname. Technisch gesehen ist es nur eine Reihe von Symbolen, Buchstaben oder einer Wortkombination, die es den Leuten ermöglicht, sich leicht an die Adresse ihrer Lieblingsseite zu erinnern. Andernfalls würden Links zu Ressourcen wie folgt aussehen: http://192.168.384.
Dritter Teil (folder/page.html) verweist normalerweise auf eine Ressourcenseite, auf die der Benutzer zugreifen möchte. Es kann einfach die Form eines Namens oder die Form eines Pfads zu einer bestimmten Datei über eine Reihe von Ordnern haben, letztere normalerweise durch einen Schrägstrich (/) getrennt. Die Erweiterung von Internetseiten kann unterschiedlich sein – PHP, HTM, HTML, SHTML, ASP und viele andere.
Diese Erklärungen sind im Video anschaulich zu sehen:
Abkürzungen, die vor dem Domainnamen verwendet werden www(World Wide Web) ist nicht obligatorisch, Sie können die Site-Adresse auch ohne sie verwenden, die Site wird auf jeden Fall geöffnet.
Merkmale der Verwendung einer URL-Adresse
Wenn die vom Benutzer angegebene URL nicht korrekt ist, zeigt uns das System einen 404-Fehler mit dem Hinweis „Seite nicht gefunden!“ an. Dies bedeutet, dass der Benutzer entweder die falsche oder veraltete Seitenadresse eingegeben hat. Daher sind bei der Eingabe der Adresse Genauigkeit, Genauigkeit und Aufmerksamkeit erforderlich. Beim Eingeben einer URL würde ich empfehlen, die Seitenadresse mit den Funktionen „Kopieren/Einfügen“ zu kopieren. Sie können auch versuchen, eine verkürzte URL nur in Form des Hauptnamens der Site (ohne Ordner und Seiten) einzugeben und auf der Hauptseite der Site nach einem Link zu der Seite zu suchen, die wir benötigen.

Nachteile von URLs
Nachdem wir beschrieben haben, dass es sich um einen URL-Link handelt, schauen wir uns nun alle Nachteile einer URL an. Neben den Vorteilen einer einfacheren Navigation im Internet haben URLs auch ihre eigenen Nachteile. Dies funktioniert nur mit Zahlen, lateinischen Buchstaben und einigen Symbolen. Das kyrillische Alphabet muss normalerweise in zwei Schritten neu kodiert werden (URL-Kodierung), wobei im ersten Schritt jedes kyrillische Zeichen in zwei Bytes umgewandelt wird und dann jedes der Bytes mit umgeschrieben wird das Hexadezimalsystem.
Darüber hinaus wird empfohlen, in der Adresse überwiegend Kleinbuchstaben zu verwenden (einige Unix-Systeme werden ihre Großbuchstabenvarianten als unterschiedliche Zeichen wahrnehmen, was zu einem Fehler beim Öffnen der Seite führen kann), und es ist auch verboten, Leerzeichen in URL-Adressen zu verwenden.
So finden Sie eine URL-Adresse. Lesezeichen.
Um die benötigte URL-Adresse zu finden, können Sie Suchmaschinen nutzen, in die Sie die Schlüsselwörter Ihrer Suche eingeben müssen. Wenn Sie beispielsweise einen Film benötigen, geben Sie dessen Namen oder die Namen der Schauspieler ein, bei Musik die Namen der Interpreten und den Namen der Komposition. Wenn Sie auf „Suchen“ klicken, erhalten Sie viele Websites mit URL-Adressen. Wenn Sie darauf klicken, finden Sie das gewünschte Ergebnis.
Die URL der Seite, auf der Sie sich gerade befinden, finden Sie oben in der Adressleiste Ihres Browsers.
Um sich die URL der benötigten Seite zu merken, verwenden Sie die Lesezeichenleiste Ihres Browsers. Im beliebten Browser Mozilla Firefox befindet sich beispielsweise das Lesezeichensymbol in Form eines Sternchens oben rechts auf der Ebene der Adressleiste. Wenn Sie darauf klicken, können Sie einen Namen für Ihr Lesezeichen sowie einen Ordner eingeben, in dem die Lesezeichen abgelegt werden sollen (normalerweise verwende ich ein spezielles Lesezeichenfenster, über das Sie mit einem Klick auf jedes Lesezeichen zugreifen können).
Abschluss
Die Verwendung von URLs hat das Surfen im Internet erheblich vereinfacht und vielen Benutzern den einfachen und schnellen Zugriff auf die benötigten Websites ermöglicht. Wenn Sie nach dem Lesen des Artikels „Was ist eine URL-Adresse?“ noch Fragen haben, schreiben Sie diese in die Kommentare zum Artikel.
Heutzutage muss lediglich der Name der Site und ihre Erweiterung in die Adressleiste eingegeben werden, woraufhin der Benutzer fast sofort Zugriff auf die Ressource erhält. Und das alles, ohne sich eine ziemlich komplexe Reihe dreistelliger Zahlen merken zu müssen, alles geht einfach, schnell und effizient – im Allgemeinen das, was benötigt wird, nicht wahr?
In Kontakt mit