Көрсеткіштер- бұл сіздің жұмысыңызда жақсы түсінуіңіз керек бірінші нәрсе SQL сервері, бірақ біртүрлі негізгі сұрақтар форумдарда жиі қойылмайды және көп жауап ала алмайды.
Роб Шелдониндекстер туралы кәсіби ортада шатасушылық тудыратын осы сұрақтарға жауап береді SQL сервері: олардың кейбірін сұрауға ұяламыз, ал басқаларынан сұрамас бұрын алдымен екі рет ойланамыз.
Қолданылатын терминология:
| индекс | индекс |
| үйме | бір топ |
| кесте | кесте |
| көрініс | өнімділік |
| В-ағаш | теңдестірілген ағаш |
| кластерленген индекс | кластерленген индекс |
| кластерленбеген индекс | кластерленбеген индекс |
| құрама индекс | құрама индекс |
| қамту көрсеткіші | қамту көрсеткіші |
| негізгі кілт шектеуі | негізгі кілт шектеуі |
| бірегей шектеу | құндылықтардың бірегейлігін шектеу |
| сұрау | сұрау |
| сұрау қозғалтқышы | сұраудың ішкі жүйесі |
| дерекқор | мәліметтер базасы |
| деректер базасының қозғалтқышы | сақтаудың ішкі жүйесі |
| толтыру коэффициенті | индексті толтыру коэффициенті |
| суррогат бастапқы кілт | суррогат бастапқы кілт |
| сұрауды оңтайландырушы | сұрауды оңтайландырушы |
| индекстің селективтілігі | индекстің селективтілігі |
| фильтрленген индекс | сүзілетін индекс |
| орындау жоспары | орындау жоспары |
SQL серверіндегі индекстердің негіздері.
Жоғары өнімділікке жетудің маңызды жолдарының бірі SQL серверіиндекстерді қолдану болып табылады. Кітаптағы индекс сізге қажет ақпаратты жылдам табуға көмектесетіндей, индекс кестедегі деректер жолына жылдам қол жеткізуді қамтамасыз ету арқылы сұрау процесін жылдамдатады. Бұл мақалада мен индекстерге қысқаша шолу беремін SQL серверіжәне олардың дерекқорда қалай ұйымдастырылғанын және олардың дерекқор сұрауларын жылдамдатуға қалай көмектесетінін түсіндіріңіз.
Индекстер кесте және көрініс бағандарында құрылады. Индекстер сол бағандардағы мәндер негізінде деректерді жылдам іздеуге мүмкіндік береді. Мысалы, егер сіз бастапқы кілтте индекс жасап, содан кейін бастапқы кілт мәндерін пайдаланып деректер жолын іздесеңіз, онда SQL серверіалдымен индекс мәнін табады, содан кейін деректердің барлық жолын жылдам табу үшін индексті пайдаланады. Индекссіз кестедегі барлық жолдарды толық сканерлеу орындалады, бұл өнімділікке айтарлықтай әсер етуі мүмкін.
Кестедегі немесе көріністегі көптеген бағандарда индекс жасай аласыз. Ерекшелік негізінен үлкен нысандарды сақтауға арналған деректер түрлері бар бағандар болып табылады ( LOB), сияқты сурет, мәтіннемесе varchar(макс). Сондай-ақ, деректерді пішімде сақтауға арналған бағандарда индекстер жасауға болады XML, бірақ бұл индекстер стандарттыдан сәл басқаша құрылымдалған және оларды қарастыру осы мақаланың ауқымынан тыс. Сондай-ақ, мақала талқыланбайды бағандар дүкеніиндекстер. Оның орнына мен дерекқорларда жиі қолданылатын индекстерге назар аударамын SQL сервері.
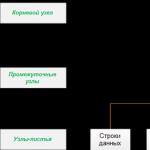
Индекс ағаш құрылымында ұйымдастырылған беттер жиынтығынан, индекс түйіндерінен тұрады - теңдестірілген ағаш. Бұл құрылым иерархиялық сипатта болады және суретте көрсетілгендей иерархияның жоғарғы жағындағы түбір түйінінен және жапырақ түйіндерінен, төменгі жағындағы жапырақтардан басталады:
Индекстелген бағанды сұраған кезде, сұрау жүйесі түбірлік түйіннің жоғарғы жағынан басталады және аралық түйіндер арқылы төмен қарай жұмыс істейді, әрбір аралық қабат деректер туралы толығырақ ақпаратты қамтиды. Сұрау механизмі индекс жапырақтарымен төменгі деңгейге жеткенше индекс түйіндері арқылы жылжуын жалғастырады. Мысалы, индекстелген бағандағы 123 мәнін іздесеңіз, сұрау жүйесі алдымен түбірлік деңгейдегі бірінші аралық деңгейдегі бетті анықтайды. Бұл жағдайда бірінші бет 1-ден 100-ге дейінгі мәнді, ал екіншісі 101-ден 200-ге дейінгі мәнді көрсетеді, сондықтан сұрау жүйесі осы аралық деңгейдің екінші бетіне қол жеткізеді. Содан кейін сіз келесі аралық деңгейдің үшінші бетіне өтуіңіз керек екенін көресіз. Осы жерден сұраудың ішкі жүйесі индекстің мәнін төменгі деңгейде оқиды. Индекс жапырақтары индекс түріне байланысты кесте деректерінің өзін немесе жай ғана кестедегі деректері бар жолдарға көрсеткішті қамтуы мүмкін: кластерленген индекс немесе кластерленбеген индекс.
Кластерлік индекс
Кластерленген индекс деректердің нақты жолдарын индекстің жапырақтарында сақтайды. Алдыңғы мысалға оралсақ, бұл 123 кілт мәнімен байланысты деректер жолы индекстің өзінде сақталатынын білдіреді. Кластерленген индекстің маңызды сипаттамасы барлық мәндердің өсу немесе кему бойынша белгілі бір ретпен сұрыпталуы болып табылады. Сондықтан кестеде немесе көріністе тек бір кластерленген индекс болуы мүмкін. Сонымен қатар, кестедегі деректер осы кестеде кластерленген индекс жасалған жағдайда ғана сұрыпталған түрде сақталатынын ескеру қажет.
Кластерленген индексі жоқ кесте үйме деп аталады.
Кластерленбеген индекс
Кластерленген индекстен айырмашылығы, кластерленбеген индекстің жапырақтары тек сол бағандарды ( кілт) ол арқылы осы индекс анықталады, сонымен қатар кестедегі нақты деректері бар жолдарға көрсеткіш бар. Бұл ішкі сұрау жүйесі қажетті деректерді табу және алу үшін қосымша операцияны қажет ететінін білдіреді. Деректер көрсеткішінің мазмұны деректердің қалай сақталатынына байланысты: кластерленген кесте немесе үйме. Көрсеткіш кластерленген кестені көрсетсе, ол нақты деректерді табу үшін пайдалануға болатын кластерленген индексті көрсетеді. Егер көрсеткіш үйіндіге сілтеме жасаса, ол белгілі бір деректер жолының идентификаторын көрсетеді. Кластерленбеген индекстерді кластерленген индекстер сияқты сұрыптау мүмкін емес, бірақ кестеде немесе көріністе 999-ға дейін бірнеше кластерленбеген индекстер жасауға болады. Бұл мүмкіндігінше көп индекстер жасау керек дегенді білдірмейді. Индекстер жүйе өнімділігін жақсартуы немесе нашарлатуы мүмкін. Бірнеше кластерленбеген индекстерді жасау мүмкіндігінен басқа, қосымша бағандарды да қосуға болады ( енгізілген баған) оның индексіне: индекс жапырақтары индекстелген бағандардың мәнін ғана емес, сонымен қатар осы индекстелмеген қосымша бағандардың мәндерін де сақтайды. Бұл тәсіл индекске қойылған кейбір шектеулерді айналып өтуге мүмкіндік береді. Мысалы, индекстелмейтін бағанды қосуға немесе индекс ұзындығы шегін айналып өтуге болады (көп жағдайда 900 байт).
Индекстердің түрлері
Кластерленген немесе кластерленбеген болумен қатар, индексті құрамдас индекс, бірегей индекс немесе қамту индексі ретінде одан әрі конфигурациялауға болады.
Құрама индекс
Мұндай индексте бірнеше баған болуы мүмкін. Индекске 16 бағанға дейін қосуға болады, бірақ олардың жалпы ұзындығы 900 байтпен шектеледі. Кластерленген және кластерленбеген индекстер құрама болуы мүмкін.
Бірегей көрсеткіш
Бұл индекс индекстелген бағандағы әрбір мәннің бірегей болуын қамтамасыз етеді. Егер индекс құрамды болса, бірегейлік әрбір жеке бағанға емес, индекстегі барлық бағандарға қолданылады. Мысалы, бағандарда бірегей индекс жасасаңыз NAMEЖәне ТЕГІ, содан кейін толық аты бірегей болуы керек, бірақ аты немесе тегі қайталануы мүмкін.
Бірегей индекс баған шектеуін анықтаған кезде автоматты түрде жасалады: бастапқы кілт немесе бірегей мән шектеуі:
- Негізгі кілт
Бір немесе бірнеше бағандарда бастапқы кілт шектеуін анықтаған кезде SQL серверікластерленген индекс бұрын жасалмаған болса, бірегей кластерленген индексті автоматты түрде жасайды (бұл жағдайда бірегей кластерленбеген индекс бастапқы кілтте жасалады) - Құндылықтардың бірегейлігі
Сіз құндылықтардың бірегейлігіне шектеуді анықтаған кезде SQL серверібірегей кластерлік емес индексті автоматты түрде жасайды. Кестеде әлі кластерленген индекс жасалмаған болса, бірегей кластерленген индекс жасалатынын көрсетуге болады.
Қамту индексі
Мұндай индекс нақты сұранысқа кестенің жазбаларына қосымша рұқсатсыз индекстің жапырақтарынан барлық қажетті деректерді дереу алуға мүмкіндік береді.
Индекстерді жобалау
Индекстер қаншалықты пайдалы болса да, оларды мұқият құрастыру керек. Индекстер айтарлықтай дискілік кеңістікті алуы мүмкін болғандықтан, қажеттен көбірек индекстер жасағыңыз келмейді. Бұған қоса, деректер жолының өзі жаңартылған кезде индекстер автоматты түрде жаңартылады, бұл қосымша ресурс шығындарына және өнімділіктің төмендеуіне әкелуі мүмкін. Индекстерді құрастырған кезде деректер қорына және оған қарсы сұрауларға қатысты бірнеше ойларды ескеру қажет.
Мәліметтер базасы
Жоғарыда айтылғандай, индекстер жүйе өнімділігін жақсарта алады, себебі... олар сұрау жүйесін деректерді табудың жылдам әдісімен қамтамасыз етеді. Дегенмен, деректерді енгізу, жаңарту немесе жою жиілігін де ескеру қажет. Деректерді өзгерткен кезде, жүйе өнімділігін айтарлықтай төмендетуі мүмкін деректердегі сәйкес әрекеттерді көрсету үшін индекстер де өзгертілуі керек. Индекстеу стратегияңызды жоспарлау кезінде келесі нұсқауларды қарастырыңыз:
- Жиі жаңартылатын кестелер үшін мүмкіндігінше аз индекстерді пайдаланыңыз.
- Кесте деректердің үлкен көлемін қамтыса, бірақ өзгерістер шамалы болса, сұрауларыңыздың өнімділігін жақсарту үшін қажетінше көптеген индекстерді пайдаланыңыз. Дегенмен, шағын кестелерде индекстерді қолданбас бұрын мұқият ойластырыңыз, себебі... Индексті іздеуді пайдалану барлық жолдарды сканерлеуден гөрі ұзағырақ уақыт алуы мүмкін.
- Кластерленген индекстер үшін өрістерді мүмкіндігінше қысқа ұстауға тырысыңыз. Ең жақсы әдіс бірегей мәндері бар және NULL мәніне жол бермейтін бағандарда кластерленген индексті пайдалану болып табылады. Сондықтан бастапқы кілт жиі кластерленген индекс ретінде пайдаланылады.
- Бағандағы мәндердің бірегейлігі индекстің өнімділігіне әсер етеді. Жалпы, бағандағы көшірмелер неғұрлым көп болса, индекс соғұрлым нашар болады. Екінші жағынан, бірегей мәндер неғұрлым көп болса, индекстің өнімділігі соғұрлым жақсы болады. Мүмкіндігінше бірегей индексті пайдаланыңыз.
- Құрама индекс үшін индекстегі бағандардың ретін ескеріңіз. Өрнектерде қолданылатын бағандар ҚАЙДА(Мысалыға, WHERE аты = 'Чарли') индексте бірінші болуы керек. Кейінгі бағандар олардың мәндерінің бірегейлігіне негізделуі керек (бірегей мәндердің ең көп саны бар бағандар бірінші орында).
- Сондай-ақ, егер олар белгілі талаптарға сай болса, есептелген бағандарда индексті көрсетуге болады. Мысалы, бағанның мәнін алу үшін пайдаланылатын өрнектер детерминирленген болуы керек (берілген кіріс параметрлері жиыны үшін әрқашан бірдей нәтижені қайтарыңыз).
Мәліметтер қорының сұраулары
Индекстерді құрастыру кезінде ескерілетін тағы бір мәселе - дерекқорға қарсы қандай сұраулар орындалады. Жоғарыда айтылғандай, деректердің қаншалықты жиі өзгеретінін ескеру керек. Сонымен қатар, келесі принциптерді пайдалану керек:
- Бірнеше жалғыз сұрауда емес, бір сұрауға мүмкіндігінше көп жолдарды кірістіруге немесе өзгертуге тырысыңыз.
- Сұрауларыңызда іздеу шарттары ретінде жиі пайдаланылатын бағандарда кластерленбеген индексті жасаңыз. ҚАЙДАжәне ішіндегі байланыстар ҚОСЫЛУ.
- Нақты мән сәйкестіктері үшін жолды іздеу сұрауларында пайдаланылатын индекстеу бағандарын қарастырыңыз.
Неліктен кестеде екі кластерлік индекс болуы мүмкін емес?
Қысқа жауап алғыңыз келе ме? Кластерленген индекс кесте болып табылады. Кестеде кластерленген индексті жасағанда, сақтау механизмі индекс анықтамасына сәйкес кестедегі барлық жолдарды өсу немесе кему ретімен сұрыптайды. Кластерленген индекс басқа индекстер сияқты бөлек нысан емес, кестедегі деректерді сұрыптауға және деректер жолдарына жылдам қол жеткізуді жеңілдетуге арналған механизм.
Сізде сату операцияларының тарихын қамтитын кесте бар деп елестетіп көрейік. Сату кестесіне тапсырыс идентификаторы, тапсырыстағы өнім орны, өнім нөмірі, өнім саны, тапсырыс нөмірі мен күні, т.б. Бағандарда кластерленген индекс жасайсыз Тапсырыс идентификаторыЖәне LineID, төменде көрсетілгендей өсу ретімен сұрыпталған T-SQLкод:
Осы сценарийді іске қосқан кезде кестедегі барлық жолдар алдымен OrderID бағаны бойынша, содан кейін LineID арқылы физикалық түрде сұрыпталады, бірақ деректердің өзі бір логикалық блокта, кестеде қалады. Осы себепті екі кластерленген индекс жасай алмайсыз. Бір деректерден тұратын бір ғана кесте болуы мүмкін және бұл кестені белгілі бір ретпен тек бір рет сұрыптауға болады.
Егер кластерленген кесте көптеген артықшылықтарды қамтамасыз етсе, онда үйіндіні не үшін пайдалану керек?
Сіз дұрыс айтасыз. Кластерленген кестелер тамаша және сұрауларыңыздың көпшілігі кластерленген индексі бар кестелерде жақсырақ орындалады. Бірақ кейбір жағдайларда кестелерді табиғи, таза күйінде қалдырғыңыз келуі мүмкін, яғни. үйме түрінде және сұрауларыңызды іске қосу үшін тек кластерлік емес индекстерді жасаңыз.
Үйме, есіңізде болса, деректерді кездейсоқ ретпен сақтайды. Әдетте, сақтау ішкі жүйесі деректерді кірістірілген ретпен кестеге қосады, бірақ сақтау ішкі жүйесі сонымен қатар тиімдірек сақтау үшін жолдарды жылжытуды ұнатады. Нәтижесінде деректердің қандай ретпен сақталатынын болжауға мүмкіндігіңіз жоқ.
Сұрау механизмі деректерді кластерлік емес индекссіз табу қажет болса, ол қажетті жолдарды табу үшін кестені толық сканерлейді. Өте кішкентай кестелерде бұл әдетте қиындық тудырмайды, бірақ үйме көлемі ұлғайған сайын өнімділік тез төмендейді. Әрине, кластерленбеген индекс қажетті деректер сақталған файлға, бетке және жолға көрсеткішті пайдалану арқылы көмектесе алады - бұл әдетте кестені сканерлеуге әлдеқайда жақсы балама. Солай бола тұрса да, сұрау өнімділігін қарастырған кезде кластерленген индекстің артықшылықтарын салыстыру қиын.
Дегенмен, үйме белгілі бір жағдайларда өнімділікті жақсартуға көмектеседі. Кірістірулері көп, бірақ жаңартулары немесе жоюлары аз кестені қарастырыңыз. Мысалы, журналды сақтайтын кесте, ең алдымен, мұрағатталғанға дейін мәндерді енгізу үшін пайдаланылады. Үймеде кластерленген индекстегідей пейджинг пен деректердің фрагментациясын көрмейсіз, себебі жолдар үйменің соңына қосылады. Беттерді тым көп бөлу өнімділікке айтарлықтай әсер етуі мүмкін, бірақ жақсы жолмен емес. Жалпы алғанда, үйме деректерді салыстырмалы түрде ауыртпалықсыз енгізуге мүмкіндік береді және кластерленген индексте болатын сақтау және техникалық қызмет көрсету шығындарымен айналысудың қажеті жоқ.
Бірақ деректерді жаңарту мен жоюдың болмауы жалғыз себеп деп санауға болмайды. Деректерді іріктеу тәсілі де маңызды фактор болып табылады. Мысалы, деректер ауқымын жиі сұрайтын болсаңыз немесе сұралатын деректерді жиі сұрыптау немесе топтастыру қажет болса, үйінді пайдаланбауыңыз керек.
Мұның бәрі өте кішкентай кестелермен жұмыс істегенде ғана үйінді пайдалануды қарастыру керек екенін білдіреді немесе кестемен барлық әрекеттесу деректер енгізумен шектеледі және сұрауларыңыз өте қарапайым (және сіз кластерленбеген индекстерді пайдаланып жатырсыз). бәрібір). Әйтпесе, кең таралған баған сияқты қарапайым өсетін кілт өрісінде анықталған сияқты жақсы жобаланған кластерленген индексті ұстаныңыз. ЖЕКЕ БАСЫН КУӘЛАНДЫРАТЫН.
Әдепкі индексті толтыру коэффициентін қалай өзгертуге болады?
Әдепкі индексті толтыру коэффициентін өзгерту бір нәрсе. Әдепкі қатынастың қалай жұмыс істейтінін түсіну басқа мәселе. Бірақ алдымен бірнеше қадам артқа шегініңіз. Индекс толтыру коэффициенті жаңа бетті толтыруды бастамас бұрын индексті төменгі деңгейде (жапырақ деңгейі) сақтау үшін беттегі бос орын мөлшерін анықтайды. Мысалы, егер коэффициент 90-ға орнатылса, индекс өскенде ол беттің 90% алады, содан кейін келесі бетке өтеді.
Әдепкі бойынша, индексті толтыру факторының мәні ішінде болады SQL сервері 0 болып табылады, ол 100-мен бірдей. Нәтижесінде кодыңызда жүйенің стандартты мәнінен басқа мәнді арнайы көрсетпейінше немесе әдепкі әрекетті өзгертпесеңіз, барлық жаңа индекстер осы параметрді автоматты түрде иеленеді. Сіз пайдалана аласыз SQL Server Management Studioәдепкі мәнді реттеу немесе жүйеде сақталған процедураны іске қосу sp_configure. Мысалы, келесі жиынтық T-SQLпәрмендері коэффициент мәнін 90-ға орнатады (алдымен кеңейтілген параметрлер режиміне ауысу керек):
EXEC sp_configure "қосымша опцияларды көрсету ", 1; ҚАЙТА КОНФИГУРАЦИЯҒА ӨТУ; EXEC sp_configure ӨТУ "толтыру коэффициенті", 90; ҚАЙТА КОНФИГУРАЦИЯЛАУ; ӨТУ
Индекс толтыру коэффициентінің мәнін өзгерткеннен кейін қызметті қайта іске қосу керек SQL сервері. Енді көрсетілген екінші аргументсіз sp_configure іске қосу арқылы орнатылған мәнді тексеруге болады:
EXEC sp_configure "толтыру факторы" GO
Бұл пәрмен 90 мәнін қайтаруы керек. Нәтижесінде барлық жаңадан жасалған индекстер осы мәнді пайдаланады. Мұны индексті жасау және толтыру факторы мәніне сұрау арқылы тексеруге болады:
AdventureWorks2012 пайдалану; -- сіздің дерекқорыңызКЛАСТЕРЛІК ЕМЕС ИНДЕКС ЖАСАУ ix_people_lastname ON Person.Person(LastName); GO SELECT fill_factor FROM sys .indexes WHERE object_id = object_id("Person.Person" ) ЖӘНЕ name ="ix_people_lastname" ;Бұл мысалда біз кестеде кластерленбеген индекс жасадық Адамдеректер базасында AdventureWorks2012. Индексті жасағаннан кейін толтыру коэффициентінің мәнін sys.indexes жүйелік кестелерінен ала аламыз. Сұрау 90 қайтаруы керек.
Дегенмен, біз индексті жойып, оны қайтадан жасадық деп елестетіп көрейік, бірақ қазір біз толтыру факторының нақты мәнін көрсеттік:
Бұл жолы біз нұсқауларды қостық МЕНжәне опция толтырғышиндекс құру операциясы үшін ИНДЕКС ЖАСАУжәне 80 мәнін көрсетті. Оператор ТАҢДАУенді сәйкес мәнді қайтарады.
Осы уақытқа дейін бәрі өте қарапайым болды. Сіз бұл мәнді білетін болсаңыз, әдепкі коэффициент мәнін пайдаланатын индексті жасаған кезде осы процесте шынымен күйіп қалуыңыз мүмкін. Мысалы, біреу сервер параметрлерімен айналысып жатыр және олар индексті толтыру коэффициентін 20-ға орнатқаны соншалық, әдепкі мән 0 деп есептеліп, индекстерді жасауды жалғастырасыз. Өкінішке орай, толтыруды білуге мүмкіндік жоқ. индексті жасамайынша факторды өзгертіңіз, содан кейін біз мысалдардағыдай мәнді тексеріңіз. Әйтпесе, сұрау өнімділігі соншалықты төмендеп, бірдеңеден күдіктене бастайтын сәтті күтуге тура келеді.
Сіз білуі керек тағы бір мәселе - индекстерді қайта құру. Индекс жасау кезіндегідей, оны қайта құру кезінде индексті толтыру факторының мәнін көрсетуге болады. Дегенмен, индексті жасау пәрменінен айырмашылығы, қайта құру сервердің әдепкі параметрлерін пайдаланбайды, бұл көрінуі мүмкін. Одан да, егер сіз индексті толтыру коэффициентінің мәнін арнайы көрсетпесеңіз, онда SQL серверіосы индекс қайта құрылымдалғанға дейін болған коэффициенттің мәнін пайдаланады. Мысалы, келесі операция ӨЗГЕРТУ ИНДЕКСбіз жаңа ғана жасаған индексті қайта құрады:
Толтыру факторының мәнін тексерген кезде біз 80 мәнін аламыз, себебі индексті соңғы рет жасағанда дәл солай көрсеттік. Әдепкі мән еленбейді.
Көріп отырғаныңыздай, индексті толтыру коэффициентінің мәнін өзгерту қиын емес. Ағымдағы мәнді білу және оны қолдану кезінде түсіну әлдеқайда қиын. Егер сіз индекстерді құру және қайта құру кезінде әрқашан нақты коэффициентті көрсетсеңіз, онда сіз әрқашан нақты нәтижені білесіз. Басқа біреудің сервер параметрлерін қайтадан бұзып, барлық индекстердің күлкілі төмен индексті толтыру коэффициентімен қайта құрылуына әкеліп соқтырмайтынына сенімді болмайынша.
Көшірмелері бар бағанда кластерленген индексті жасауға болады ма?
Иә және жоқ. Иә, қайталанатын мәндерді қамтитын кілт бағанында кластерленген индекс жасай аласыз. Жоқ, кілт бағанының мәні бірегей емес күйде қала алмайды. Түсіндірейін. Бағанда бірегей емес кластерленген индекс жасасаңыз, сақтау механизмі бірегейлікті қамтамасыз ету және сондықтан кластерленген кестедегі әрбір жолды анықтау мүмкіндігін қамтамасыз ету үшін қайталанатын мәнге бірегейлендіруші қосады.
Мысалы, тұтынушы деректерін қамтитын бағанда кластерленген индекс жасауды шешуге болады Тектегін сақтау. Бағанда Франклин, Хэнкок, Вашингтон және Смит мәндері бар. Содан кейін сіз Адамс, Хэнкок, Смит және Смит мәндерін қайтадан енгізесіз. Бірақ кілт бағанының мәні бірегей болуы керек, сондықтан сақтау механизмі көшірмелердің мәнін өзгертіп, олар келесідей болады: Адамс, Франклин, Хэнкок, Ханкок1234, Вашингтон, Смит, Смит4567 және Смит5678.
Бір қарағанда, бұл тәсіл жақсы болып көрінеді, бірақ бүтін мән кілттің өлшемін арттырады, егер көшірмелердің көп саны болса, мәселе туындауы мүмкін және бұл мәндер кластерлік емес индекстің немесе шетелдік индекстің негізі болады. негізгі сілтеме. Осы себептерге байланысты мүмкіндігінше әрқашан бірегей кластерленген индекстерді жасауға тырысу керек. Егер бұл мүмкін болмаса, кем дегенде өте жоғары бірегей мән мазмұны бар бағандарды пайдаланып көріңіз.
Кластерлік индекс жасалмаса, кесте қалай сақталады?
SQL серверікестелердің екі түрін қолдайды: кластерленген индексі бар кластерленген кестелер және үйме кестелер немесе жай үймелер. Кластерленген кестелерден айырмашылығы, үймедегі деректер ешқандай жолмен сұрыпталмайды. Негізінде бұл деректердің үйіндісі (үйіндісі). Мұндай кестеге жол қоссаңыз, сақтау жүйесі оны жай ғана беттің соңына қосады. Бет деректермен толтырылған кезде ол жаңа бетке қосылады. Көп жағдайда сұрыптау мүмкіндігі мен сұрау жылдамдығын пайдалану үшін кестеде кластерленген индекс жасағыңыз келеді (сұрыпталмаған мекенжай кітапшасынан телефон нөмірін іздеп көріңіз). Дегенмен, кластерленген индексті жасамауды таңдасаңыз, үймеде әлі де кластерленбеген индекс жасай аласыз. Бұл жағдайда әрбір индекс жолында үйме жолының көрсеткіші болады. Индекс файл идентификаторын, бет нөмірін және деректер жолының нөмірін қамтиды.
Мәннің бірегейлік шектеулері мен кесте индекстері бар бастапқы кілт арасында қандай байланыс бар?
Бастапқы кілт және бірегей шектеу бағандағы мәндердің бірегей болуын қамтамасыз етеді. Кесте үшін тек бір негізгі кілт жасай аласыз және ол мәндерді қамти алмайды NULL. Кесте үшін мәннің бірегейлігіне бірнеше шектеулер жасауға болады және олардың әрқайсысында бір жазба болуы мүмкін. NULL.
Бастапқы кілтті жасаған кезде, кластерленген индекс әлі жасалмаған болса, сақтау механизмі де бірегей кластерлік индексті жасайды. Дегенмен, әдепкі әрекетті қайта анықтауға болады және кластерленбеген индекс жасалады. Бастапқы кілтті жасаған кезде кластерленген индекс бар болса, бірегей кластерленбеген индекс жасалады.
Бірегей шектеуді жасағанда, сақтау механизмі бірегей, кластерлік емес индекс жасайды. Дегенмен, егер бұрын жасалмаған болса, бірегей кластерленген индексті жасауды көрсетуге болады.
Жалпы, бірегей мән шектеуі мен бірегей индекс бірдей нәрсе.
Неліктен SQL серверінде кластерленген және кластерленбеген индекстер B-ағаш деп аталады?
SQL серверіндегі кластерленген немесе кластерленбеген негізгі индекстер индекс түйіндері деп аталатын беттер жиындарына таратылады. Бұл беттер теңдестірілген ағаш деп аталатын ағаш құрылымы бар белгілі бір иерархияда ұйымдастырылған. Жоғарғы деңгейде түбір түйіні, төменгі жағында суретте көрсетілгендей жоғарғы және төменгі деңгейлер арасында аралық түйіндері бар жапырақ түйіндері орналасқан:
Түбірлік түйін индекс арқылы деректерді алуға әрекеттенетін сұраулар үшін негізгі кіру нүктесін береді. Осы түйіннен бастап сұрау жүйесі иерархиялық құрылымнан деректерді қамтитын сәйкес жапырақ түйініне дейін шарлауды бастайды.
Мысалы, 82 кілт мәні бар жолдарды таңдауға сұрау алынды деп елестетіңіз. Сұрау ішкі жүйесі қолайлы аралық түйінге сілтеме жасайтын түбірлік түйіннен жұмыс істей бастайды, біздің жағдайда 1-100. 1-100 аралық түйіннен 51-100 түйініне, ал одан соңғы 76-100 түйініне көшу жүреді. Егер бұл кластерленген индекс болса, онда түйін парағы 82-ге тең кілтпен байланысты жолдың деректерін қамтиды. Бұл кластерленбеген индекс болса, онда индекс парағында кластерленген кестеге немесе белгілі бір жолға көрсеткіш бар. үйме.
Барлық осы индекс түйіндерін айналып өту керек болса, индекс сұрау өнімділігін қалай жақсарта алады?
Біріншіден, индекстер өнімділікті әрдайым жақсарта бермейді. Тым көп қате жасалған индекстер жүйені батпаққа айналдырып, сұрау өнімділігін төмендетеді. Егер индекстер мұқият қолданылса, олар өнімділіктің айтарлықтай өсуін қамтамасыз ете алады деп айту дұрысырақ.
Өнімділікті реттеуге арналған үлкен кітапты ойлап көріңіз SQL сервері(қағаз нұсқасы, электронды нұсқасы емес). Ресурс реттеушісін конфигурациялау туралы ақпаратты тапқыңыз келетінін елестетіп көріңіз. Бүкіл кітап бойынша саусағыңызбен бет-бет сүйреуге немесе мазмұнды ашуға және іздеген ақпаратпен нақты бет нөмірін білуге болады (кітап дұрыс индекстелген және мазмұнда дұрыс индекстер болған жағдайда). Бұл бастапқы құрылымнан (кітаптан) қажетті ақпаратты алу үшін алдымен мүлде басқа құрылымға (индекске) қол жеткізу керек болса да, айтарлықтай уақытты үнемдейтіні сөзсіз.
Кітап индексі, индекс сияқты SQL серверікестедегі барлық деректерді толығымен сканерлеудің орнына қажетті деректер бойынша нақты сұрауларды орындауға мүмкіндік береді. Кішігірім кестелер үшін толық сканерлеу әдетте қиындық туғызбайды, бірақ үлкен кестелер деректердің көптеген беттерін алады, бұл сұрау механизміне деректердің дұрыс орнын дереу алуға мүмкіндік беретін индекс болмаса, сұрауды орындау уақытының айтарлықтай болуына әкелуі мүмкін. Картасыз ірі мегаполистің алдындағы көп деңгейлі жол торабында адасып қалғаныңызды елестетіп көріңіз және сіз идеяны аласыз.
Егер индекстер соншалықты керемет болса, неге әр бағанда бір ғана жасамасқа?
Ешбір жақсылық жазасыз қалмауы керек. Кем дегенде, бұл индекстерге қатысты. Әрине, индекстер операторды алу сұрауларын іске қосқанда жақсы жұмыс істейді ТАҢДАУ, бірақ операторларға жиі қоңыраулар басталады INSERT, ЖАҢАРТУЖәне ЖОЮ, сондықтан пейзаж өте тез өзгереді.
Оператор деректер сұрауын бастаған кезде ТАҢДАУ, сұрау жүйесі индексті табады, оның ағаш құрылымы бойынша жылжиды және іздеген деректерді ашады. Не қарапайым болуы мүмкін? сияқты өзгерту мәлімдемесін бастасаңыз, бәрі өзгереді ЖАҢАРТУ. Иә, мәлімдеменің бірінші бөлігінде сұрау жүйесі өзгертілетін жолды табу үшін индексті қайтадан пайдалана алады - бұл жақсы жаңалық. Ал егер негізгі бағандардағы өзгерістерге әсер етпейтін қатардағы деректердің қарапайым өзгеруі болса, онда өзгерту процесі толығымен ауыртпалықсыз болады. Бірақ егер өзгерту деректері бар беттердің бөлінуіне себеп болса немесе негізгі бағанның мәні басқа индекс түйініне жылжытылып өзгертілсе ше - бұл индекстің барлық байланысты индекстер мен операцияларға әсер ететін қайта ұйымдастыруды қажет етуі мүмкін. , нәтижесінде өнімділіктің жаппай төмендеуі.
Ұқсас процестер операторды шақыру кезінде орын алады ЖОЮ. Индекс жойылатын деректердің орнын анықтауға көмектеседі, бірақ деректердің өзін жою бетті өзгертуге әкелуі мүмкін. Операторға қатысты INSERT, барлық индекстердің басты жауы: сіз деректердің үлкен көлемін қоса бастайсыз, бұл индекстердің өзгеруіне және олардың қайта ұйымдастырылуына әкеледі және барлығы зардап шегеді.
Сондықтан қандай индекстер түрін және қанша жасау керектігін ойластырған кезде дерекқорыңызға сұраулардың түрлерін қарастырыңыз. Көбірек жақсы дегенді білдірмейді. Кестеге жаңа индексті қоспас бұрын, тек негізгі сұраулардың құнын ғана емес, сонымен қатар тұтынылатын дискілік кеңістіктің көлемін, басқа операцияларға домино эффектісіне әкелуі мүмкін функционалдылықты және индекстерді қолдау құнын қарастырыңыз. Индексті жобалау стратегияңыз іске асырудың ең маңызды аспектілерінің бірі болып табылады және индекс өлшемінен, бірегей мәндер санынан бастап индекс қолдайтын сұраулар түріне дейін көптеген ойларды қамтуы керек.
Бастапқы кілті бар бағанда кластерленген индексті жасау қажет пе?
Қажетті шарттарға сәйкес келетін кез келген бағанда кластерленген индекс жасауға болады. Кластерленген индекс пен негізгі кілт шектеуі бір-бірімен жасалғаны және көкте жасалған сәйкестік екені рас, сондықтан бастапқы кілтті жасағанда, егер бірі жасалмаған болса, кластерленген индекс автоматты түрде жасалатынын түсініңіз. бұрын құрылған. Дегенмен, сіз кластерленген индекс басқа жерде жақсырақ жұмыс істейтінін шеше аласыз және көбінесе сіздің шешіміңіз ақталады.
Кластерленген индекстің негізгі мақсаты – индексті анықтау кезінде көрсетілген негізгі баған негізінде кестедегі барлық жолдарды сұрыптау. Бұл жылдам іздеуді және кесте деректеріне оңай қол жеткізуді қамтамасыз етеді.
Кестенің бастапқы кілті жақсы таңдау болуы мүмкін, себебі ол қосымша деректерді қоспай-ақ кестелердегі әрбір жолды бірегей түрде анықтайды. Кейбір жағдайларда ең жақсы таңдау тек бірегей ғана емес, сонымен қатар өлшемі бойынша шағын және мәндері дәйекті түрде артып, осы мәнге негізделген кластерлік емес индекстерді тиімдірек ететін суррогат бастапқы кілт болады. Сұрау оңтайландырғышына кластерленген индекс пен негізгі кілттің осы тіркесімі де ұнайды, себебі кестелерді біріктіру бастапқы кілтті және оның байланысты кластерленген индексін пайдаланбайтын басқа жолмен қосылуға қарағанда жылдамырақ. Мен айтқанымдай, бұл аспанда жасалған сіріңке.
Соңында, кластерленген индексті құру кезінде ескеретін бірнеше аспектілер бар екенін атап өткен жөн: оның негізінде қанша кластерленбеген индекстер құрылады, негізгі индекс бағанының мәні қаншалықты жиі өзгереді және қаншалықты үлкен. Кластерленген индекстің бағандарындағы мәндер өзгергенде немесе индекс күткендей орындалмаса, кестедегі барлық басқа индекстерге әсер етуі мүмкін. Кластерленген индекс мәндері белгілі бір тәртіпте өсетін, бірақ кездейсоқ түрде өзгермейтін ең тұрақты бағанға негізделуі керек. Индекс кестенің ең жиі қатынайтын деректеріне қарсы сұрауларды қолдауы керек, сондықтан сұраулар деректердің түбірлік түйіндерде, индекстің жапырақтарында сұрыпталған және қол жетімді болу фактісін толық пайдаланады. Бастапқы кілт осы сценарийге сәйкес келсе, оны пайдаланыңыз. Олай болмаса, бағандардың басқа жинағын таңдаңыз.
Көріністі индекстесеңіз ше, ол әлі де көрініс пе?
Көрініс - бұл бір немесе бірнеше кестелерден деректерді генерациялайтын виртуалды кесте. Негізінде, бұл көріністі сұраған кезде негізгі кестелерден деректерді шығарып алатын атаулы сұрау. Кестеде индекстерді жасау әдісіне ұқсас осы көріністе кластерленген индексті және кластерленбеген индекстерді жасау арқылы сұрау өнімділігін жақсартуға болады, бірақ негізгі ескерту: алдымен кластерленген индексті жасайсыз, содан кейін кластерленбеген индексті жасай аласыз.
Индекстелген көрініс (материалданған көрініс) жасалғанда, көрініс анықтамасының өзі бөлек нысан болып қалады. Бұл, сайып келгенде, тек қатты кодталған оператор ТАҢДАУ, дерекқорда сақталады. Бірақ көрсеткіш мүлдем басқа әңгіме. Провайдерде кластерленген немесе кластерленбеген индексті жасағанда, деректер кәдімгі индекс сияқты физикалық түрде дискіге сақталады. Бұған қоса, негізгі кестелердегі деректер өзгерген кезде көріністің индексі автоматты түрде өзгереді (бұл жиі өзгеретін кестелердегі көріністерді индекстеуден аулақ болғыңыз келетінін білдіреді). Кез келген жағдайда, көрініс көрініс болып қалады - кестелерді қарау, бірақ қазіргі уақытта орындалған, оған сәйкес индекстері бар.
Көріністе индексті жасамас бұрын, ол бірнеше шектеулерге сай болуы керек. Мысалы, көрініс тек негізгі кестелерге сілтеме жасай алады, бірақ басқа көріністерге емес, және бұл кестелер бір дерекқорда болуы керек. Іс жүзінде көптеген басқа шектеулер бар, сондықтан құжаттаманы тексеріңіз SQL серверібарлық лас бөлшектер үшін.
Неліктен құрама индекстің орнына жабу индексін пайдалану керек?
Алдымен, екеуінің арасындағы айырмашылықты түсінгенімізге көз жеткізейік. Құрама индекс - бұл бір бағаннан көп тұратын қарапайым индекс. Кестедегі әрбір жолдың бірегей екеніне көз жеткізу үшін бірнеше кілт бағандарын пайдалануға болады немесе негізгі кілттің бірегей екеніне көз жеткізу үшін бірнеше бағандар болуы мүмкін немесе бірнеше бағандарда жиі шақырылатын сұраулардың орындалуын оңтайландыруға әрекеттенуіңіз мүмкін. Жалпы алғанда, индексте неғұрлым негізгі бағандар болса, индекс соғұрлым тиімділігі аз болады, бұл құрама индекстерді ұтымды пайдалану керек дегенді білдіреді.
Көрсетілгендей, барлық қажетті деректер индекстің өзі сияқты бірден индекс жапырақтарында орналасса, сұрау үлкен пайда әкелуі мүмкін. Бұл кластерленген индекс үшін проблема емес, себебі барлық деректер қазірдің өзінде бар (сондықтан кластерленген индексті жасаған кезде мұқият ойлану өте маңызды). Бірақ жапырақтардағы кластерленбеген индекс тек негізгі бағандарды қамтиды. Барлық басқа деректерге қол жеткізу үшін сұрауды оңтайландырғыш қосымша қадамдарды талап етеді, бұл сұрауларыңызды орындауға айтарлықтай үстеме шығындарды қосады.
Бұл жерде жабу көрсеткіші көмекке келеді. Кластерленбеген индексті анықтаған кезде, негізгі бағандарға қосымша бағандарды көрсетуге болады. Мысалы, қолданбаңыз баған деректерін жиі сұрайды делік Тапсырыс идентификаторыЖәне Тапсырыс күнікестеде Сатылымдар:
Екі бағанда да кластерленбеген құрама индексті жасауға болады, бірақ ТапсырысКүні бағаны ерекше пайдалы негізгі баған ретінде қызмет етпестен тек индекске техникалық қызмет көрсету шығындарын қосады. Ең жақсы шешім кілт бағанында жабу индексін жасау болады Тапсырыс идентификаторыжәне қосымша қосылған баған Тапсырыс күні:
dbo.Sales(Тапсырыс идентификаторы) ҚҰРУ (Тапсырыс күні);Бұл сұрауларды орындау кезінде деректерді жапырақтарда сақтаудың артықшылықтарын сақтай отырып, артық бағандарды индекстеу кемшіліктерін болдырмайды. Қосылған баған кілттің бөлігі емес, бірақ деректер жапырақ түйінінде, индекс парағында сақталады. Бұл қосымша шығындарсыз сұрау өнімділігін жақсарта алады. Сонымен қатар, жабу индексіне енгізілген бағандар индекстің негізгі бағандарына қарағанда азырақ шектеулерге ұшырайды.
Негізгі бағандағы көшірмелердің саны маңызды ма?
Индекс жасағанда, негізгі бағандарыңыздағы көшірмелердің санын азайтуға тырысуыңыз керек. Немесе дәлірек айтқанда: қайталау жылдамдығын мүмкіндігінше төмен ұстауға тырысыңыз.
Егер сіз құрама индекспен жұмыс істеп жатсаңыз, онда қайталау тұтастай барлық негізгі бағандарға қолданылады. Жалғыз бағанда көптеген қайталанатын мәндер болуы мүмкін, бірақ барлық индекс бағандары арасында қайталану аз болуы керек. Мысалы, бағандарда құрама кластерлік емес индекс жасайсыз АтыЖәне Тек, сізде көптеген John Doe мәндері және көптеген Doe мәндері болуы мүмкін, бірақ сіз мүмкіндігінше аз Джон До мәндерін немесе жақсырақ бір ғана Джон До мәндерін алғыңыз келеді.
Кілттік баған мәндерінің бірегейлік қатынасы индекстік селективтілік деп аталады. Неғұрлым бірегей мәндер болса, соғұрлым селективтілік соғұрлым жоғары болады: бірегей индекстің ең үлкен таңдау мүмкіндігі бар. Сұрау жүйесі жоғары таңдау мәндері бар бағандарды ұнатады, әсіресе бұл бағандар ең жиі орындалатын сұрауларыңыздың WHERE сөйлемдеріне қосылған болса. Индекс неғұрлым таңдамалы болса, сұрау жүйесі соғұрлым жылдамырақ нәтиже деректер жиынының өлшемін азайта алады. Кемшілігі, әрине, салыстырмалы түрде аз бірегей мәндері бар бағандар сирек индекстеу үшін жақсы үміткер болады.
Кластерлік емес индексті тек негізгі баған деректерінің белгілі бір жиынында жасауға болады ма?
Әдепкі бойынша, кластерленбеген индекс кестедегі әрбір жол үшін бір жолды қамтиды. Әрине, мұндай индексті кесте деп есептей отырып, кластерленген индекс туралы дәл осылай айтуға болады. Бірақ кластерлік емес индекске келетін болсақ, бір-бір қатынас маңызды тұжырымдама болып табылады, өйткені нұсқадан бастап SQL Server 2008, сізде оған енгізілген жолдарды шектейтін сүзілетін индекс жасау мүмкіндігі бар. Сүзілген индекс сұрау өнімділігін жақсарта алады, себебі... ол кішірек өлшемді және барлық кестелік статистикаға қарағанда сүзгіленген, дәлірек статистиканы қамтиды - бұл жақсартылған орындау жоспарларын жасауға әкеледі. Сүзілген индекс сонымен қатар сақтау орнын азырақ және техникалық қызмет көрсету шығындарын азайтады. Сүзгіге сәйкес деректер өзгерген кезде ғана индекс жаңартылады.
Сонымен қатар, сүзілетін индексті жасау оңай. Операторда ИНДЕКС ЖАСАУкөрсету керек ҚАЙДАсүзгі жағдайы. Мысалы, кодта көрсетілгендей индекстен NULL бар барлық жолдарды сүзуге болады:
Біз, шын мәнінде, маңызды сұрауларда маңызды емес кез келген деректерді сүзгіден өткізе аламыз. Бірақ сақ болыңыз, өйткені... SQL серверікөріністе сүзілетін индекс жасау мүмкін еместігі сияқты сүзілетін индекстерге бірнеше шектеулер қояды, сондықтан құжаттаманы мұқият оқып шығыңыз.
Сондай-ақ, индекстелген көріністі жасау арқылы ұқсас нәтижелерге қол жеткізуге болады. Дегенмен, сүзгіленген индекстің техникалық қызмет көрсету шығындарын азайту және орындау жоспарларының сапасын жақсарту мүмкіндігі сияқты бірнеше артықшылығы бар. Сүзілген индекстерді желіде де қайта құруға болады. Мұны индекстелген көрініспен қолданып көріңіз.
6. Индекстер және өнімділікті оңтайландыру
Мәліметтер қорындағы индекстер: мақсаты, өнімділікке әсері, индекстерді құру принциптері
6.1 Индекс не үшін қажет?
Индекстер – кестедегі белгілі бір өріс немесе өрістер жиыны бойынша іздеу мен сұрыптауды жылдамдатуға мүмкіндік беретін мәліметтер қорындағы арнайы құрылымдар, сонымен қатар деректердің бірегейлігін қамтамасыз ету үшін қолданылады. Индекстерді салыстырудың ең оңай жолы - кітаптардағы индекстермен. Егер индекс болмаса, біз дұрыс орынды табу үшін бүкіл кітапты қарап шығуымыз керек, бірақ индекспен бірдей әрекетті әлдеқайда жылдам орындауға болады.
Әдетте, индекстер неғұрлым көп болса, деректер қоры сұрауларының өнімділігі соғұрлым жақсы болады. Дегенмен, индекстер саны шамадан тыс көбейсе, деректерді өзгерту әрекеттерінің өнімділігі (енгізу/өзгерту/жою) төмендейді және дерекқордың өлшемі ұлғаяды, сондықтан индекстерді қосуға сақтықпен қарау керек.
Индекстерді құруға байланысты кейбір жалпы принциптер:
· іздеу және сұрыптау операциялары үшін жиі қолданылатын біріктірулерде қолданылатын бағандар үшін индекстер жасалуы керек. Бастапқы кілт шектеуіне жататын бағандар үшін индекстер әрқашан автоматты түрде жасалатынын ескеріңіз. Көбінесе олар сыртқы кілті бар бағандар үшін жасалады (Access-те - автоматты түрде);
· бірегейлік шектеуіне жататын бағандар үшін индекс автоматты түрде құрылуы керек;
· Қайталанатын мәндердің ең аз саны бар және деректер біркелкі таратылатын өрістер үшін индекстерді жасаған дұрыс. Oracle-да қайталанатын мәндердің көп саны бар бағандарға арналған арнайы бит индекстері бар және Access бұл индекс түрін қамтамасыз етпейді;
· егер іздеу үнемі белгілі бір бағандар жиынында (бір мезгілде) орындалатын болса, онда бұл жағдайда құрама индексті (тек SQL Server-де) құру мағынасы болуы мүмкін - бағандар тобы үшін бір индекс;
· Кестелерге өзгертулер енгізілгенде, осы кестенің үстіне қойылған индекстер автоматты түрде өзгертіледі. Нәтижесінде, көрсеткіш жоғары фрагменттелген болуы мүмкін, бұл өнімділікке әсер етеді. Сіз мезгіл-мезгіл индекстің фрагментация дәрежесін тексеріп, оларды дефрагментациялауыңыз керек. Деректердің үлкен көлемін жүктегенде, кейде алдымен барлық индекстерді жою және операция аяқталғаннан кейін оларды қайтадан жасау мағынасы бар;
· индекстерді тек кестелер үшін ғана емес, сонымен қатар көріністер үшін де жасауға болады (тек SQL серверінде). Артықшылықтары - өрістерді сұрау кезінде емес, кестелерде жаңа мәндер пайда болған кезде есептеу мүмкіндігі.
Бұл мақалада индекстер және олардың сұрауды орындау уақытын оңтайландырудағы рөлі талқыланады. Мақаланың бірінші бөлігінде индекстердің әртүрлі нысандары және оларды сақтау жолдары қарастырылады. Әрі қарай, индекстермен жұмыс істеу үшін пайдаланылатын үш негізгі Transact-SQL операторларын қарастырамыз: CREATE INDEX, ALTER INDEX және DROP INDEX. Содан кейін оның жүйе өнімділігіне әсер ету индекстерінің фрагменті қарастырылады. Содан кейін ол индекстерді құрудың кейбір жалпы нұсқауларын береді және индекстердің бірнеше арнайы түрлерін сипаттайды.
Негізгі ақпарат
Деректер базасы жүйелері реляциялық деректерге жылдам қол жеткізуді қамтамасыз ету үшін әдетте индекстерді пайдаланады. Индекс - деректердің бір немесе бірнеше жолына жылдам қол жеткізуге мүмкіндік беретін жеке физикалық деректер құрылымы. Осылайша, индекстерді дұрыс баптау сұрау өнімділігін жақсартудың негізгі аспектісі болып табылады.
Мәліметтер қорының индексі көп жағынан кітаптың индексіне (алфавиттік көрсеткіш) ұқсас. Кітаптан тақырыпты жылдам табу керек болғанда, біз алдымен кітаптың қай беттерінде бұл тақырып талқыланғанын индекстен қарап, содан кейін бірден қажетті бетті ашамыз. Сол сияқты, кестедегі белгілі бір жолды іздегенде, дерекқор механизмі оның физикалық орнын табу үшін индекске қатынасады.
Бірақ кітап индексі мен дерекқор индексі арасында екі маңызды айырмашылық бар:
Кітап оқырманы әрбір нақты жағдайда индексті қолдану немесе қолданбау туралы шешім қабылдауға мүмкіндігі бар. Мәліметтер қорын пайдаланушыда мұндай мүмкіндік жоқ және бұл шешім ол үшін деп аталатын жүйелік компонент арқылы қабылданады сұрауды оңтайландырушы. (Пайдаланушы индекстер туралы кеңестер арқылы индекстерді пайдалануды басқара алады, бірақ бұл кеңестер арнайы жағдайларда шектеулі санда ғана пайдалануға ұсынылады.)
Белгілі бір жұмыс кітабының индексі жұмыс кітабымен бірге жасалады, содан кейін ол енді өзгертілмейді. Бұл белгілі бір тақырыптың индексі әрқашан бірдей бет нөмірін көрсететінін білдіреді. Керісінше, деректер қорының индексі сәйкес деректер өзгерген сайын өзгеруі мүмкін.
Егер кестеде сәйкес индекс болмаса, жүйе жолдарды шығарып алу үшін кестені сканерлеу әдісін пайдаланады. Өрнек кестені сканерлеужүйе кестенің әрбір жолын (біріншіден соңғысына дейін) дәйекті түрде шығарып, зерттейтінін және WHERE сөйлеміндегі іздеу шарты ол үшін қанағаттандырылса, жолды нәтижелер жиынына орналастыратынын білдіреді. Осылайша, барлық жолдар жадтағы физикалық орналасуына сәйкес шығарылады. Бұл әдіс төменде түсіндірілгендей, индекстерді пайдалану арқылы қол жеткізуге қарағанда тиімдірек.
Индекстер деп аталатын қосымша дерекқор құрылымдарында сақталады индекстік беттер. Әрбір индекстелген жол үшін бар индексті енгізу, ол индекс бетінде сақталады. Әрбір индекс элементі индекс кілтінен және индекстен тұрады. Сондықтан индекс элементі ол көрсететін кесте жолынан айтарлықтай қысқа. Осы себепті әрбір индекс бетіндегі индекс элементтерінің саны деректер бетіндегі жолдар санынан әлдеқайда көп.
Индекстердің бұл қасиеті өте маңызды, себебі индекс беттерін айналып өту үшін қажетті енгізу/шығару операцияларының саны сәйкес деректер беттерін айналып өту үшін қажетті енгізу/шығару операцияларының санынан айтарлықтай аз. Басқаша айтқанда, кестені сканерлеу кесте индексін сканерлеуге қарағанда көбірек енгізу/шығару әрекеттерін қажет етуі мүмкін.
Database Engine индекстері B+ ағаш деректер құрылымын пайдаланып жасалады. B+ ағашының барлық төменгі түйіндері ағаштың жоғарғы бөлігінен (түбір түйінінен) бірдей деңгейде қашықтықта орналасқан ағаш құрылымы бар. Бұл сипат деректер индекстелген бағанға қосылған немесе жойылған кезде де сақталады.
Төмендегі суретте Қызметкер кестесіне арналған B+ тармақ құрылымы және идентификатор бағаны үшін 25348 мәні бар сол кестедегі жолға тікелей қатынас көрсетілген. (Қызметкерлер кестесі идентификатор бағаны бойынша индекстелген деп есептейміз.) Сондай-ақ, бұл суретте B+ тармағы түбір түйінінен, ағаш түйіндерінен және нөлдік немесе одан да көп аралық түйіндерден тұратынын көре аласыз:
Бұл ағаштан 25348 мәнін төмендегідей іздеуге болады. Ағаштың түбінен бастап ол қажетті мәннен үлкен немесе оған тең ең кіші кілт мәнін іздейді. Осылайша, түбірлік түйінде бұл мән 29346 болады, сондықтан осы мәнмен байланысты аралық түйінге көшу жасалады. Бұл түйінде 28559 мәні көрсетілген талаптарға сәйкес келеді, нәтижесінде осы мәнмен байланысты тармақ түйініне көшу жүзеге асырылады. Бұл түйінде қажетті мән бар 25348. Қажетті индексті анықтап, сәйкес көрсеткіштерді пайдаланып деректер кестесінен оның жолын шығарып аламыз. (Балама эквивалентті тәсіл индекстен аз немесе оған тең мәнді іздеу болады.)
Индекстелген іздеу, әдетте, айқын артықшылықтарына байланысты көп жолдар саны бар кестелерді іздеудің қолайлы әдісі болып табылады. Индекстелген іздеуді қолдана отырып, біз тек бірнеше енгізу-шығару операцияларын қолдана отырып, кестедегі кез келген жолды өте қысқа уақыт ішінде таба аламыз. Ал дәйекті іздеу (яғни кестені бірінші жолдан соңғысына дейін сканерлеу) көп уақытты алады, қажетті жол неғұрлым алыс болса.
Келесі бөлімдерде біз кластерленген және кластерсіз индекстердің бар екі түрін қарастырамыз және индекстерді жасау жолын үйренеміз.
Кластерленген индекстер
Кластерлік индекскестедегі деректердің физикалық тәртібін анықтайды. Деректер базасының механизмі кесте үшін тек бір ғана кластерлік индексті жасауға мүмкіндік береді, себебі Кесте жолдарын физикалық түрде бірнеше жолмен ретке келтіруге болмайды. Кластерленген индексті қолданатын іздеу B+ ағашының түбірлік түйінінен ағаштың қос байланысқан тізімде бір-бірімен байланыстырылған түйіндеріне қарай орындалады. бет тізбегі.
Кластерленген индекстің маңызды қасиеті оның ағаш түйіндерінің деректер беттерін қамтитындығы болып табылады. (Кластерленген индекс түйіндерінің барлық басқа деңгейлері индекс беттерін қамтиды.) Кластерленген индексі анықталған (анық немесе жанама) кесте кластерленген кесте деп аталады. Кластерленген индекстің B+ ағаш құрылымы төмендегі суретте көрсетілген:

Кластерленген индекс бастапқы кілт шектеуімен анықталған бастапқы кілті бар әрбір кестеде әдепкі бойынша жасалады. Сонымен қатар, әрбір кластерленген индекс әдепкі бойынша бірегей, яғни. Анықталған кластерленген индексі бар бағанда әрбір деректер мәні тек бір рет пайда болуы мүмкін. Егер кластерленген индекс қайталанатын мәндерді қамтитын бағанда жасалса, дерекқор жүйесі қайталанатын мәндерді қамтитын жолдарға төрт байт идентификаторды қосу арқылы анық еместікті қамтамасыз етеді.
Кластерленген индекстер сұрау мәндер ауқымын іздеген кезде деректерге өте жылдам қол жеткізуді қамтамасыз етеді.
Кластерленбеген индекстер
Кластерленбеген индекстің құрылымы кластерленген индекспен бірдей, бірақ екі маңызды айырмашылығы бар:
кластерленбеген индекс кесте жолдарының физикалық ретін өзгертпейді;
Кластерленбеген индекс түйіні беттері индекс кілттері мен бетбелгілерден тұрады.
Кестеде бір немесе бірнеше кластерленбеген индекстерді анықтасаңыз, кесте жолдарының физикалық реті өзгертілмейді. Әрбір кластерленбеген индекс үшін Дерекқор механизмі индекс беттерінде сақталатын қосымша индекс құрылымын жасайды. Кластерленбеген индекстің B+ ағаш құрылымы төмендегі суретте көрсетілген:

Кластерленбеген индекстегі бетбелгі индекс кілтіне сәйкес жолдың қай жерде орналасқанын көрсетеді. Кестенің кластерленген кесте немесе үйме болуына байланысты индекс кілтінің бетбелгі құрамдас бөлігі екі түрлі болуы мүмкін. (SQL Server терминологиясында үйме кластерленген индексі жоқ кесте болып табылады.) Егер кластерленген индекс бар болса, кластерленбеген индекс қойындысы кестенің кластерленген индексінің B+ тармағын көрсетеді. Кестеде кластерленген индекс болмаса, бетбелгі бірдей болады жол идентификаторы (RID - жол идентификаторы), үш бөліктен тұрады: кесте сақталатын файлдың адресі, жол сақталатын физикалық блоктың (беттің) мекенжайы және беттегі жолдың ығысуы.
Бұрын айтылғандай, кластерлік емес индексті пайдаланып деректерді іздеу кесте түріне байланысты екі түрлі жолмен орындалуы мүмкін:
үйме – кластерленбеген индекстің іздеу құрылымын айналып өту, одан кейін жол идентификаторы арқылы жол шығарылады;
кластерленген кесте – кластерленбеген индекс құрылымын іздеу, содан кейін сәйкес кластерленген индексті өту.
Екі жағдайда да енгізу/шығару операцияларының көлемі айтарлықтай үлкен, сондықтан кластерлік емес индексті абайлап құрастыру керек және оны пайдалану өнімділікті айтарлықтай жақсартатынына сенімді болсаңыз ғана пайдаланыңыз.
Transact-SQL тілі және индекстері
Біз индекстердің физикалық құрылымымен танысқаннан кейін, бұл бөлімде индекстерді құру, өзгерту және жою жолын, сонымен қатар индекс фрагменті туралы ақпаратты алу және индекс ақпаратын өңдеу жолдарын қарастырамыз. Мұның бәрі бізді жүйе өнімділігін жақсарту үшін индекстерді пайдалануды кейінгі талқылауға дайындайды.
Индекстерді құру
Кестедегі индекс оператордың көмегімен жасалады ИНДЕКС ЖАСАУ. Бұл нұсқаулықта келесі синтаксис бар:
INDEX индекс_атын ЖАСАУ Кесте_аты (1-баған ,...) [ ҚОСУ (баған_атауы [ ,... ]) ] [[, ] PAD_INDEX = (ҚОСУ | ӨШІРУ)] [[, ] DROP_EXISTING = (ҚОСУ | ӨШІРУ)] [[ , ] SORT_IN_TEMPDB = (ON | OFF)] [[, ] IGNORE_DUP_KEY = (ON | OFF)] [[, ] ALLOW_ROW_LOCKS = (ON | OFF)] [[, ] ALLOW_PAGE_LOCKS = (ON | OFF)] [[, ] STATISTICS_NORECOMPUTE = (ON | OFF)] [[, ] ONLINE = (ON | OFF)]] Синтаксистік конвенциялар
index_name параметрі жасалатын индекстің атын көрсетеді. Индекс table_name параметрімен анықталған бір кестенің бір немесе бірнеше бағандарында жасалуы мүмкін. Индекс жасалған баған баған1 параметрі арқылы көрсетіледі. Бұл параметрдің сандық жұрнағы индексті кестенің бірнеше бағандарында жасауға болатынын көрсетеді. Дерекқор механизмі көріністер бойынша индекстер жасауды да қолдайды.
Кез келген кесте бағанын индекстеуге болады. Бұл VARBINARY(max), BIGINT және SQL_VARIANT деректер түрінің мәндерін қамтитын бағандарды да индекстеуге болатындығын білдіреді.
Индекс қарапайым немесе құрама болуы мүмкін. Қарапайым индекс бір бағанда жасалады, ал құрама индекс бірнеше бағандарда жасалады. Құрама индекстің өлшемі мен бағандар санына қатысты белгілі шектеулері бар. Индекстің ең көбі 900 байт және ең көбі 16 баған болуы мүмкін.
UNIQUE параметріиндекстелген бағанда тек бір мәнді (яғни, қайталанбайтын) мәндер болуы мүмкін екенін көрсетеді. Бір мәнді құрама индексте бірегей әрбір жолдың барлық бағандарының мәндерінің тіркесімі болуы керек. UNIQUE кілт сөзі көрсетілмесе, индекстелген баған(дар)дағы қайталанатын мәндерге рұқсат етіледі.
CLUSTERED параметрікластерленген индексті көрсетеді және CLUSTERED ЕМЕС параметр(әдепкі) индекс кестедегі жолдардың ретін өзгертпейтінін көрсетеді. Дерекқор механизмі кестеде ең көбі 249 кластерлік емес индекстерге мүмкіндік береді.
Дерекқор механизмі баған мәндерінің кему реті бар индекстерді қолдау үшін жетілдірілді. Баған атауынан кейінгі ASC параметрі индекс баған мәндерінің өсу ретімен жасалғанын, ал DESC параметрі индекс баған мәндерінің кему ретін көрсетеді. Бұл индексті пайдалануда үлкен икемділікті қамтамасыз етеді. Кему ретімен мәндері қарама-қарсы бағытта реттелген бағандарда құрама индекстер жасау керек.
INCLUDE параметріКластерленбеген индекстің түйін беттеріне қосылған негізгі емес бағандарды көрсетуге мүмкіндік береді. INCLUDE тізіміндегі баған атаулары қайталанбауы керек және бағанды кілт және кілт емес баған ретінде пайдалану мүмкін емес.
INCLUDE параметрінің пайдалылығын шынымен түсіну үшін оның не екенін түсінуіңіз керек қамту көрсеткіші. Барлық сұрау бағандары индекске қосылса, айтарлықтай өнімділікті жақсартуға болады, себебі Сұрау оңтайландырғышы кестедегі деректерге қол жеткізбестен индекс беттеріндегі барлық баған мәндерін таба алады. Бұл мүмкіндік қамту индексі немесе қамту сұрауы деп аталады. Сондықтан, кластерленбеген индекс түйін беттерінде қосымша негізгі емес бағандарды қосу көбірек қамту сұрауларын алуға және олардың өнімділігін айтарлықтай жақсартуға мүмкіндік береді.
FILLFACTOR параметріиндекс жасау кезінде толтырылатын әрбір индекс бетінің пайызын көрсетеді. FILLFACTOR параметрінің мәнін 1-ден 100-ге дейінгі диапазонда орнатуға болады. n=100 мәнімен әрбір индекс беті 100%-ға толтырылады, яғни. бар түйін бетінде, сондай-ақ түйін емес бетте жаңа жолдарды кірістіру үшін бос орын болмайды. Сондықтан бұл мәнді тек статикалық кестелер үшін пайдалану ұсынылады. (Әдепкі мән, n=0, индекс түйіні беттерінің толы екенін және аралық беттердің әрқайсысында бір жазба үшін бос орын бар екенін білдіреді.)
FILLFACTOR параметрі 1 мен 99 арасындағы мәндерге орнатылса, жасалған индекс құрылымының түйін беттерінде бос орын болады. n мәні неғұрлым үлкен болса, индекс түйінінің беттерінде бос орын аз болады. Мысалы, n=60 болса, әрбір индекс түйінінің бетінде болашақ индекс жолының кірістірулері үшін 40% бос орын болады. (Индекс жолдары INSERT немесе UPDATE операторы арқылы енгізіледі.) Осылайша, деректері жиі өзгеретін кестелер үшін n=60 мәні орынды болады. 1 мен 99 арасындағы FILLFACTOR мәндерімен аралық индекс беттерінде әрқайсысы бір жазба үшін бос орын бар.
Индекс жасалғаннан кейін, пайдалану кезінде FILLFACTOR мәніне қолдау көрсетілмейді. Басқаша айтқанда, ол бос орынға пайызды орнату кезінде қолжетімді деректермен сақталған бос орын көлемін ғана көрсетеді. FILLFACTOR параметрін бастапқы мәніне қайтару үшін ALTER INDEX операторын пайдаланыңыз.
PAD_INDEX параметрі FILLFACTOR параметрімен тығыз байланысты. FILLFACTOR параметрі индекс түйіндерінің жалпы бет өлшемінің пайызы ретінде бос орын көлемін негізінен анықтайды. Және PAD_INDEX параметрі FILLFACTOR параметрінің мәні индекстегі индекс беттеріне де, деректер беттеріне де қолданылатынын көрсетеді.
DROP_EXISTING параметріСондай-ақ кластерленбеген индексі бар кестеде кластерленген индексті шығару кезінде өнімділікті жақсартуға мүмкіндік береді. Қосымша ақпаратты төмендегі «Индексті қайта құру» бөлімінен қараңыз.
SORT_IN_TEMPDB параметрі tempdb жүйесінің дерекқорына индексті жасау кезінде пайдаланылатын аралық сұрыптау әрекеттерінен деректерді орналастыру үшін пайдаланылады. tempdb деректерден басқа дискіде орналасқан болса, бұл өнімділікті жақсартуы мүмкін.
IGNORE_DUP_KEY параметріЖүйеге индекстелген бағандарға қайталанатын мәндерді кірістіру әрекетін елемеуге мүмкіндік береді. Бұл опцияны INSERT операторы индекстелген бағанға қайталанатын деректерді кірістіргенде ұзақ орындалатын транзакцияны тоқтатуды болдырмау үшін ғана пайдаланылуы керек. Бұл опция қосылғанда, INSERT операторы индекстің бірегейлігін бұзатын жолдарды кестеге кірістіруге әрекет жасағанда, дерекқор жүйесі бүкіл мәлімдемені бұзудың орнына жай ғана ескерту береді. Бұл жағдайда Дерекқор механизмі қайталанатын кілт мәндері бар жолдарды кірістірмейді, жай ғана оларды елемеді және дұрыс жолдарды қосады. Егер бұл параметр орнатылмаса, онда барлық нұсқаудың орындалуы әдеттен тыс аяқталады.
Қашан ALLOW_ROW_LOCKS параметрібелсендірілген (қосулы күйіне орнатылған), жүйе жолды құлыптауды қолданады. Сол сияқты, белсендірілген кезде ALLOW_PAGE_LOCKS параметрі, жүйе параллель қатынас кезінде бетті құлыптауды қолданады. STATISTICS_NORECOMPUTE параметрікөрсетілген көрсеткіш бойынша статистикалық мәліметтерді автоматты түрде қайта есептеу жағдайын анықтайды.
Іске қосылды ONLINE параметрідиалогтық режимде индексті жасауға, қайта жасауға және жоюға мүмкіндік береді. Бұл опция индексті өзгерту кезінде негізгі кестенің немесе кластерленген индекстің деректерін және кез келген байланысты индекстерді бір уақытта өзгертуге мүмкіндік береді. Мысалы, кластерленген индекс қайта жасалып жатқанда, оның деректерін жаңартуды жалғастыруға және сол деректерге сұрауларды орындауға болады.
Параметр ONәдепкі файлдар тобында (әдепкі мән) немесе көрсетілген файл тобында (file_group мәні) көрсетілген индексті жасайды.
Төмендегі мысал Қызметкер кестесінің идентификатор бағанында кластерлік емес индексті құру жолын көрсетеді:
USE SampleDb; CREATE INDEX ix_empid ON Employee(Id);
Бір мәнді құрама индексті жасау төмендегі мысалда көрсетілген:
USE SampleDb; FILLFACTOR БАР ix_empid_prnu ON Works_on (EmpId, ProjectNumber) БІРЕКШЕ ИНДЕКСІН ЖАСАУ = 80;
Бұл мысалда әрбір бағандағы мәндер бір таңбалы болуы керек. Индекс жасалған кезде әрбір индекс түйінінің бетіндегі бос орынның 80% толтырылады.
Бағанда қайталанатын мәндер болса, бағанда бірегей индексті жасай алмайсыз. Мұндай индексті әрбір мән (NULL мәндерін қоса) бағанда дәл бір рет пайда болған жағдайда ғана жасауға болады. Бұған қоса, бар бірегей индекске енгізілген бағанға бар деректер мәнін кірістіру немесе өзгерту әрекетін, егер мән қайталанса, жүйе қабылдамайды.
Индекстің фрагментациясы туралы ақпарат алу
Индекстің қызмет ету мерзімі ішінде ол фрагменттелуі мүмкін, бұл индекс беттеріндегі деректерді сақтау процесін тиімсіз етеді. Индекс фрагментациясының екі түрі бар: ішкі фрагментация және сыртқы фрагментация. Ішкі фрагментация әрбір бетте сақталатын деректердің көлемін анықтайды, ал сыртқы фрагментация беттер логикалық тәртіпте болмаған кезде орын алады.
Ішкі индекс фрагментациясы туралы ақпаратты алу үшін DMV динамикалық басқару көрінісі шақырылады sys.dm_db_index_physical_stats. Бұл DMV көрсетілген беттің деректері мен индекстерінің көлемі мен фрагменті туралы ақпаратты қайтарады. Әрбір бет үшін B+ ағашының әрбір деңгейі үшін бір жол қайтарылады. Осы DMV көмегімен деректер беттеріндегі жолдың фрагментация дәрежесі туралы ақпаратты алуға болады, соның негізінде деректерді қайта ұйымдастыруды шеше аласыз.
sys.dm_db_index_physical_stats көрінісін пайдалану төмендегі мысалда көрсетілген. (Бума үлгісін іске қоспас бұрын, Works_on кестесіне барлық бар индекстерді тастау керек. Индекстерді тастау үшін кейінірек көрсетілетін DROP INDEX операторын пайдаланыңыз.)
USE SampleDb; DECLARE @dbId INT; DECLARE @tabId INT; DECLARE @indId INT; SET @dbId = DB_ID("SampleDb"); SET @tabId = OBJECT_ID («Қызметкер»); sys.dm_db_index_physical_stats FROM (@dbId, @tabId, NULL, NULL, NULL);
Мысалдан көріп отырғаныңыздай, sys.dm_db_index_physical_stats көрінісінде бес параметр бар. Алғашқы үш параметр сәйкесінше ағымдағы дерекқордың, кестенің және индекстің идентификаторларын анықтайды. Төртінші параметр бөлім идентификаторын көрсетеді, ал соңғы параметр статистикалық ақпаратты алу үшін пайдаланылатын сканерлеу деңгейін көрсетеді. (Нақты параметр үшін әдепкі мәнді NULL мәні арқылы көрсетуге болады.)
Бұл көріністегі бағандардың ең маңыздысы - ort_fragmentation_in_percent және avg_page_space_used_in_percent бағандары. Біріншісі фрагментацияның орташа деңгейін пайызбен көрсетеді, ал екіншісі алып жатқан кеңістіктің мөлшерін пайызбен анықтайды.
Индекс ақпаратын өңдеу
Алдыңғы бөлімде талқыланған индексті фрагментациялау ақпаратымен танысқаннан кейін, келесі жүйелік құралдарды пайдаланып осы және басқа индекс ақпаратын өңдеуге болады:
каталог көріністері sys.indexes;
каталог көріністері sys.index_columns;
sp_helpindex жүйелік процедурасы;
objectproperty меншік функциялары;
SQL Server үшін Management Studio басқару ортасы;
DMV динамикалық басқару көрінісі sys.dm_db_index_usage_stats;
DMV динамикалық басқару көрінісі sys.dm_db_missing_index_details.
Каталог көрінісі sys.indexesәрбір индекс үшін жолды және кластерленген индексі жоқ әрбір кесте үшін жолды қамтиды. Бұл каталог көрінісінің ең маңызды бағандары - object_id, атау және index_id бағандары. object_id бағаны индексті иеленетін дерекқор нысанының атын қамтиды, ал атау және index_id бағандарында сәйкесінше сол индекстің аты мен идентификаторы бар.
Каталог көрінісі sys.index_columnsиндекстің немесе үйменің бөлігі болып табылатын әрбір баған үшін жолды қамтиды. Бұл ақпаратты көрсетілген индекстің қасиеттері туралы қосымша ақпаратты алу үшін sys.indexes каталог көрінісі арқылы алынған ақпаратпен бірге пайдалануға болады.
Жүйелік процедура sp_helpindexкесте индекстері туралы ақпаратты, сондай-ақ бағандарға арналған статистикалық ақпаратты қайтарады. Бұл процедураның келесі синтаксисі бар:
sp_helpindex [@db_object = ] "атауы"
Мұнда @db_object айнымалысы кесте атын білдіреді.
Көрсеткіштерге қатысты, объект қасиеті функциясыекі қасиеті бар: IsIndexed және IsIndexable. Бірінші сипат кестенің немесе көріністің индексі бар-жоғы туралы ақпаратты береді, ал екінші сипат кестенің немесе көріністің индекстелетінін көрсетеді.
SQL Server Management Studio арқылы бар индекс ақпаратын өңдеу үшін Дерекқорлар қалтасынан қажетті дерекқорды таңдаңыз, Кестелер түйінін кеңейтіңіз және сол түйінде қажетті кестені және оның Индекстер қалтасын кеңейтіңіз. Кестенің Индекстер қалтасы сол кесте үшін бар барлық индекстердің тізімін көрсетеді. Индексті екі рет басу сол индекстің сипаттары бар Индекс сипаттары диалогтық терезесін ашады. (Сонымен қатар, Management Studio арқылы жаңа индекс жасауға немесе бұрыннан барын жоюға болады.)
Өнімділік sys.dm_db_index_usage_statsиндекс операцияларының әртүрлі түрлерінің санын және әрбір операция түрі соңғы рет орындалғанын қайтарады. Бір сұраудағы көрсетілген индекс бойынша әрбір бөлек іздеу, іздеу немесе жаңарту әрекеті индексті пайдалану болып саналады және сол DMV ішіндегі сәйкес санағышты бір есе арттырады. Осылайша, индекстің қаншалықты жиі қолданылатыны туралы жалпы ақпаратты алуға болады, осылайша оны қай индекстер көбірек және қайсысы аз қолданылып жатқанын анықтау үшін пайдалана аласыз.
Өнімділік sys.dm_db_missing_index_detailsИндекстері жоқ кесте бағандары туралы толық ақпаратты қайтарады. Бұл DMV ең маңызды бағандары index_handle және object_id бағандары болып табылады. Бірінші бағандағы мән нақты жетіспейтін индексті анықтайды, ал екінші бағандағы мән индекс жоқ кестені анықтайды.
Көрсеткіштерді өзгерту
Database Engine мәлімдемені қолдайтын бірнеше дерекқор жүйелерінің бірі болып табылады ӨЗГЕРТУ ИНДЕКС. Бұл мәлімдеме индексті күту операцияларын орындау үшін пайдаланылуы мүмкін. ALTER INDEX операторының синтаксисі CREATE INDEX операторының синтаксисіне өте ұқсас. Басқаша айтқанда, бұл мәлімдеме CREATE INDEX мәлімдемесінде бұрын сипатталған ALLOW_ROW_LOCKS, ALLOW_PAGE_LOCKS, IGNORE_DUP_KEY және STATISTICS_NORECOMPUTE параметрлерінің мәндерін өзгертуге мүмкіндік береді.
Жоғарыда аталған опцияларға қоса, ALTER INDEX мәлімдемесі басқа үш опцияны қолдайды:
Қайта құру параметрі, индексті қайта құру үшін қолданылады;
REORGANIZE параметрі, индекстік түйін беттерін қайта ұйымдастыру үшін қолданылады;
DISABLE параметрі, индексті өшіру үшін пайдаланылады. Бұл үш нұсқа келесі бөлімдерде талқыланады.
Индексті қайта құру
INSERT, UPDATE немесе DELETE мәлімдемелерін пайдаланатын деректерге кез келген өзгерту деректердің фрагментациялануына әкелуі мүмкін. Егер бұл деректер индекстелген болса, индекс ақпараты әртүрлі физикалық беттерге шашыраңқы болуымен индексті фрагментациялау да мүмкін. Индекс деректерінің фрагментациясының нәтижесінде Дерекқор механизмі жалпы жүйе өнімділігін төмендететін қосымша деректерді оқу әрекеттерін орындауға мәжбүр болуы мүмкін. Бұл жағдайда барлық фрагменттелген индекстерді ҚАЙТА ҚҰРУ керек.
Мұны екі жолмен жасауға болады:
ALTER INDEX операторының REBUILD параметрі арқылы;
CREATE INDEX мәлімдемесінің DROP_EXISTING параметрі арқылы.
REBUILD параметрі индекстерді қайта құру үшін пайдаланылады. Осы параметр үшін индекс атауының орнына БАРЛЫҚ көрсетсеңіз, кестедегі барлық индекстер қайта жасалады. (Индекстерді динамикалық түрде қайта жасауға рұқсат беру арқылы оларды түсіріп, қайта жасаудың қажеті жоқ.)
CREATE INDEX мәлімдемесінің DROP_EXISTING опциясы кластерленбеген индекстері де бар кестеде кластерленген индексті қайта жасау кезінде өнімділікті жақсарта алады. Ол бар кластерленген немесе кластерленбеген индексті алып тастау және көрсетілген индексті қайта жасау керектігін көрсетеді. Бұрын айтылғандай, кластерленген кестедегі әрбір кластерленбеген индекс оның ағаш түйіндерінде кестенің кластерленген индексінің сәйкес мәндерін қамтиды. Осы себепті, кластерленген индексті кестеге түсіргенде, оның барлық кластерленбеген индекстерін қайта жасау керек. DROP_EXISTING параметрін пайдалану кластерленбеген индекстерді қайта жасауды болдырмайды.
DROP_EXISTING опциясы ҚАЙТА ҚҰРУ опциясына қарағанда қуаттырақ, себебі ол икемді және индексті құрайтын бағандарды өзгерту және кластерленбеген индексті кластерленгенге өзгерту сияқты бірнеше опцияларды ұсынады.
Индекс түйінінің беттерін қайта ұйымдастыру
ALTER INDEX операторының REORGANIZE параметрі көрсетілген индекстегі түйіндердің беттерін солдан оңға қарай беттердің физикалық реті олардың логикалық тәртібіне сәйкес келетіндей етіп қайта реттейді. Бұл индекс өнімділігін жақсарта отырып, белгілі бір индекс фрагментациясын жояды.
Индексті өшіру
DISABLE опциясы көрсетілген индексті өшіреді. Өшірілген индекс қайта қосылмайынша пайдалану үшін қол жетімді емес. Байланысты деректерге өзгертулер енгізілгенде өшірілген индекс өзгермейтінін ескеріңіз. Осы себепті өшірілген индексті қайта пайдалану үшін оны толығымен қайта жасау керек. Өшірілген индексті қосу үшін ALTER TABLE операторының ҚАЙТА ҚҰРУ опциясын пайдаланыңыз.
Кестедегі кластерленген индекс өшірілгенде, кестенің деректері қол жетімді болмайды, себебі кластерленген индексі бар кестенің барлық деректер беттері оның ағаш түйіндерінде сақталады.
Индекстерді жою және атын өзгерту
Ағымдағы дерекқордағы индекстерді жою үшін пайдаланыңыз DROP INDEX нұсқауы. Кластерленген индексті кестеге тастау өте ресурстарды қажет ететін операция болуы мүмкін екенін ескеріңіз, себебі Барлық кластерленбеген индекстерді қайта жасау қажет болады. (Барлық кластерленбеген индекстер түйін беттерінде көрсеткіш ретінде кластерленген индекстің индекс кілтін пайдаланады.) Индексті тастау үшін DROP INDEX мәлімдемесін пайдалану төмендегі мысалда суреттелген:
USE SampleDb; DROP INDEX ix_empid ON Employee;
DROP INDEX нұсқаулығында қосымша бар MOVE TO параметр, мағынасы CREATE INDEX операторының ON параметрімен бірдей. Басқаша айтқанда, бұл параметрді кластерленген индекс түйіні беттеріндегі деректер жолдарының қайда жылжытылатынын көрсету үшін пайдалануға болады. Деректер үйме ретінде жаңа орынға жылжытылады. Жаңа деректерді сақтау орны үшін әдепкі файл тобын немесе аталған файл тобын көрсетуге болады.
DROP INDEX мәлімдемесі PRIMARY KEY және UNIQUE индекстері сияқты тұтастық шектеулері үшін жүйемен жасырын түрде жасалған индекстерді тастау үшін пайдаланыла алмайды. Мұндай индекстерді жою үшін сәйкес шектеуді алып тастау керек.
Индекстердің атын sp_rename жүйелік процедурасы арқылы өзгертуге болады.
Сондай-ақ, индекстерді Database Diagrams немесе Object Explorer көмегімен Management Studio бағдарламасында жасауға, өзгертуге және жоюға болады. Бірақ ең оңай жолы - қажетті кестенің Индекстер қалтасын пайдалану. Management Studio бағдарламасындағы индекстерді басқару Management Studio бағдарламасындағы кестелерді басқаруға ұқсас.
Дерекқор жүйесі индекстер санына практикалық шектеу қоймаса да, олардың санын шектеудің бірнеше себебі бар. Біріншіден, әрбір индекс дискілік кеңістіктің белгілі бір көлемін алады, сондықтан деректер қорының индекс беттерінің жалпы саны деректер қорындағы деректер беттерінің санынан асып кету мүмкіндігі бар. Екіншіден, деректерді алу үшін индексті пайдаланудың артықшылығынан айырмашылығы, деректерді енгізу және жою индексті сақтау қажеттілігіне байланысты мұндай артықшылықты қамтамасыз етпейді. Кестеде индекстер неғұрлым көп болса, оларды қайта ұйымдастыру үшін соғұрлым көп жұмыс қажет. Жалпы ереже бойынша, жиі сұраулар үшін индекстерді таңдап, содан кейін олардың қолданылуын бағалаған дұрыс.
Бұл бөлімде индекстерді құру және пайдалану бойынша кейбір нұсқаулар берілген. Төмендегі ұсыныстар жалпы ережелер ғана. Сайып келгенде, олардың тиімділігі дерекқордың тәжірибеде қалай қолданылатынына және жиі орындалатын сұраулардың түріне байланысты болады. Ешқашан пайдаланылмайтын бағанды индекстеу жақсы нәтиже бермейді.
Индекстер және WHERE сөйлемінің шарттары
SELECT операторының WHERE сөйлемінде бір баған бар іздеу шарты болса, сол бағанда индекс жасалуы керек. Бұл әсіресе жоғары селективті жағдайларда ұсынылады. Шарттың таңдамалылығы деп шартты қанағаттандыратын жолдар санының кестедегі жолдардың жалпы санына қатынасын түсінеміз. Жоғары селективтілік осы қатынастың төменгі мәніне сәйкес келеді. Индекстелген бағанды пайдаланып іздеуді өңдеу шарттың таңдау мүмкіндігі 5%-дан аз болғанда сәтті болады.
Шарттың селективтілік деңгейі тұрақты 80% немесе одан жоғары болса, баған индекстелмеуі керек. Бұл жағдайда индекс беттері қосымша енгізу/шығару операцияларын қажет етеді, бұл индекстерді пайдалану арқылы қол жеткізілген уақытты үнемдеуді азайтады. Бұл жағдайда кестені сканерлеу арқылы іздеуді орындау жылдамырақ болады, бұл сұранысты оңтайландырушы әдетте таңдайды, бұл индексті пайдасыз етеді.
Жиі қолданылатын сұраудың іздеу шарты ЖӘНЕ операторларын қамтыса, ТАҢДАУ операторының WHERE тармағында көрсетілген кесте бағандарының барлығында құрама индексті жасау ең жақсы нұсқа болып табылады. Мұндай құрама индексті құру төмендегі мысалда көрсетілген:
Бұл мысал WHERE сөйлемінің барлық бағандарында құрама индекс жасайды. Бұл сұрауда екі шарт бірге ЖӘНЕ болып табылады, сондықтан сол шарттарда екі бағанда да құрама кластерленбеген индекс жасау керек.
Индекстер және біріктіру операторы
Біріктіру әрекеті үшін қосылатын әрбір бағанға индекс жасау ұсынылады. Біріктірілген бағандар көбінесе бір кестенің бастапқы кілтін және басқа кестенің сәйкес сыртқы кілтін білдіреді. Сәйкес біріктіру бағандарында PRIMARY KEY және FOREIGN KEY тұтастық шектеулерін көрсетсеңіз, сыртқы кілт бағанында кластерленбеген индексті ғана жасауыңыз керек, себебі жүйе жанама түрде негізгі кілт бағанында кластерленген индекс жасайды.
Төмендегі мысал біріктіру әрекеті және қосымша сүзгісі бар сұрауыңыз болса, пайдаланылатын индекстерді қалай жасау керектігін көрсетеді:
Қамту индексі
Жоғарыда айтылғандай, индекстегі барлық сұрау бағандарын қосу сұрау өнімділігін айтарлықтай жақсарта алады. Жабу деп аталатын мұндай индексті құру төмендегі мысалда көрсетілген:
AdventureWorks2012 пайдалану; GO DROP INDEX Person.Address.IX_Address_StateProvinceID; GO CREATE INDEX ix_address_zip ON Тұлға.Мекенжайы(Пошта коды) ҚҰРУ(Қала, ШтатПровинцияID); ТАҢДАУ қала, штатПровинция идентификаторы Тұлғадан.Адрес ҚАЙДА Пошта коды = 84407;
Бұл мысал алдымен Мекенжай кестесінен IX_Address_StateProvinceID индексін жояды. Содан кейін Пошта коды бағанына қосымша екі қосымша бағанды қамтитын жаңа индекс жасалады. Соңында, мысалдың соңындағы ТАҢДАУ мәлімдемесі индекспен қамтылған сұрауды көрсетеді. Бұл сұрау үшін жүйеге деректер үшін деректер беттерін іздеудің қажеті жоқ, себебі сұрау оңтайландырғышы кластерленбеген индекс түйін беттеріндегі барлық баған мәндерін таба алады.
Индекс беттерінде әдетте сәйкес деректер беттерінен көбірек жазбалар бар болғандықтан, жабын индекстері ұсынылады. Бұған қоса, бұл әдісті пайдалану үшін сүзгіленетін бағандар индекстегі бірінші негізгі бағандар болуы керек.
Есептелген бағандардағы индекстер
Database Engine келесі арнайы индекс түрлерін жасауға мүмкіндік береді:
индекстелген көріністер;
фильтрленетін индекстер;
есептелген бағандар бойынша индекстер;
бөлінген индекстер;
бағанның тұрақтылық индекстері;
XML индекстері;
толық мәтінді индекстер.
Бұл бөлімде есептелген бағандар және олармен байланысты индекстер талқыланады.
Есептелген бағанкесте деректерін есептеу нәтижелері сақталатын кесте бағаны болып табылады. Мұндай баған виртуалды немесе тұрақты болуы мүмкін. Бағандардың осы екі түрі келесі бөлімшелерде талқыланады.
Виртуалды есептелген бағандар
Сәйкес кластерленген индексі жоқ есептелген баған логикалық баған болып табылады, яғни. ол қатты дискіде физикалық түрде сақталмайды. Осылайша, ол жолға қол жеткізген сайын бағаланады. Виртуалды есептелген бағандарды пайдалану төмендегі мысалда көрсетілген:
USE SampleDb; КЕСТЕ ТАПСЫРМАЛАРЫН ЖАСАУ (Тапсырыс идентификаторы INT NULL ЕМЕС, Баға MONEY NULL ЕМЕС, Саны INT NULL ЕМЕС, ТапсырысКүні DATETIME NULL ЕМЕС, Барлығы Баға АСҚАН * Саны, ЖіберілгенКүні КҮНІ ҚОСУ (КҮН, 7, тапсырыс күні));
Бұл мысалдағы Тапсырыстар кестесінде екі виртуалды есептелген баған бар: жалпы және жөнелтілген күні. Жалпы баған екі басқа бағанды, баға мен санды пайдаланып есептеледі, ал жөнелтілген күні бағаны DATEADD функциясы мен тапсырыс күні бағаны арқылы есептеледі.
Тұрақты есептелген бағандар
Деректер қоры механизмі негізгі бағандарда нақты деректер түрлері бар детерминирленген есептелген бағандарда индекстер жасауға мүмкіндік береді. (Есептелген баған детерминирленген деп аталады, егер ол әрқашан бірдей кесте деректері үшін бірдей мәндерді қайтарса.)
Индекстелген есептелген бағанды SET операторының келесі параметрлері ON күйіне орнатылған жағдайда ғана жасауға болады (бұл параметрлер бағанның детерминирленген болуын қамтамасыз етеді):
QUOTED_IDENTIFIER
CONCAT_NULL_YIELDS_NULL
Бұған қоса, NUMERIC_ROUNDABORT параметрі өшірулі күйге орнатылуы керек.
Есептелген бағанда кластерленген индекс жасасаңыз, бағанның мәндері сәйкес кесте жолдарында физикалық түрде болады, себебі кластерленген индекстің түйін беттерінде деректер жолдары бар. Келесі мысал Тапсырыстар кестесіндегі есептелген баған жиынында кластерленген индексті жасайды:
USE SampleDb; КЛАСТЕРЛІК КӨРСЕТКІШТІ ҚҰРУ ix1 ON Тапсырыстар (Барлығы);
CREATE INDEX операторын орындағаннан кейін есептелген жалпы баған кестеде физикалық түрде болады. Бұл есептелген бағанның негізгі бағандарының барлық жаңартулары оның жаңартылуына себеп болатынын білдіреді.
Бағанды басқа жолмен тұрақты етіп жасауға болады PERSISTED параметрі. Бұл опция тіпті сәйкес кластерленген индексті жасамай-ақ есептелген бағанның физикалық болуын көрсетуге мүмкіндік береді. Бұл мүмкіндік шамамен деректер түрі (жүзу немесе нақты) бар бағандарда жасалатын физикалық есептелген бағандарды жасау үшін қажет. (Бұрын айтылғандай, индексті тек есептелген бағандарда жасауға болады, егер оның негізгі бағандары нақты деректер түріне жатады.)
Жаңадан бастаушыларға арналған бұл мақалада мен SQL сұрауларын орындау жылдамдығын арттыру үшін қажетті индекстерді қалай анықтау керектігін қарастырамын.
Шын мәнінде, бір бағытта да, қарама-қарсы бағытта да өнімділікке айтарлықтай әсер ететін индекстермен байланысты көптеген нәзіктіктер бар. Интернетте бұл туралы көптеген мақалаларды таба аласыз. Адрестеу, жадты сақтау және басқа да көптеген нәрселердегі айырмашылықтарды түсіндіретін көлемді мақалалар.
Бұл, әрине, шынымен пайдалы нәрселер, бірақ олар көбінесе бір ғана нюансты жіберіп алады - бұл барлық мүмкіндіктер шынымен айтарлықтай әсер ететін деректер көлемі. Және бұл көрсеткіш әдетте жүздеген мың жазбалармен өлшенеді. Қарапайым сөзбен айтқанда, егер сіздің кестелеріңізде шамамен 1-30 мың жазбалар болса және біз жүктелген жүйелер үшін деректерді аралық сақтаудың қандай да бір түрі емес, веб-сайт (немесе ұқсас ресурс) туралы айтатын болсақ, онда көбінесе бұл маңыздырақ. жай ғана дұрыс индекстерді жасаңыз. Бұл жерде сізге техникалық тұрғыдан өте сауатты болудың қажеті жоқ екенін ескеру маңызды. Көптеген пайдалы индекстерді қарапайым логика арқылы құруға болады.
Ескерту: Бұл сұраулардың өзі азды-көпті оңтайлы түрде құрастырылғанын болжайды, мысалы, таңдауда қосымша өрістер жоқ және т.б.
Бүтін идентификатор өрістеріне арналған индекс.
Егер сізде бүтін идентификаторы бар өріс болса (ол кестенің идентификаторы ма, әлде басқа кестедегі жолды көрсететін идентификатор ма маңызды емес), онда ол үшін бөлек индекс құрыңыз.
Мәселе мынада. Егер өріс кестенің өзінде жазбалардың идентификаторы болса, онда біз бастапқы кілт туралы айтып отырмыз (ол да индекс). Мұндай индекстің көптеген артықшылықтары бар, өйткені сайттар көбінесе идентификаторлармен жұмыс істейді. Егер бұл каталог кестесіндегі жол идентификаторы болса, индекс те қажет. Егер сізге сүзгіден өткен деректер қажет болса, индекстерсіз бұл каталогтар көп қажет емес (мүмкін, деректер қорының өлшемі ғана).
Егер бірінші жағдайда бәрі қарапайым және түсінікті болса, екінші жағдайда (анықтамалық кітаппен) мен қарапайым мысал келтіремін.
Екі кесте бар делік: мақалалар (мақала - идентификатор, атау, мәтін) және түсініктемелер (түсініктеме - id, article_id, мәтін). Бірінші кестеде 200 жазба (мақала), екінші кестеде 2000 жазба (әр мақалаға 10 түсініктеме). Тиісінше, әрбір пайдаланушы кез келген мақаланы ашқанда, келесі сұрау орындалады:
Егер sql сұрауы article_id өрісі үшін индекссіз орындалса, онда түсініктемелері бар бүкіл кесте (барлық 2000 жазба) әр жолы толығымен сканерленеді. Егер article_id өрісі үшін индекс қосылса, онда дерекқор 20-дан аспайтын жазбаларды қарауы керек (дәлірек айтқанда, ең нашар жағдайда шамамен 18). Мұнда есептеу қарапайым. Ең нашар жағдайда, индекстік іздеу жазбалар санының екілік логарифмінің шамамен жылдамдығында + индекс өрісінің бірдей мәні бар жазбалар санының жылдамдығында орын алады. Бұл жағдайда әрбір мақалада 10 жазба бар (олардың мәндері қайталанады) + 200-ден log2 (өйткені 200 мақала бар = 2000/10) = 10 + 8 (дөңгелектелген) = 18.
Әрине, әрбір мұндай индекс, ол алатын дискілік кеңістіктен басқа, кірістіру, жаңарту және жою үшін қосымша дерекқорды қосады. Өйткені, кестенің деректерін өзгертуден басқа, оның индекстерін де қайта құру қажеттілігі туындайды. Бірақ, жоғарыда айтқанымдай, тұрақты веб-сайттардың көлемі үшін бұл үлкен мәселе емес. Егер сіз кестеде sql сұрауларыңызда пайдаланбайтын индексті жасасаңыз да, бұл айтарлықтай проблемаларды тудырмайды. Бұған қоса, қосымша модульді орнату немесе сұрауларды өзіңіз қосу арқылы бұл индекс өте ыңғайлы болуы мүмкін.
Ескерту: Дегенмен, бұл «барлық мүмкін өрістер үшін индекстер жасауға рұқсат етіңіз» опциясына емес, арнайы бүтін индекстерге қатысты екенін есте сақтаңыз.
Ең көп таралған сұрауларға арналған қарапайым және құрама индекстер.
Көптеген дерекқорларда сұраулар үшін нәтиже кэші бар. Бір сұранысты екі рет қатарынан орындауға тырысыңыз - бірінші жағдайда сұрауды орындау үшін көп уақыт қажет, екінші рет тез. Бірінші рет деректер есептеледі, екінші рет деректер кэштен беріледі. Дегенмен, бұл кэш сұраулар үшін құрылмаған жағдайларда (мысалы, сүзгіде кірістірілген дерекқор функцияларын пайдаланып есептелген шарттар болған кезде) көп көмектеспейді, сұраулар бір типті болса да, әртүрлі жағдайларда пайдаланылады. параметрлерді және сұраулар көп болған жағдайда, сондықтан деректер кэште өте қысқа уақыт ішінде сақталады.
Сондықтан мерзімді түрде жиі орындалатын сұраулар үшін тұрақты және құрама индекстерді қосымша құрастыру мағынасы бар. Екі мысалды қарастырайық.
Қарапайым индекс.
Сізде кесте – өнімдер (өнім – идентификатор, код, атау, мәтін) бар делік. Сайт пайдаланушылары өнімді әріптік-цифрлық кодтары бойынша жиі іздейді (мақалалар - код өрісі). Тиісінше, сұрау келесідей көрінеді:
Бұл жағдайда «код» өрісі үшін жеке индексті жасау мағынасы бар, өйткені онымен деректер базасы кестедегі барлық жазбаларды толығымен сканерлеудің қажеті жоқ. Дегенмен, дерекқорларда өріс түрлері мен өлшемдері бойынша шектеулер болуы мүмкін екенін ескеріңіз. Сондықтан алдымен мұндай өрістер үшін индекс құру мүмкіндігін тексеру керек.
Құрама индекс.
Құрама индексі бар мысал келтірмес бұрын, мен бір маңызды мәселені аздап түсіндіргім келеді - индекстегі өрістердің реті маңызды. Іздеу алдымен бірінші өріс бойынша, содан кейін келесі (және т.б.) арқылы жүзеге асырылады. Сондықтан, егер сіз тек соңғы өрістің нақты мәнін білсеңіз, онда мұндай индекс жарамайды, өйткені бірінші өрістің нақты мәнін білмей, қандай жазбалар жинағын тексеру қажет екенін анықтау мүмкін емес. неге дерекқор кестедегі барлық жазбаларды сканерлеуі керек. Қарапайым сөзбен айтқанда, индекс (баған_1, баған_2) индекске (баған_2, баған_1) тең емес.
Енді келесі жағдайды алайық. Үш кесте бар: пайдаланушы (пайдаланушы - идентификатор, атау), санат (мысық - идентификатор, атау) және мақала (мақала - id, cat_id, user_id, атау, мәтін). Сіз сайтта осындай әрекет жасадыңыз - мақаланың төменгі жағында сол санаттағы бір пайдаланушының мақалаларының толық тізімі көрсетіледі. Сонымен қатар, пайдаланушылар әр түрлі санаттарда болса да (мысалы, шағын әңгімелер, қысқа жазбалар және т.б.) көптеген мақалалар жазатыны соншалық. Бұл жағдайда сұрау келесідей болады:
Егер сіз идентификатор өрістері үшін индекстер жасаған болсаңыз, бұл сізге көмектеседі, бірақ көп емес. Біріншіден, екі бірдей ықтимал индекс бар. Біреуі санаттар үшін, екіншісі пайдаланушылар үшін. Қайсысы жақсы болатыны белгісіз. Сондай-ақ, бұл көп көмектеспеуі мүмкін, өйткені пайдаланушыларда 1000 мақала және санаттарда 1000 мақала болуы мүмкін. Екіншіден, белгілі бір пайдаланушыға (немесе санатқа) арналған жазбаларды азайтқанның өзінде, олар әлі де екінші өрісті, яғни толық сканерлеуді (жазбалардың кішірек көлеміне қарамастан) пайдаланып сканерлеуге тура келеді. Мысалы, егер пайдаланушыларда 1000 жазба болса, олардың санатқа жататын-жатпағанын тексеру үшін барлық 1000 жазбаны тексеру керек болады.
Көптеген жазбалар мен жиі қоңыраулар үшін бұл өте қымбат sql сұрауы. Сондықтан, бұл жағдайда, мысалы, (user_id, cat_id) құрамдас индексті жасау керек, бұл жағдайда пайдаланушы бойынша іздеуден кейін санат бойынша кейінгі іздеу жылдамырақ болады, өйткені нәтиже үшін де индекс болады. жазбалар. Тиісінше, 1000 жазбаны тексерудің орнына айтарлықтай азырақ тексеріледі (тексерулер кәдімгі индекстегідей есептеледі - логарифм + жазбалар саны).
Мұндай жағдайларда өрістердің ретін қалай анықтауға болады? Мұнда бәрі өте қарапайым және мен сүзу туралы мақалада сипаттағанға ұқсас (бастапқы сілтемені қараңыз). Естеріңізге сала кетейін, мәселе әрбір сүзгі қолданылған сайын жазбалар саны мүмкіндігінше азаяды. Сондықтан кестедегі әрбір өріс мәні үшін жазбалардың орташа санын тексеру мағынасы бар. Ал осы сан аз өріс бірінші болуы керек. Мысалы, берілген SQL сұрауы үшін мынаны тексерген жөн:
Таңдалған пайдаланушылар үшін жазбалардың орташа санын есептеңіз -- Жазбалардың орташа саны авг(деректер саны) ортасынан бастап -- Барлық жазбаларды идентификатор бойынша топтаңыз (мақаладан "санақ" ретінде санауды(*) таңдаңыз -- Пайдаланушылар бойынша топтау user_id) деректер ретінде; -- Таңдалған санаттар үшін жазбалардың орташа санын есептеңіз -- Жазбалардың орташа саны ортаңғы (деректер саны) бастап орташа -- Барлық жазбаларды идентификатор бойынша топтаңыз (мақаладан "санақ" ретінде санауды(*) таңдаңыз -- Санат бойынша топтаңыз. cat_id бойынша топтау) деректер ретінде;
Тиісінше, егер пайдаланушылардың орташа саны аз болса, онда бұл өріс бірінші орында тұруы керек, өйткені бірінші іздеуден кейін тексерілетін жазбалар аз болады. Әйтпесе, санат идентификаторы бірінші болуы керек.
Дегенмен, мұндай жағдайда жазбалардың азды-көпті біркелкі таратылғанын тексеру керек екенін түсіну керек. Өйткені, 1 қолданушы 2000 мақала жазған, ал қалғандары 100-ге жуық мақала жазғаны белгілі болуы мүмкін. Мұндай жағдайда санат бойынша сүзгіден өткен дұрыс, өйткені оқырмандардың көпшілігі осы пайдаланушының мақалаларын қарайды. Сондықтан кейде идентификаторлар бойынша топтастыруды ғана есептеп (орташа мәнді есептемей) және нәтижелерді жылдам қарау керек.
Егер сізге үш немесе одан да көп өрістер үшін индекс жасау қажет болса, идентификатор арқылы топтастыру жүзеге асырылатын өрістер санын көбейту арқылы дәл солай істеу керек. Қарапайым сөзбен айтқанда, алдымен бірінші өрісті тексеріп, ең кіші санды анықтаңыз, содан кейін «баған_1 бойынша топтау» орнына «баған_1, баған_2 бойынша топтау», содан кейін «баған_1, баған_3 бойынша топтау» түріндегі қалған өрістермен әртүрлі опцияларды көрсетіңіз. және тағы басқа. Бұл жағдайда әрбір адам жазбалардың орташа саны азайып, кішірейетін комбинацияларды таңдайды.
Және индекстер, бұл арнайы іздеу кестелері, бұл дерекқор іздеу жүйесі деректерді іздеуді жылдамдату үшін пайдалана алады. Қарапайым тілмен айтқанда, индекс кестедегі деректерге арналған көрсеткіш. Дерекқордағы индекс кітаптың артындағы индекске өте ұқсас.
Мысалы, белгілі бір тақырып бойынша кітаптың барлық беттеріне сілтемелер қажет болса, алдымен барлық тақырыптарды алфавиттік ретпен тізімдейтін, содан кейін бір немесе бірнеше нақты бет нөмірлеріне сілтеме жасайтын индексті қараңыз.
Индекс сұраулар мен сөйлемдерді жылдамдатуға көмектеседі, бірақ ол мәлімдемелермен деректерді енгізуді баяулатады ЖАҢАРТУЖәне INSERT. Индекстерді деректерге әсер етпестен жасауға немесе жоюға болады.
Индекс жасау мәлімдемені қамтиды ИНДЕКС ЖАСАУ, ол кестені және қай бағанды немесе бағандарды индекстеу керектігін және индекстің өсу немесе кему ретімен екенін көрсету үшін индексті атауға мүмкіндік береді.
Шектеумен индекстер де бірегей болуы мүмкін ЕРЕКШЕ, осылайша индекс бағандағы немесе индексі бар бағандар тіркесіміндегі қайталанатын жазбаларды болдырмайды.
CREATE INDEX командасы
Негізгі синтаксис ИНДЕКС ЖАСАУкелесідей:
CREATE INDEX index_name ON table_name;
Бір бағанды индекстер
Бір бағанды индекс кестенің тек бір бағанында жасалады. Негізгі синтаксис келесідей.
CREATE INDEX index_name ON кесте_аты(баған_атауы);
Бірегей индекстер
Бірегей индекстер жұмыс істеу үшін ғана емес, сонымен қатар деректердің тұтастығын қамтамасыз ету үшін де қолданылады. Бірегей индекс кестеге қайталанатын мәндерді енгізуге мүмкіндік бермейді. Негізгі синтаксис келесідей.
Кесте_атында (баған_атауы) БІРЕКЕ ИНДЕКС индекс_атын ҚҰРУ;
Құрама индекстер
Құрама индекс – кестенің екі немесе одан да көп бағандарындағы индекс. Оның негізгі синтаксисі төмендегідей.
Кесте_атында INDEX INDEX INDEX КӨРСЕТУ(1-баған, 2-баған);
Жалғыз бағанда немесе құрама индексте индексті жасауыңызға қарамастан, сүзгі шарты ретінде WHERE сұрауында өте жиі қолдануға болатын бағандарды (ларды) ескеріңіз.
Егер бір ғана баған қолданылса, бір бағанда индексті таңдау керек. WHERE сөйлемінде сүзгілер ретінде жиі пайдаланылатын екі немесе одан да көп бағандар болса, құрама индекс жақсы таңдау болар еді.
Айқын емес индекстер
Жасырын емес индекстер – нысан жасалғанда дерекқор серверінде автоматты түрде жасалатын индекстер. Индекстер бастапқы кілтте және бірегей шектеуде автоматты түрде жасалады.
DROP INDEX командасы
Индексті SQL пәрмені арқылы жоюға болады TROP. Индексті жою кезінде абай болу керек, себебі өнімділік баяу немесе жақсырақ болуы мүмкін.
Негізгі синтаксис келесідей:
DROP INDEX индекс_атауы;
Индекстерде кейбір нақты мысалдарды көру үшін INDEX шектеу мысалын қарауға болады.
Индекстерден қашан аулақ болу керек?
Индекстер дерекқор өнімділігін жақсартуға арналған болса да, олардан аулақ болу керек кездер болады.
Төмендегі нұсқаулар индексті пайдалануды қашан қайта қарау керектігін көрсетеді.
- Кішігірім кестелерде индекстерді қолдануға болмайды.
- Жиі үлкен жаңарту немесе кірістіру әрекеттері бар кестелер.
- Индекстерді бос мәндердің үлкен санын қамтитын бағандарда қолдануға болмайды.
- Жиі өңделетін бағандарды индекстеуге болмайды.