Индексүүд- Энэ бол таны ажилд хамгийн түрүүнд сайн ойлгох ёстой зүйл юм SQL сервер, гэхдээ хачирхалтай нь үндсэн асуултуудыг форум дээр тийм ч олон асуудаггүй бөгөөд олон хариулт авдаггүй.
Роб Шелдондахь индексүүдийн талаар мэргэжлийн хүрээлэлд төөрөгдөл үүсгэж буй эдгээр асуултад хариулдаг SQL сервер: Тэдний заримыг нь бид зүгээр л асуухаас ичдэг, гэхдээ бусдаас асуухаасаа өмнө эхлээд хоёр удаа бодох болно.
Ашигласан нэр томъёо:
| индекс | индекс |
| овоо | баглаа |
| ширээ | ширээ |
| харах | гүйцэтгэл |
| Б мод | тэнцвэртэй мод |
| кластер индекс | кластер индекс |
| бөөгнөрөлгүй индекс | бөөгнөрөлгүй индекс |
| нийлмэл индекс | нийлмэл индекс |
| хамрах индекс | хамрах индекс |
| үндсэн түлхүүрийн хязгаарлалт | үндсэн түлхүүрийн хязгаарлалт |
| өвөрмөц хязгаарлалт | үнэт зүйлсийн өвөрмөц байдлыг хязгаарлах |
| асуулга | хүсэлт |
| асуулгын хөдөлгүүр | асуулгын дэд систем |
| мэдээллийн сан | мэдээллийн сан |
| мэдээллийн сангийн хөдөлгүүр | хадгалах дэд систем |
| дүүргэх хүчин зүйл | индекс дүүргэх хүчин зүйл |
| орлуулагч үндсэн түлхүүр | орлуулагч үндсэн түлхүүр |
| асуулга оновчтой болгох | асуулга оновчтой болгох |
| индекс сонгох чадвар | индекс сонгох чадвар |
| шүүсэн индекс | шүүж болох индекс |
| гүйцэтгэх төлөвлөгөө | гүйцэтгэх төлөвлөгөө |
SQL сервер дэх индексүүдийн үндэс.
Өндөр бүтээмжид хүрэх хамгийн чухал арга замуудын нэг SQL сервериндекс ашиглах явдал юм. Номон дээрх индекс нь танд хэрэгтэй мэдээллээ хурдан олоход тусалдагтай адил индекс нь хүснэгтийн мөрийн өгөгдлүүдэд хурдан хандах боломжийг олгож асуулгын процессыг хурдасгадаг. Энэ нийтлэлд би индексийн товч тоймыг өгөх болно SQL сервермөн тэдгээр нь мэдээллийн санд хэрхэн зохион байгуулагдаж, мэдээллийн сангийн асуулгыг хурдасгахад хэрхэн тусалдаг талаар тайлбарлана уу.
Хүснэгт болон харах баганууд дээр индексүүдийг үүсгэнэ. Индексүүд нь эдгээр баганын утгууд дээр үндэслэн өгөгдлийг хурдан хайх боломжийг олгодог. Жишээлбэл, хэрэв та үндсэн түлхүүр дээр индекс үүсгээд дараа нь үндсэн түлхүүр утгуудыг ашиглан өгөгдлийн мөр хайвал SQL серверэхлээд индексийн утгыг олж, дараа нь өгөгдлийн бүх мөрийг хурдан олохын тулд индексийг ашиглана. Индексгүй бол хүснэгтийн бүх мөрийг бүрэн сканнердах бөгөөд энэ нь гүйцэтгэлд ихээхэн нөлөөлнө.
Та хүснэгт эсвэл харагдацын ихэнх баганууд дээр индекс үүсгэж болно. Үл хамаарах зүйл бол том объектуудыг хадгалах өгөгдлийн төрөл бүхий баганууд юм ( LOB), гэх мэт зураг, текстэсвэл varchar(хамгийн их). Мөн та өгөгдлийг форматаар хадгалах зориулалттай баганууд дээр индекс үүсгэж болно XML, гэхдээ эдгээр индексүүд нь стандартаас арай өөр бүтэцтэй бөгөөд тэдгээрийг авч үзэх нь энэ зүйлийн хамрах хүрээнээс гадуур юм. Түүнчлэн, нийтлэлийг хэлэлцэхгүй баганын дэлгүүриндексүүд. Үүний оронд би мэдээллийн санд хамгийн түгээмэл хэрэглэгддэг индексүүд дээр анхаарлаа хандуулдаг SQL сервер.
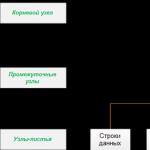
Индекс нь модны бүтцээр зохион байгуулагдсан хуудас, индексийн зангилаанаас бүрдэнэ. тэнцвэртэй мод. Энэ бүтэц нь шаталсан шинж чанартай бөгөөд зурагт үзүүлсэн шиг шатлалын дээд хэсэгт байрлах үндэс зангилаа ба навчны зангилаа, доод талд нь навчнаас эхэлдэг.
Индексжүүлсэн баганаас асуулга хийх үед асуулгын систем нь үндсэн зангилааны дээд хэсгээс эхэлж, завсрын цэгүүдээр дамжин доошилдог бөгөөд завсрын давхарга бүр өгөгдлийн талаарх дэлгэрэнгүй мэдээллийг агуулсан байдаг. Асуулгын систем нь индексийн навчтай доод түвшинд хүрэх хүртэл индексийн зангилаануудаар үргэлжлүүлэн хөдөлдөг. Жишээлбэл, хэрэв та индексжүүлсэн баганаас 123 утгыг хайж байгаа бол хайлтын систем эхлээд эх түвшний эхний завсрын түвшний хуудсыг тодорхойлно. Энэ тохиолдолд эхний хуудас нь 1-ээс 100 хүртэлх утгыг, хоёр дахь нь 101-ээс 200 хүртэлх утгыг заадаг тул асуулгын систем энэ дунд түвшний хоёр дахь хуудсанд хандах болно. Дараа нь та дараагийн дунд шатны гуравдугаар хуудас руу шилжих ёстойг харах болно. Эндээс асуулгын дэд систем нь индексийн утгыг өөрөө доод түвшинд унших болно. Индексийн хуудас нь индексийн төрлөөс хамааран хүснэгтийн өгөгдлийг өөрөө эсвэл зүгээр л хүснэгтийн өгөгдөл бүхий мөрүүдийг зааж өгөх заагч байж болно: кластер индекс эсвэл бөөгнөрөлгүй индекс.
Кластер индекс
Кластерт индекс нь индексийн навч дахь өгөгдлийн бодит мөрүүдийг хадгалдаг. Өмнөх жишээ рүү буцах юм бол энэ нь 123 гэсэн түлхүүр утгатай холбоотой өгөгдлийн мөр нь өөрөө индекст хадгалагдана гэсэн үг юм. Кластерт индексийн чухал шинж чанар нь бүх утгыг тодорхой дарааллаар, өсөх эсвэл буурах байдлаар эрэмбэлдэг явдал юм. Тиймээс хүснэгт эсвэл харагдац нь зөвхөн нэг кластер индекстэй байж болно. Нэмж дурдахад, энэ хүснэгтэд кластер индекс үүсгэсэн тохиолдолд л хүснэгт дэх өгөгдөл эрэмбэлэгдсэн хэлбэрээр хадгалагдана гэдгийг тэмдэглэх нь зүйтэй.
Кластерт индексгүй хүснэгтийг овоолго гэж нэрлэдэг.
Кластерт бус индекс
Кластерт индексээс ялгаатай нь кластергүй индексийн навч нь зөвхөн тэдгээр багануудыг агуулна ( түлхүүр) нь энэ индексийг тодорхойлдог бөгөөд мөн хүснэгтийн бодит өгөгдөл бүхий мөрүүдийн заагчийг агуулна. Энэ нь дэд асуулгын систем нь шаардлагатай өгөгдлийг олох, олж авах нэмэлт үйлдлийг шаарддаг гэсэн үг юм. Өгөгдлийн заагчийн агуулга нь өгөгдөл хэрхэн хадгалагдаж байгаагаас хамаарна: кластер хүснэгт эсвэл нуруулдан. Хэрэв заагч нь бөөгнөрсөн хүснэгтийг зааж байгаа бол энэ нь бодит өгөгдлийг олоход ашиглаж болох кластерын индексийг заана. Хэрэв заагч нь овоолгыг илэрхийлдэг бол энэ нь тодорхой өгөгдлийн мөр танигчийг заана. Бүлэглэгдээгүй индексүүдийг кластерт индексүүд шиг эрэмбэлэх боломжгүй, гэхдээ та хүснэгт эсвэл харагдац дээр 999 хүртэл нэгээс олон кластергүй индекс үүсгэж болно. Энэ нь аль болох олон индекс үүсгэх ёстой гэсэн үг биш юм. Индексүүд нь системийн гүйцэтгэлийг сайжруулж эсвэл бууруулж болно. Олон тооны кластергүй индекс үүсгэхээс гадна нэмэлт багана ( багтсан багана) индекс рүүгээ оруулах: индексийн навчнууд нь зөвхөн индексжүүлсэн баганын утгыг төдийгүй эдгээр индексжүүлээгүй нэмэлт баганын утгыг хадгалах болно. Энэ арга нь индекс дээр тавигдсан зарим хязгаарлалтыг тойрч гарах боломжийг танд олгоно. Жишээлбэл, та индексжүүлэгдэхгүй баганыг оруулах эсвэл индексийн уртын хязгаарыг (ихэнх тохиолдолд 900 байт) давж болно.
Индексүүдийн төрлүүд
Индексийг бөөгнөрсөн эсвэл бөөгнөрөлгүй байхаас гадна нийлмэл индекс, өвөрмөц индекс эсвэл хамрах индекс болгон тохируулж болно.
Нийлмэл индекс
Ийм индекс нь нэгээс олон багана агуулж болно. Та индекст 16 хүртэлх багана оруулах боломжтой боловч нийт урт нь 900 байтаар хязгаарлагддаг. Кластерт болон кластергүй индексүүд хоёулаа нийлмэл байж болно.
Өвөрмөц индекс
Энэ индекс нь индексжүүлсэн баганын утга тус бүрийг өвөрмөц гэдгийг баталгаажуулдаг. Хэрэв индекс нь нийлмэл бол өвөрмөц байдал нь индексийн бүх баганад хамаарах боловч тус тусад нь багана бүрт хамаарахгүй. Жишээлбэл, хэрэв та баганууд дээр өвөрмөц индекс үүсгэвэл НЭРТэгээд Овог, дараа нь бүтэн нэр нь өвөрмөц байх ёстой, гэхдээ овог нэр эсвэл овог нэр нь давхардсан байж болно.
Баганын хязгаарлалтыг тодорхойлох үед өвөрмөц индекс автоматаар үүсдэг: үндсэн түлхүүр эсвэл өвөрмөц утгын хязгаарлалт:
- Үндсэн түлхүүр
Нэг буюу хэд хэдэн баганад үндсэн түлхүүрийн хязгаарлалтыг тодорхойлох үед SQL серверХэрэв кластерийн индекс өмнө нь үүсгэгдээгүй бол автоматаар өвөрмөц кластер индекс үүсгэдэг (энэ тохиолдолд үндсэн түлхүүр дээр кластерт бус өвөрмөц индекс үүсгэгддэг) - Үнэт зүйлийн өвөрмөц байдал
Хэрэв та үнэт зүйлсийн өвөрмөц байдлын хязгаарлалтыг тодорхойлох үед SQL серверавтоматаар кластергүй өвөрмөц индексийг үүсгэдэг. Хүснэгт дээр кластерын индекс хараахан үүсгээгүй бол өвөрмөц кластер индекс үүсгэхийг зааж өгч болно.
Хамрах индекс
Ийм индекс нь тодорхой асуулгад хүснэгтийн бүртгэлд нэмэлт нэвтрэх эрхгүйгээр индексийн навчнаас шаардлагатай бүх өгөгдлийг нэн даруй авах боломжийг олгодог.
Индексийг зохион бүтээх
Индексүүд нь ашигтай байхын хэрээр тэдгээрийг сайтар төлөвлөх ёстой. Индексүүд нь дискний их зай эзэлдэг тул шаардлагатай хэмжээнээс илүү олон индекс үүсгэхийг хүсэхгүй байна. Нэмж дурдахад, өгөгдлийн мөр өөрөө шинэчлэгдэх үед индексүүд автоматаар шинэчлэгддэг бөгөөд энэ нь нэмэлт нөөцийн ачаалал, гүйцэтгэлийн доройтолд хүргэж болзошгүй юм. Индексийг боловсруулахдаа мэдээллийн сан болон түүний эсрэг асуулгатай холбоотой хэд хэдэн зүйлийг анхаарч үзэх хэрэгтэй.
Өгөгдлийн сан
Өмнө дурьдсанчлан, индексүүд нь системийн гүйцэтгэлийг сайжруулж чадна, учир нь... Тэд хайлтын системд өгөгдлийг хурдан олох боломжийг олгодог. Гэсэн хэдий ч та өгөгдөл оруулах, шинэчлэх, устгахыг хэр олон удаа хийхээ анхаарч үзэх хэрэгтэй. Өгөгдлийг өөрчлөх үед өгөгдөл дээрх харгалзах үйлдлүүдийг тусгахын тулд индексүүдийг өөрчлөх шаардлагатай бөгөөд энэ нь системийн гүйцэтгэлийг эрс бууруулдаг. Индексжүүлэх стратегиа төлөвлөхдөө дараах удирдамжийг анхаарч үзээрэй.
- Байнга шинэчлэгддэг хүснэгтүүдийн хувьд аль болох цөөн тооны индекс ашиглана уу.
- Хэрэв хүснэгтэд их хэмжээний өгөгдөл агуулагдаж байгаа боловч өөрчлөлт нь бага байвал асуулгын гүйцэтгэлийг сайжруулахын тулд шаардлагатай тооны индексийг ашиглана уу. Гэсэн хэдий ч жижиг хүснэгтэд индекс ашиглахаасаа өмнө сайтар бодож үзээрэй, учир нь ... Индекс хайлтыг ашиглах нь бүх мөрийг сканнердахаас илүү урт хугацаа шаардагдах магадлалтай.
- Кластерийн индексүүдийн хувьд талбаруудыг аль болох богино байлгахыг хичээгээрэй. Хамгийн сайн арга бол NULL-ийг зөвшөөрдөггүй өвөрмөц утгатай баганууд дээр кластер индекс ашиглах явдал юм. Ийм учраас үндсэн түлхүүрийг ихэвчлэн кластер индекс болгон ашигладаг.
- Багана дахь утгуудын өвөрмөц байдал нь индексийн гүйцэтгэлд нөлөөлдөг. Ерөнхийдөө, баганад илүү олон хуулбар байх тусам индекс муу ажилладаг. Нөгөөтэйгүүр, илүү өвөрмөц утгууд байх тусам индексийн гүйцэтгэл сайжирна. Боломжтой бол өвөрмөц индекс ашиглана уу.
- Нийлмэл индексийн хувьд индекс дэх баганын дарааллыг анхаарч үзээрэй. Илэрхийлэлд хэрэглэгддэг баганууд ХААНА(Жишээлбэл, WHERE нэр = 'Чарли') индексийн эхнийх байх ёстой. Дараагийн багануудыг утгуудын өвөрмөц байдалд үндэслэн жагсаах ёстой (хамгийн олон тооны өвөрмөц утгатай баганууд нэгдүгээрт ордог).
- Хэрэв та тодорхой шаардлагыг хангасан бол тооцоолсон баганууд дээр индексийг зааж өгч болно. Жишээлбэл, баганын утгыг олж авахад хэрэглэгддэг илэрхийллүүд нь тодорхойлогч байх ёстой (өгөгдсөн оролтын параметрүүдийн хувьд үргэлж ижил үр дүнг буцаана).
Өгөгдлийн сангийн асуулга
Индексийг зохион бүтээхдээ анхаарах өөр нэг зүйл бол өгөгдлийн сангийн эсрэг ямар асуулга ажиллуулж байгаа явдал юм. Өмнө дурьдсанчлан, өгөгдөл хэр олон удаа өөрчлөгдөж байгааг анхаарч үзэх хэрэгтэй. Үүнээс гадна дараахь зарчмуудыг баримтална.
- Хэд хэдэн ганц асуулгад хийхээс илүүтэйгээр нэг асуулгад аль болох олон мөр оруулах эсвэл өөрчлөхийг хичээгээрэй.
- Таны асуулгад хайлтын нэр томъёо болгон ашигладаг баганууд дээр кластер бус индекс үүсгэ. ХААНАболон холболтууд НЭГДЭХ.
- Яг утгыг тааруулахын тулд мөр хайх асуулгад ашигладаг индексжүүлэх багануудыг авч үзье.
Хүснэгт яагаад хоёр кластер индекстэй байж болохгүй гэж?
Богино хариулт авмаар байна уу? Кластерт индекс нь хүснэгт юм. Хүснэгт дээр бөөгнөрсөн индекс үүсгэх үед хадгалах систем нь хүснэгтийн бүх мөрийг индексийн тодорхойлолтын дагуу өсөх эсвэл буурах дарааллаар эрэмбэлдэг. Кластерт индекс нь бусад индексүүд шиг тусдаа байгууллага биш бөгөөд хүснэгт дэх өгөгдлийг эрэмбэлэх, өгөгдлийн эгнээнд хурдан нэвтрэх боломжийг олгодог механизм юм.
Танд борлуулалтын гүйлгээний түүхийг агуулсан хүснэгт байна гэж төсөөлье. Борлуулалтын хүснэгтэд захиалгын ID, захиалга дахь бүтээгдэхүүний байршил, бүтээгдэхүүний дугаар, бүтээгдэхүүний тоо хэмжээ, захиалгын дугаар, огноо гэх мэт мэдээллийг багтаасан болно. Та баганууд дээр кластер индекс үүсгэдэг Захиалгын IDТэгээд LineID, доор үзүүлсэн шиг өсөх дарааллаар эрэмбэлсэн T-SQLкод:
Энэ скриптийг ажиллуулах үед хүснэгтийн бүх мөрүүдийг эхлээд OrderID баганаар, дараа нь LineID-ээр ангилах боловч өгөгдөл нь өөрөө нэг логик блок болох хүснэгтэд үлдэх болно. Энэ шалтгааны улмаас та хоёр кластер индекс үүсгэх боломжгүй. Зөвхөн нэг өгөгдөлтэй нэг хүснэгт байж болох бөгөөд энэ хүснэгтийг зөвхөн нэг удаа тодорхой дарааллаар эрэмбэлж болно.
Хэрэв бөөгнөрсөн хүснэгт нь олон ашиг тусыг өгдөг бол яагаад овоолгыг ашиглах ёстой вэ?
Чиний зөв. Кластерт хүснэгтүүд нь маш сайн бөгөөд таны асуулгын ихэнх нь кластер индекстэй хүснэгтүүд дээр илүү сайн ажиллах болно. Гэхдээ зарим тохиолдолд та ширээг байгалийн унаган төрхөөр нь үлдээхийг хүсч болно, i.e. овоолгын хэлбэрт оруулах ба асуулгаа ажиллуулахын тулд зөвхөн бөөгнөрөлгүй индекс үүсгэнэ.
Таны санаж байгаагаар овоолго нь өгөгдлийг санамсаргүй дарааллаар хадгалдаг. Ихэвчлэн хадгалах дэд систем нь өгөгдлийг оруулсан дарааллаар нь хүснэгтэд нэмдэг боловч хадгалах дэд систем нь илүү үр ашигтай хадгалахын тулд мөрүүдийг шилжүүлэх дуртай байдаг. Үүний үр дүнд та өгөгдөл ямар дарааллаар хадгалагдахыг урьдчилан таамаглах боломжгүй болно.
Хэрэв асуулгын систем нь бөөгнөрөлгүй индексийн ашиг тусгүйгээр өгөгдлийг олох шаардлагатай бол шаардлагатай мөрүүдийг олохын тулд хүснэгтийг бүрэн сканнердах болно. Маш жижиг ширээн дээр энэ нь ихэвчлэн асуудал биш боловч овоо томрох тусам гүйцэтгэл хурдан буурдаг. Мэдээжийн хэрэг, кластергүй индекс нь шаардлагатай өгөгдөл хадгалагдаж буй файл, хуудас, мөрийг заагч ашиглан тусалж чадна - энэ нь ихэвчлэн хүснэгтийг сканнердахаас хамаагүй дээр юм. Гэсэн хэдий ч асуулгын гүйцэтгэлийг авч үзэхдээ кластерийн индексийн ашиг тусыг харьцуулах нь хэцүү байдаг.
Гэсэн хэдий ч нуруулдан нь тодорхой нөхцөл байдалд гүйцэтгэлийг сайжруулахад тусалдаг. Олон оруулгатай боловч цөөн шинэчлэлт эсвэл устгасан хүснэгтийг авч үзье. Жишээлбэл, лог хадгалах хүснэгтийг архивлах хүртэл утгыг оруулахад ашигладаг. Мөрүүдийг овоолгын төгсгөлд нэмдэг тул бөөгнөрсөн индекстэй адил пейжинг болон өгөгдлийг хуваахыг та нуруулдан дээр харахгүй. Хуудсуудыг хэт их хуваах нь гүйцэтгэлд мэдэгдэхүйц нөлөө үзүүлэхээс гадна сайнаар нөлөөлдөггүй. Ерөнхийдөө, овоолго нь танд өгөгдлийг харьцангуй өвдөлтгүй оруулах боломжийг олгодог бөгөөд та кластерийн индекстэй адил хадгалах, засвар үйлчилгээ хийх нэмэлт зардлыг төлөх шаардлагагүй болно.
Гэхдээ өгөгдлийг шинэчлэх, устгахгүй байх нь цорын ганц шалтгаан гэж үзэж болохгүй. Мэдээллийг түүвэрлэх арга нь бас чухал хүчин зүйл юм. Жишээлбэл, хэрэв та өгөгдлийн хүрээг байнга асуудаг эсвэл таны асуусан өгөгдлийг эрэмбэлэх, бүлэглэх шаардлагатай бол овоолгыг ашиглах ёсгүй.
Энэ бүхэн нь та маш жижиг хүснэгтүүдтэй ажиллаж байгаа үед л овоолгыг ашиглах хэрэгтэй гэсэн үг юмуу эсвэл хүснэгттэй харьцах бүх үйлдэл нь өгөгдөл оруулахаар хязгаарлагддаг бөгөөд таны асуулга маш энгийн (мөн та кластер бус индекс ашиглаж байгаа) юм. ямар ч байсан). Үгүй бол өргөн хэрэглэгддэг багана шиг энгийн өсөх товчлуурын талбар дээр тодорхойлсон шиг сайн зохион бүтээсэн кластерын индексийг ашиглана уу. ТАНИЛЦУУЛГА.
Би анхдагч индекс дүүргэх хүчин зүйлийг хэрхэн өөрчлөх вэ?
Үндсэн индекс дүүргэх хүчин зүйлийг өөрчлөх нь нэг зүйл юм. Анхдагч харьцаа хэрхэн ажилладагийг ойлгох нь өөр асуудал юм. Гэхдээ эхлээд хэдэн алхам ухрах хэрэгтэй. Индекс дүүргэх хүчин зүйл нь шинэ хуудсыг дүүргэж эхлэхээс өмнө доод түвшинд (навчны түвшин) индексийг хадгалах хуудасны зайны хэмжээг тодорхойлдог. Жишээлбэл, коэффициентийг 90 гэж тохируулсан бол индекс өсөхөд энэ нь хуудасны 90% -ийг эзэлдэг бөгөөд дараа нь дараагийн хуудас руу шилжинэ.
Анхдагчаар индекс дүүргэх хүчин зүйлийн утга нь байна SQL сервер 0 бөгөөд энэ нь 100-тай ижил байна. Үүний үр дүнд, та өөрийн кодонд системийн стандарт утгаас өөр утгыг тусгайлан зааж өгөхгүй эсвэл анхдагч үйлдлийг өөрчлөхгүй бол бүх шинэ индексүүд энэ тохиргоог автоматаар өвлөнө. Та ашиглаж болно SQL Server Management Studioөгөгдмөл утгыг тохируулах эсвэл системд хадгалагдсан процедурыг ажиллуулах sp_configure. Жишээлбэл, дараах багц T-SQLкомандууд нь коэффициентийн утгыг 90 болгож тохируулдаг (та эхлээд дэвшилтэт тохиргооны горимд шилжих ёстой):
EXEC sp_configure "дэвшилтэт сонголтуудыг харуулах ", 1; ДАХИН ТОХИРУУЛАХ; EXEC sp_configure GO"дүүргэх хүчин зүйл", 90; GO ДАХИН ТОХИРУУЛАХ; ЯВ
Индекс дүүргэх хүчин зүйлийн утгыг өөрчилсний дараа та үйлчилгээг дахин эхлүүлэх хэрэгтэй SQL сервер. Та одоо заасан хоёр дахь аргументгүйгээр sp_configure-г ажиллуулснаар тогтоосон утгыг шалгаж болно:
EXEC sp_configure "дүүргэх хүчин зүйл" GO
Энэ тушаал нь 90 утгыг буцаана. Үүний үр дүнд шинээр үүсгэсэн бүх индексүүд энэ утгыг ашиглах болно. Та индекс үүсгэн дүүргэх хүчин зүйлийн утгыг асууснаар үүнийг шалгаж болно:
AdventureWorks2012-г ашиглах; -- таны мэдээллийн сан GO CREATE CLUSTERED INDEX ix_people_lastname ON Person.Person(LastName); GO SELECT fill_factor FROM sys .indexes WHERE object_id = object_id("Person.Person" ) AND name ="ix_people_lastname" ;Энэ жишээн дээр бид хүснэгтэд кластер бус индекс үүсгэсэн Хүнмэдээллийн санд AdventureWorks2012. Индекс үүсгэсний дараа бид sys.indexes системийн хүснэгтүүдээс дүүргэх хүчин зүйлийн утгыг авч болно. Асуулга 90-ыг буцаана.
Гэсэн хэдий ч бид индексийг устгаад дахин үүсгэсэн гэж төсөөлөөд үз дээ, гэхдээ одоо бид тодорхой дүүргэлтийн хүчин зүйлийн утгыг зааж өгсөн болно:
Энэ удаад бид зааврыг нэмж орууллаа ХАМТболон сонголт дүүргэгчМанай индекс үүсгэх үйл ажиллагаанд зориулж ИНДЕКС ҮЗҮҮЛЭХгэсэн утгыг зааж өгсөн 80. Оператор СОНГОХодоо харгалзах утгыг буцаана.
Одоогийн байдлаар бүх зүйл маш энгийн байсан. Та энэ утгыг мэдэж байгаа гэж үзвэл өгөгдмөл коэффициент утгыг ашигладаг индекс үүсгэх үед энэ бүх үйл явцад үнэхээр шатаж болно. Жишээ нь, хэн нэгэн серверийн тохиргоотой эргэлзэж, зөрүүдлэн индекс дүүргэх хүчин зүйлийг 20 болгож тохируулсан байна. Үүний зэрэгцээ, та үндсэн утгыг 0 гэж үзэн индексийг үргэлжлүүлэн үүсгэнэ. Харамсалтай нь танд дүүргэлтийг олох арга алга. индекс үүсгэхгүй бол хүчин зүйлээ оруулаад дараа нь бидний жишээн дээрх шиг утгыг шалгана уу. Үгүй бол асуулгын гүйцэтгэл маш их буурч, ямар нэг зүйлийг сэжиглэж эхлэх мөчийг хүлээх хэрэгтэй болно.
Таны мэдэж байх ёстой өөр нэг асуудал бол индексийг сэргээх явдал юм. Индекс үүсгэхтэй адил та индексийг дахин бүтээхдээ индекс дүүргэх хүчин зүйлийн утгыг зааж өгч болно. Гэсэн хэдий ч, индекс үүсгэх командаас ялгаатай нь rebuild нь серверийн анхдагч тохиргоог ашигладаггүй. Бүр илүү, хэрэв та индекс дүүргэх хүчин зүйлийн утгыг тусгайлан заагаагүй бол дараа нь SQL сервербүтцийн өөрчлөлт хийхээс өмнө энэ индекс байсан коэффициентийн утгыг ашиглана. Жишээлбэл, дараах үйл ажиллагаа ӨӨРЧЛӨЛТИЙН ИНДЕКСБидний саяхан үүсгэсэн индексийг дахин бүтээдэг:
Бид дүүргэх хүчин зүйлийн утгыг шалгахдаа бид 80 гэсэн утгыг авах болно, учир нь бид хамгийн сүүлд индекс үүсгэх үед үүнийг зааж өгсөн болно. Өгөгдмөл утгыг үл тоомсорлодог.
Таны харж байгаагаар индекс дүүргэх хүчин зүйлийн утгыг өөрчлөх нь тийм ч хэцүү биш юм. Одоогийн үнэ цэнийг мэдэх, хэзээ хэрэглэхийг ойлгох нь илүү хэцүү байдаг. Хэрэв та индексийг үүсгэх, дахин бүтээхдээ коэффициентийг тусгайлан зааж өгвөл тодорхой үр дүнг үргэлж мэддэг. Хэрэв та өөр хэн нэгэн серверийн тохиргоог дахин эвдэж, бүх индексийг инээдтэй бага индекс дүүргэх хүчин зүйлээр дахин бүтээхгүй байх талаар санаа зовох хэрэггүй л бол.
Давхардсан тоонуудыг агуулсан багана дээр кластер индекс үүсгэх боломжтой юу?
Тийм, үгүй. Тийм ээ, та давхардсан утгыг агуулсан түлхүүр багана дээр кластер индекс үүсгэж болно. Үгүй, түлхүүр баганын утга нь өвөрмөц бус төлөвт үлдэж болохгүй. Би тайлбарлая. Хэрэв та багана дээр өвөрмөц бус кластерийн индекс үүсгэвэл хадгалалтын систем нь давтагдсан утгад өвөрмөц байдлыг баталгаажуулах, улмаар кластерласан хүснэгтийн мөр бүрийг таних боломжтой болгохын тулд давтагдсан утга дээр нэг тодорхойлогч нэмдэг.
Жишээлбэл, та хэрэглэгчийн өгөгдлийг агуулсан баганад кластер индекс үүсгэхээр шийдэж болно Овоговог нэрээ хадгалах. Багана нь Франклин, Хэнкок, Вашингтон, Смит гэсэн утгуудыг агуулна. Дараа нь та Адамс, Хэнкок, Смит, Смит гэсэн утгуудыг дахин оруулна уу. Гэхдээ түлхүүр баганын утга нь өвөрмөц байх ёстой тул хадгалах систем нь хуулбарын утгыг өөрчлөх бөгөөд ингэснээр Адамс, Франклин, Ханкок, Ханкок1234, Вашингтон, Смит, Смит4567, Смит5678 зэрэг харагдах болно.
Өнгөц харахад энэ арга нь зүгээр юм шиг боловч бүхэл тоо нь түлхүүрийн хэмжээг ихэсгэдэг бөгөөд энэ нь олон тооны давхардсан тохиолдолд асуудал үүсгэдэг бөгөөд эдгээр утгууд нь кластергүй индекс эсвэл гадаад индексийн үндэс болно. гол лавлагаа. Эдгээр шалтгааны улмаас та аль болох давтагдашгүй кластерийн индексүүдийг бий болгохыг хичээх хэрэгтэй. Хэрэв энэ боломжгүй бол ядаж маш өндөр өвөрмөц утгатай багануудыг ашиглахыг хичээ.
Хэрэв кластерийн индекс үүсгээгүй бол хүснэгтийг хэрхэн хадгалах вэ?
SQL сервернь хоёр төрлийн хүснэгтийг дэмждэг: бөөгнөрсөн индекстэй кластер хүснэгтүүд болон нуруулдан хүснэгтүүд эсвэл зүгээр л овоолгууд. Кластерт хүснэгтээс ялгаатай нь овоолгын өгөгдөл ямар ч байдлаар эрэмблэгдээгүй. Үндсэндээ энэ бол өгөгдлийн овоо (овоолгын) юм. Хэрэв та ийм хүснэгтэд мөр нэмбэл хадгалах систем үүнийг зүгээр л хуудасны төгсгөлд хавсаргах болно. Хуудсыг мэдээллээр дүүргэх үед энэ нь шинэ хуудсанд нэмэгдэх болно. Ихэнх тохиолдолд та эрэмбэлэх чадвар, асуулгын хурдыг ашиглахын тулд хүснэгтэн дээр кластер индекс үүсгэхийг хүсэх болно (эрхэмлэгдээгүй хаягийн дэвтэрээс утасны дугаарыг хайж үзээрэй). Гэсэн хэдий ч, хэрэв та бөөгнөрсөн индекс үүсгэхгүй гэж сонгосон бол бөөгнөрөлгүй индекс үүсгэх боломжтой хэвээр байна. Энэ тохиолдолд индексийн мөр бүр овоолгын эгнээний заагчтай байна. Индекс нь файлын ID, хуудасны дугаар, өгөгдлийн мөрийн дугаарыг агуулдаг.
Утгын өвөрмөц байдлын хязгаарлалт ба хүснэгтийн индекс бүхий үндсэн түлхүүрийн хооронд ямар хамааралтай вэ?
Анхдагч түлхүүр ба өвөрмөц хязгаарлалт нь баганын утгууд өвөрмөц байхыг баталгаажуулдаг. Та хүснэгтэд зөвхөн нэг үндсэн түлхүүр үүсгэх боломжтой бөгөөд энэ нь утгыг агуулж болохгүй NULL. Та хүснэгтийн утгын өвөрмөц байдалд хэд хэдэн хязгаарлалт үүсгэж болох бөгөөд тэдгээр нь тус бүрдээ нэг оруулгатай байж болно. NULL.
Таныг анхдагч түлхүүр үүсгэх үед, хэрэв кластерт индекс үүсгээгүй бол хадгалалтын систем нь өвөрмөц кластер индекс үүсгэдэг. Гэсэн хэдий ч, та анхдагч үйлдлийг хүчингүй болгож, кластергүй индекс үүсгэгдэх болно. Хэрэв таныг анхдагч түлхүүрийг үүсгэх үед кластерт индекс байгаа бол өвөрмөц кластергүй индекс үүснэ.
Та өвөрмөц хязгаарлалт үүсгэх үед хадгалах систем нь өвөрмөц, бөөгнөрөлгүй индекс үүсгэдэг. Гэсэн хэдий ч, хэрэв та өмнө нь үүсгээгүй бол өвөрмөц кластерийн индекс үүсгэхийг зааж өгч болно.
Ерөнхийдөө өвөрмөц утгын хязгаарлалт ба өвөрмөц индекс нь ижил зүйл юм.
Яагаад SQL Server дээр кластерт болон кластерт бус индексүүдийг B-tree гэж нэрлэдэг вэ?
SQL Server дээрх кластер эсвэл бөөгнөрөлгүй үндсэн индексүүд нь индексийн зангилаа гэж нэрлэгддэг хуудасны багцад тархдаг. Эдгээр хуудсууд нь тэнцвэртэй мод гэж нэрлэгддэг модны бүтэц бүхий тодорхой шатлалаар зохион байгуулагддаг. Дээд түвшинд үндэс зангилаа, доод талд нь навчны зангилаа, дээд ба доод түвшний хоорондох завсрын зангилаанууд зурагт үзүүлэв.
Үндэс зангилаа нь индексээр дамжуулан өгөгдлийг олж авахыг оролдох асуултуудын гол нэвтрэх цэгийг өгдөг. Энэ зангилаанаас эхлэн асуулгын систем нь шаталсан бүтцээс өгөгдөл агуулсан тохирох навчны зангилаа руу шилжих хөдөлгөөнийг эхлүүлдэг.
Жишээлбэл, 82 гэсэн түлхүүр утгыг агуулсан мөрүүдийг сонгох хүсэлт ирсэн гэж төсөөлөөд үз дээ. Асуулгын дэд систем нь тохиромжтой завсрын зангилаа гэсэн үндсэн зангилаанаас ажиллаж эхэлдэг ба манай тохиолдолд 1-100. 1-100-р завсрын зангилаанаас 51-100-р зангилаа, тэндээс эцсийн зангилаа 76-100 руу шилжинэ. Хэрэв энэ нь бөөгнөрсөн индекс бол зангилааны хуудас нь 82-той тэнцүү түлхүүртэй холбоотой мөрийн өгөгдлийг агуулна. Хэрэв энэ нь бөөгнөрөлгүй индекс бол индексийн хуудас нь кластертай хүснэгтийн заагч эсвэл тодорхой мөрийг агуулна. овоо.
Хэрэв та эдгээр бүх индексийн зангилааг туулах шаардлагатай бол индекс хэрхэн асуулгын гүйцэтгэлийг сайжруулах вэ?
Нэгдүгээрт, индексүүд гүйцэтгэлийг үргэлж сайжруулдаггүй. Хэт олон буруу үүсгэсэн индексүүд нь системийг намаг болгож, асуулгын гүйцэтгэлийг бууруулдаг. Индексийг анхааралтай хэрэглэвэл гүйцэтгэлийн мэдэгдэхүйц өсөлтийг авчирна гэж хэлэх нь илүү зөв юм.
Гүйцэтгэлийг тааруулахад зориулагдсан асар том номыг бодоорой SQL сервер(цаасан хувилбар, цахим хувилбар биш). Та Нөөцийн захирагчийг тохируулах талаар мэдээлэл авахыг хүсч байна гэж төсөөлөөд үз дээ. Та бүхэл бүтэн номыг хуруугаараа хуудас хуудсаараа чирж, эсвэл агуулгын хүснэгтийг нээж, хайж буй мэдээлэлтэй яг хуудасны дугаарыг олж мэдэх боломжтой (номыг зөв индексжүүлсэн, агуулга нь зөв индекстэй байх тохиолдолд). Хэдийгээр та анхдагч бүтцээс (ном) хэрэгтэй мэдээллээ авахын тулд эхлээд огт өөр бүтэц (индекс) руу хандах хэрэгтэй ч гэсэн энэ нь танд ихээхэн цаг хугацаа хэмнэх болно.
Номын индекс, индекс шиг SQL серверХүснэгтэд агуулагдах бүх өгөгдлийг бүрэн сканнердахын оронд шаардлагатай өгөгдлүүд дээрээ нарийн асуулга явуулах боломжийг танд олгоно. Жижиг хүснэгтүүдийн хувьд бүрэн скан хийх нь ихэвчлэн асуудал үүсгэдэггүй, харин том хүснэгтүүд нь олон хуудас өгөгдөл эзэлдэг бөгөөд энэ нь асуулгын системд өгөгдлийн зөв байршлыг нэн даруй олж авах индекс байхгүй бол асуулгын гүйцэтгэлд ихээхэн хугацаа шаардагдана. Томоохон хотын урд талын олон түвшний замын уулзвар дээр газрын зураггүйгээр төөрч байна гээд төсөөлөөд үз дээ.
Хэрэв индексүүд маш сайн бол яагаад багана бүр дээр нэгийг үүсгэж болохгүй гэж?
Ямар ч сайн үйлс шийтгэлгүй үлдэх ёсгүй. Наад зах нь индексүүд ийм байдаг. Мэдээжийн хэрэг, та оператор татах асуулгыг ажиллуулж байх үед индексүүд маш сайн ажилладаг СОНГОХ, гэхдээ операторууд руу ойр ойрхон залгаж эхэлдэг INSERT, ШИНЭЧЛЭХТэгээд УСТГАХ, тиймээс ландшафт маш хурдан өөрчлөгддөг.
Оператороос өгөгдлийн хүсэлтийг эхлүүлэх үед СОНГОХ, асуулгын систем нь индексийг олж, модны бүтцээрээ шилжиж, хайж буй өгөгдлийг олж илрүүлдэг. Илүү энгийн зүйл юу байж болох вэ? Гэхдээ та өөрчлөлтийн мэдэгдлийг эхлүүлбэл бүх зүйл өөрчлөгдөнө ШИНЭЧЛЭХ. Тийм ээ, мэдэгдлийн эхний хэсэгт хайлтын систем нь өөрчилсөн мөрийг олохын тулд индексийг дахин ашиглах боломжтой - энэ бол сайн мэдээ юм. Хэрэв үндсэн баганын өөрчлөлтөд нөлөөлөхгүй эгнээнд өгөгдөлд энгийн өөрчлөлт гарсан бол өөрчлөлтийн үйл явц нь бүрэн өвдөлтгүй байх болно. Харин өөрчлөлтийн үр дүнд өгөгдөл агуулсан хуудсууд хуваагдвал, эсвэл гол баганын утгыг өөр индексийн зангилаа руу шилжүүлэхэд хүргэвэл яах вэ - энэ нь индексийг бүх холбогдох индексүүд болон үйл ажиллагаанд нөлөөлөхөөр өөрчлөн зохион байгуулах шаардлагатай болно. , үр дүнд нь бүтээмж өргөн хэмжээгээр буурдаг.
Үүнтэй төстэй үйл явц нь операторыг дуудах үед тохиолддог УСТГАХ. Индекс нь устгаж буй өгөгдлийн байршлыг тогтооход тусалж болох боловч өгөгдлийг өөрөө устгаснаар хуудсыг өөрчлөхөд хүргэж болзошгүй. Операторын тухайд INSERT, бүх индексийн гол дайсан: та их хэмжээний өгөгдөл нэмж эхэлдэг бөгөөд энэ нь индексийн өөрчлөлт, тэдгээрийг өөрчлөн зохион байгуулахад хүргэдэг бөгөөд хүн бүр хохирдог.
Тиймээс ямар төрлийн индекс, хэд нь үүсгэх талаар бодохдоо өгөгдлийн сандаа асуулгын төрлийг анхаарч үзээрэй. Илүү их гэдэг нь илүү сайн гэсэн үг биш. Хүснэгтэд шинэ индекс нэмэхээсээ өмнө зөвхөн үндсэн асуулгын зардал төдийгүй бусад үйлдлүүдэд домино нөлөө үзүүлэхэд хүргэж болох дискний зарцуулсан зай, функциональ байдал, индексийг хадгалах зардал зэргийг анхаарч үзээрэй. Таны индекс дизайны стратеги нь таны хэрэгжилтийн хамгийн чухал талуудын нэг бөгөөд индексийн хэмжээ, өвөрмөц утгуудын тоо, индексийн дэмжих асуулгын төрөл зэрэг олон зүйлийг багтаасан байх ёстой.
Үндсэн түлхүүр бүхий багана дээр кластер индекс үүсгэх шаардлагатай юу?
Та шаардлагатай нөхцөлийг хангасан аль ч багана дээр кластер индекс үүсгэж болно. Кластерт индекс болон үндсэн түлхүүрийн хязгаарлалт нь бие биедээ зориулж хийгдсэн бөгөөд тэнгэрт таарч байгаа нь үнэн тул та анхдагч түлхүүр үүсгэх үед кластерийн индекс автоматаар үүсгэгдээгүй бол автоматаар үүсгэгдэх болно гэдгийг ойлгоорой. өмнө бий болсон. Гэсэн хэдий ч, та кластерийн индекс нь бусад газарт илүү сайн ажиллах болно гэж шийдэж магадгүй бөгөөд ихэнхдээ таны шийдвэр үндэслэлтэй байх болно.
Кластерт индексийн гол зорилго нь индексийг тодорхойлохдоо заасан гол багана дээр үндэслэн хүснэгтийн бүх мөрүүдийг эрэмбэлэх явдал юм. Энэ нь хурдан хайлт хийх, хүснэгтийн өгөгдөлд хялбар хандах боломжийг олгоно.
Хүснэгтийн үндсэн түлхүүр нь нэмэлт өгөгдөл нэмэхгүйгээр хүснэгтийн мөр бүрийг өвөрмөц байдлаар тодорхойлдог тул сайн сонголт байж болно. Зарим тохиолдолд хамгийн сайн сонголт бол өвөрмөц төдийгүй жижиг хэмжээтэй, утгууд нь дараалан нэмэгдэж, энэ утга дээр суурилсан кластергүй индексийг илүү үр дүнтэй болгодог орлуулагч үндсэн түлхүүр байх болно. Хүснэгтүүдийг нэгтгэх нь үндсэн түлхүүр болон түүнтэй холбоотой кластерын индексийг ашигладаггүй өөр аргаар нэгдэхээс хурдан байдаг тул асуулга оновчтой болгогч нь кластер индекс болон үндсэн түлхүүрийн хослолд дуртай. Миний хэлсэнчлэн энэ бол тэнгэрт хийсэн шүдэнз юм.
Эцэст нь хэлэхэд, кластерийн индексийг бий болгохдоо хэд хэдэн зүйлийг анхаарч үзэх хэрэгтэй: үүн дээр тулгуурлан кластергүй индексүүд хэр их байх, гол индексийн баганын утга хэр олон удаа өөрчлөгдөх, хэр их байх зэргийг анхаарч үзэх хэрэгтэй. Кластерт индексийн баганууд дахь утгууд өөрчлөгдөх эсвэл индекс нь хүлээгдэж буй гүйцэтгэлгүй бол хүснэгтийн бусад бүх индекст нөлөөлж болно. Кластерт индекс нь тодорхой дарааллаар өсдөг, гэхдээ санамсаргүй байдлаар өөрчлөгддөггүй хамгийн тогтвортой баганад үндэслэсэн байх ёстой. Индекс нь хүснэгтийн хамгийн их ханддаг өгөгдлийн эсрэг асуулгад дэмжлэг үзүүлэх ёстой тул асуулга нь индексийн үндсэн зангилаанууд болох өгөгдлийг эрэмбэлж, хандах боломжтой байдгийг бүрэн ашигладаг. Хэрэв үндсэн түлхүүр нь энэ хувилбарт тохирсон бол үүнийг ашиглана уу. Хэрэв үгүй бол өөр багц багана сонгоно уу.
Хэрэв та харагдацыг индексжүүлбэл энэ нь харагдах хэвээр байх уу?
Харагдах байдал нь нэг буюу хэд хэдэн хүснэгтээс өгөгдөл үүсгэдэг виртуал хүснэгт юм. Үндсэндээ энэ нь тухайн харагдацыг асуух үед үндсэн хүснэгтүүдээс өгөгдлийг гаргаж авдаг нэртэй асуулга юм. Хүснэгт дээр хэрхэн индекс үүсгэдэгтэй адил энэ харагдац дээр кластерт болон кластергүй индексүүдийг үүсгэснээр асуулгын гүйцэтгэлийг сайжруулж болох боловч гол анхааруулга нь эхлээд кластерт индекс үүсгэж, дараа нь кластергүй индекс үүсгэж болно.
Индексжүүлсэн харагдац (материалжуулсан харагдац) үүсгэгдсэн тохиолдолд харагдацын тодорхойлолт нь өөрөө тусдаа объект хэвээр үлдэнэ. Эцсийн эцэст энэ бол зүгээр л хатуу кодлогдсон оператор юм СОНГОХ, мэдээллийн санд хадгалагдсан. Гэхдээ индекс бол огт өөр түүх юм. Үйлчилгээ үзүүлэгч дээр бөөгнөрсөн эсвэл кластергүй индекс үүсгэх үед өгөгдөл нь ердийн индекс шиг дискэнд хадгалагдана. Нэмж дурдахад, үндсэн хүснэгтүүдийн өгөгдөл өөрчлөгдөхөд харагдацын индекс автоматаар өөрчлөгддөг (энэ нь та байнга өөрчлөгддөг хүснэгтүүд дээрх харагдацыг индексжүүлэхээс зайлсхийх хэрэгтэй гэсэн үг юм). Ямар ч тохиолдолд харагдац нь харагдац хэвээр үлдэнэ - хүснэгтүүдийг харах, гэхдээ яг одоо ажиллаж байгаа, түүнд тохирох индексүүдтэй.
Харагдах байдал дээр индекс үүсгэхийн өмнө энэ нь хэд хэдэн хязгаарлалтыг хангасан байх ёстой. Жишээлбэл, харагдац нь зөвхөн үндсэн хүснэгтүүдийг лавлах боломжтой боловч бусад харагдацад хамаарахгүй бөгөөд тэдгээр хүснэгтүүд нь нэг мэдээллийн санд байх ёстой. Үнэндээ өөр олон хязгаарлалтууд байдаг тул баримт бичгийг сайтар шалгаж үзээрэй SQL сервербүх бохир нарийн ширийн зүйлсийн хувьд.
Яагаад нийлмэл индексийн оронд хамрах индекс ашиглах ёстой вэ?
Эхлээд энэ хоёрын ялгааг ойлгосон эсэхийг шалгацгаая. Нийлмэл индекс нь нэгээс олон багана агуулсан энгийн индекс юм. Хүснэгтийн мөр бүрийг давтагдашгүй байлгахын тулд олон түлхүүр баганыг ашиглаж болно, эсвэл үндсэн түлхүүр нь өвөрмөц эсэхийг баталгаажуулахын тулд та олон баганатай байж болно, эсвэл олон багана дээр байнга дуудагддаг асуулгын гүйцэтгэлийг оновчтой болгохыг оролдож болно. Гэхдээ ерөнхийдөө индекс нь илүү олон гол багана агуулсан байх тусам индексийн үр ашиг бага байх бөгөөд энэ нь нийлмэл индексийг ухаалаг ашиглах ёстой гэсэн үг юм.
Дээр дурьдсанчлан, шаардлагатай бүх өгөгдөл нь индексийн адил индексийн навч дээр шууд байршвал асуулга ихээхэн ашиг тустай байх болно. Энэ нь кластерийн индексийн хувьд асуудал биш, учир нь бүх өгөгдөл аль хэдийн байна (ийм учраас та кластерийн индекс үүсгэхдээ анхааралтай бодох нь маш чухал юм). Харин навч дээрх бөөгнөрөлгүй индекс нь зөвхөн гол багануудыг агуулна. Бусад бүх өгөгдөлд хандахын тулд асуулга оновчтой болгох нэмэлт алхмуудыг шаарддаг бөгөөд энэ нь таны асуулгыг гүйцэтгэхэд ихээхэн хэмжээний зардал нэмж өгдөг.
Эндээс хамгаалах индекс аврах ажилд ирдэг. Та кластергүй индексийг тодорхойлохдоо үндсэн баганууддаа нэмэлт багануудыг зааж өгч болно. Жишээлбэл, таны програм баганын өгөгдлийг байнга асуудаг гэж бодъё Захиалгын IDТэгээд Захиалгын огноохүснэгтэд Борлуулалт:
Та хоёр баганад бөөгнөрөлгүй нийлмэл индекс үүсгэж болох боловч OrderDate багана нь онцгой хэрэгцээтэй түлхүүр багана болохгүйгээр зөвхөн индексийн засвар үйлчилгээний нэмэлт зардлыг нэмэх болно. Хамгийн сайн шийдэл бол гол багана дээр бүрхсэн индекс үүсгэх явдал юм Захиалгын IDболон нэмэлт оруулсан багана Захиалгын огноо:
dbo ДЭЭР БҮЛГЭЭГҮЙ ИНДЕКС ҮЗҮҮЛЭХ ix_orderid. Борлуулалт(OrderID) ОРУУЛАХ (Захиалгын огноо);Энэ нь асуулга ажиллуулж байх үед өгөгдлийг навчинд хадгалах давуу талыг хадгалахын зэрэгцээ илүүдэл баганыг индексжүүлэх сул талуудаас зайлсхийдэг. Оруулсан багана нь түлхүүрийн хэсэг биш боловч өгөгдөл нь навчны зангилаа, индексийн хуудас дээр хадгалагддаг. Энэ нь нэмэлт зардалгүйгээр асуулгын гүйцэтгэлийг сайжруулж чадна. Нэмж дурдахад, хамрах индекст багтсан баганууд нь индексийн гол баганаас бага хязгаарлалттай байдаг.
Түлхүүр баганад давхардсан тоо чухал уу?
Та индекс үүсгэхдээ гол багана дахь давхардлын тоог багасгахыг хичээх ёстой. Эсвэл илүү нарийвчлалтай: давталтын хурдыг аль болох бага байлгахыг хичээ.
Хэрэв та нийлмэл индекстэй ажиллаж байгаа бол давхардал нь бүх гол баганад бүхэлд нь хамаарна. Нэг баганад олон давхардсан утгыг агуулж болох боловч индексийн бүх баганын дунд хамгийн бага давталт байх ёстой. Жишээлбэл, та баганууд дээр нийлмэл кластергүй индекс үүсгэдэг НэрТэгээд Овог, та John Doe-ийн олон утгатай, олон Doe-ийн утгатай байж болно, гэхдээ та аль болох цөөн Жон Доугийн утгыг, эсвэл зүгээр л нэг Жон Доугийн утгатай байхыг хүсч байна.
Түлхүүр баганын утгуудын өвөрмөц байдлын харьцааг индексийн сонголт гэж нэрлэдэг. Илүү өвөрмөц утгууд байх тусам сонгох чадвар өндөр байдаг: өвөрмөц индекс нь хамгийн их сонголттой байдаг. Асуулгын систем нь сонгох чадвар өндөртэй баганад үнэхээр дуртай, ялангуяа эдгээр баганууд нь таны байнга гүйцэтгэдэг асуулгын WHERE заалтад багтсан бол. Индекс илүү сонгомол байх тусам асуулгын систем нь үүссэн өгөгдлийн багцын хэмжээг багасгаж чадна. Сул тал нь мэдээжийн хэрэг харьцангуй цөөн тооны өвөрмөц утгатай баганууд индексжүүлэхэд сайн нэр дэвшигч байх нь ховор байдаг.
Түлхүүр баганын өгөгдлийн зөвхөн тодорхой хэсэг дээр кластергүй индекс үүсгэх боломжтой юу?
Анхдагч байдлаар, кластергүй индекс нь хүснэгтийн мөр бүрт нэг мөр агуулна. Мэдээжийн хэрэг, ийм индексийг хүснэгт гэж үзвэл кластерийн индексийн талаар ижил зүйлийг хэлж болно. Гэхдээ бөөгнөрөлгүй индексийн тухайд хувилбараас эхлээд нэгийг харьцах харьцаа нь чухал ойлголт юм. SQL Server 2008, та үүнд орсон мөрүүдийг хязгаарлах шүүж болох индекс үүсгэх сонголттой. Шүүгдсэн индекс нь асуулгын гүйцэтгэлийг сайжруулж чадна, учир нь... Энэ нь жижиг хэмжээтэй бөгөөд бүх хүснэгтээс илүү шүүсэн, илүү үнэн зөв статистик мэдээллийг агуулдаг - энэ нь гүйцэтгэлийн төлөвлөгөөг сайжруулахад хүргэдэг. Шүүгдсэн индекс нь хадгалах зай бага, засвар үйлчилгээний зардал бага шаарддаг. Шүүлтүүртэй тохирох өгөгдөл өөрчлөгдөх үед л индекс шинэчлэгддэг.
Үүнээс гадна шүүж болох индекс үүсгэхэд хялбар байдаг. Оператор дээр ИНДЕКС ҮЗҮҮЛЭХта зүгээр л зааж өгөх хэрэгтэй ХААНАшүүлтүүрийн нөхцөл. Жишээлбэл, та кодонд үзүүлсэн шиг индексээс NULL агуулсан бүх мөрийг шүүж болно:
Бид үнэндээ чухал асуултуудад чухал биш аливаа өгөгдлийг шүүж чадна. Гэхдээ болгоомжтой байгаарай, учир нь ... SQL серверхарагдац дээр шүүж болох индекс үүсгэх боломжгүй гэх мэт шүүж болох индексүүдэд хэд хэдэн хязгаарлалт тавьдаг тул баримт бичгийг анхааралтай уншина уу.
Та индексжүүлсэн харагдац үүсгэснээр ижил төстэй үр дүнд хүрч магадгүй юм. Гэсэн хэдий ч шүүсэн индекс нь засвар үйлчилгээний зардлыг бууруулах, гүйцэтгэлийн төлөвлөгөөний чанарыг сайжруулах зэрэг хэд хэдэн давуу талтай. Шүүгдсэн индексүүдийг онлайнаар дахин бүтээх боломжтой. Үүнийг индексжүүлсэн харагдацаар туршиж үзээрэй.
6. Индекс ба гүйцэтгэлийг оновчтой болгох
Өгөгдлийн сан дахь индексүүд: зорилго, гүйцэтгэлд үзүүлэх нөлөө, индекс үүсгэх зарчим
6.1 Индексүүд юунд зориулагдсан вэ?
Индексүүд нь өгөгдлийн сангийн тусгай бүтэц бөгөөд хүснэгтийн тодорхой талбар эсвэл талбарын багцаар хайх, эрэмбэлэх ажлыг хурдасгах боломжийг олгодог бөгөөд мэдээллийн өвөрмөц байдлыг хангахад ашиглагддаг. Индексийг харьцуулах хамгийн хялбар арга бол ном дээрх индексүүд юм. Хэрэв индекс байхгүй бол бид зөв газраа олохын тулд номыг бүхэлд нь үзэх хэрэгтэй болно, гэхдээ индексийн тусламжтайгаар ижил үйлдлийг илүү хурдан хийх боломжтой.
Дүрмээр бол, илүү олон индекс байх тусам мэдээллийн сангийн асуулгын гүйцэтгэл сайжирна. Гэсэн хэдий ч индексийн тоо хэт ихэсвэл өгөгдлийг өөрчлөх үйлдлүүдийн гүйцэтгэл (оруулах/өөрчлөх/устгах) буурч, мэдээллийн сангийн хэмжээ ихсэх тул индекс нэмэхэд болгоомжтой хандах хэрэгтэй.
Индекс үүсгэхтэй холбоотой зарим ерөнхий зарчим:
· Хайлт, эрэмбэлэх үйлдлүүдэд ихэвчлэн ашиглагддаг нэгдлүүдэд ашиглагддаг баганад индекс үүсгэх ёстой. Анхдагч түлхүүрийн хязгаарлалттай баганын хувьд индексүүд үргэлж автоматаар үүсгэгддэг гэдгийг анхаарна уу. Ихэнхдээ тэдгээрийг гадаад түлхүүр бүхий баганад зориулж бүтээдэг (Access-д - автоматаар);
· өвөрмөц байдлын хязгаарлалттай баганын хувьд индексийг автоматаар үүсгэх ёстой;
· Хамгийн бага давтагдах утгууд, өгөгдөл жигд тархсан талбаруудад индекс үүсгэх нь хамгийн сайн арга юм. Oracle нь олон тооны давхардсан утгатай баганад зориулсан тусгай бит индексүүдтэй бөгөөд Access нь энэ төрлийн индексийг өгдөггүй;
· Хэрэв хайлтыг тодорхой багана (нэг зэрэг) дээр байнга хийдэг бол энэ тохиолдолд нийлмэл индекс (зөвхөн SQL Server дээр) үүсгэх нь утга учиртай байж болох юм - баганын бүлэгт нэг индекс;
· Хүснэгтэнд өөрчлөлт оруулах үед энэ хүснэгтэд давхардсан индексүүд автоматаар өөрчлөгдөнө. Үүний үр дүнд индекс нь маш их хуваагдмал байж болох бөгөөд энэ нь гүйцэтгэлд нөлөөлдөг. Та индексийн хуваагдлын зэргийг үе үе шалгаж, тэдгээрийг дефрагментация хийх хэрэгтэй. Их хэмжээний өгөгдөл ачаалах үед заримдаа эхлээд бүх индексийг устгаж, үйл ажиллагаа дууссаны дараа дахин үүсгэх нь утга учиртай байдаг;
· Индексийг зөвхөн хүснэгтэд төдийгүй үзвэрийн хувьд (зөвхөн SQL Server дээр) үүсгэж болно. Давуу талууд - хүсэлт гаргах үед биш, харин хүснэгтэд шинэ утгууд гарч ирэх үед талбаруудыг тооцоолох чадвар.
Энэ нийтлэлд индексүүд болон тэдгээрийн асуулгын гүйцэтгэлийн хугацааг оновчтой болгоход гүйцэтгэх үүргийг авч үзэх болно. Өгүүллийн эхний хэсэгт индексийн янз бүрийн хэлбэр, тэдгээрийг хэрхэн хадгалах талаар авч үзнэ. Дараа нь бид CREATE INDEX, ALTER INDEX, DROP INDEX гэсэн индексүүдтэй ажиллахад хэрэглэгддэг гурван үндсэн Transact-SQL хэллэгийг шалгана. Дараа нь системийн гүйцэтгэлд үзүүлэх нөлөөллийн индексүүдийн хуваагдлыг авч үздэг. Дараа нь индекс үүсгэх зарим ерөнхий удирдамжийг өгч, хэд хэдэн тусгай төрлийн индексийг тайлбарласан болно.
Ерөнхий мэдээлэл
Өгөгдлийн сангийн системүүд нь харилцааны өгөгдөлд хурдан нэвтрэх боломжийг олгохын тулд ихэвчлэн индекс ашигладаг. Индекс нь нэг буюу хэд хэдэн мөр өгөгдөлд хурдан хандах боломжийг олгодог бие даасан өгөгдлийн бүтэц юм. Тиймээс индексүүдийг зөв тохируулах нь асуулгын гүйцэтгэлийг сайжруулах гол тал юм.
Өгөгдлийн сангийн индекс нь номын индекстэй (цагаан толгойн үсгийн индекс) олон талаараа төстэй байдаг. Бид номноос сэдвийг хурдан олох шаардлагатай бол эхлээд энэ сэдвийг номын аль хуудсан дээр авч үзэж байгааг индексээс харж, дараа нь хүссэн хуудсыг нэн даруй нээнэ. Үүний нэгэн адил, хүснэгтийн тодорхой мөрийг хайх үед Өгөгдлийн сангийн систем нь түүний физик байршлыг олохын тулд индекс рүү ханддаг.
Гэхдээ номын индекс ба мэдээллийн сангийн индексийн хооронд хоёр чухал ялгаа бий:
Номыг уншигчид тодорхой тохиолдол бүрт индексийг ашиглах эсэхээ өөрөө шийдэх боломжтой. Өгөгдлийн сангийн хэрэглэгч ийм боломж байхгүй бөгөөд энэ шийдвэрийг системийн бүрэлдэхүүн хэсэг гэж нэрлэдэг асуулга оновчтой болгох. (Хэрэглэгч индексийн зөвлөмжийг ашиглан индексийн хэрэглээг удирдах боломжтой боловч эдгээр зөвлөмжийг зөвхөн цөөн тооны онцгой тохиолдлуудад ашиглахыг зөвлөж байна.)
Тодорхой ажлын дэвтрийн индексийг ажлын дэвтрийн хамт үүсгэсэн бөгөөд дараа нь түүнийг өөрчлөхгүй. Энэ нь тухайн сэдвийн индекс нь үргэлж ижил хуудасны дугаарыг заана гэсэн үг юм. Үүний эсрэгээр, өгөгдлийн сангийн индекс нь холбогдох өгөгдөл өөрчлөгдөх бүрт өөрчлөгдөж болно.
Хэрэв хүснэгтэд тохирох индекс байхгүй бол систем нь мөрүүдийг сэргээхийн тулд хүснэгтийг сканнердах аргыг ашигладаг. Илэрхийлэл хүснэгтийг сканнердахЭнэ нь систем нь хүснэгтийн мөр бүрийг (эхнийхээс сүүлчийнх хүртэл) дараалан авч, шалгаж, WHERE заалтын хайлтын нөхцөл хангагдсан тохиолдолд мөрийг үр дүнгийн багцад байрлуулна гэсэн үг юм. Тиймээс бүх мөрүүдийг санах ой дахь физик байршлын дагуу татаж авдаг. Энэ арга нь доор тайлбарласны дагуу индекс ашиглан хандалт хийхээс үр ашиг багатай.
Индексүүд нь өгөгдлийн сангийн нэмэлт бүтцэд хадгалагддаг индекс хуудас. Индексжүүлсэн мөр бүрийн хувьд байдаг индекс оруулах, энэ нь индексийн хуудсан дээр хадгалагдсан. Индекс элемент бүр нь индексийн түлхүүр болон индексээс бүрдэнэ. Ийм учраас индексийн элемент нь зааж буй хүснэгтийн мөрөөс хамаагүй богино байна. Ийм учраас индексийн хуудас бүрийн индексийн элементийн тоо нь өгөгдлийн хуудасны мөрийн тооноос хамаагүй их байна.
Индексүүдийн энэ шинж чанар нь маш чухал бөгөөд учир нь индексийн хуудсуудыг дамжихад шаардагдах оролт/гаралтын үйлдлүүдийн тоо нь харгалзах өгөгдлийн хуудсуудыг дамжихад шаардагдах оролт/гаралтын үйлдлүүдийн тооноос хамаагүй бага байдаг. Өөрөөр хэлбэл, хүснэгтийг сканнердах нь хүснэгтийн индексийг сканнердахаас илүү олон оролт гаралтын үйлдлүүдийг шаарддаг.
Өгөгдлийн сангийн хөдөлгүүрийн индексүүд нь B+ модны өгөгдлийн бүтцийг ашиглан үүсгэгддэг. B+ мод нь модны бүтэцтэй бөгөөд хамгийн доод цэгүүд нь модны дээд хэсгээс (үндэс зангилаа) ижил түвшний зайд байрладаг. Индексжүүлсэн баганаас өгөгдөл нэмэх эсвэл хассан ч гэсэн энэ шинж чанар хадгалагдана.
Доорх зурагт Ажилтны хүснэгтийн B+ модны бүтэц, Id баганын 25348 утгатай тухайн хүснэгтийн мөр рүү шууд хандах хандалтыг харуулав. (Бид Ажилтны хүснэгтийг Id баганаар индексжүүлсэн гэж үздэг.) Мөн та энэ зургаас B+ мод нь үндсэн зангилаа, модны зангилаа, тэг ба түүнээс дээш завсрын зангилаанаас бүрддэгийг харж болно:
Та энэ модноос 25348 утгыг дараах байдлаар хайж болно. Модны үндсээс эхлэн хүссэн утгаас их буюу тэнцүү байх хамгийн бага түлхүүр утгыг хайдаг. Тиймээс үндсэн зангилаанд энэ утга нь 29346 байх тул энэ утгатай холбоотой завсрын зангилаа руу шилжинэ. Энэ зангилаанд 28559 утга нь заасан шаардлагыг хангаж байгаа бөгөөд үүний үр дүнд энэ утгатай холбоотой модны зангилаа руу шилжинэ. Энэ зангилаа нь хүссэн утгыг агуулж байна 25348. Шаардлагатай индексийг тодорхойлсны дараа бид зохих заагчийг ашиглан өгөгдлийн хүснэгтээс түүний мөрийг гаргаж авах боломжтой. (Индексээс бага буюу тэнцүү утгыг хайх нь өөр эквивалент арга юм.)
Индексжүүлсэн хайлт нь тодорхой давуу талтай тул олон тооны мөр бүхий хүснэгтүүдийг хайхад илүүд үздэг арга юм. Индексжүүлсэн хайлтыг ашигласнаар бид цөөн хэдэн оролт гаралтын үйлдлийг ашиглан маш богино хугацаанд хүснэгтийн дурын мөрийг олох боломжтой. Мөн дараалсан хайлт (жишээ нь хүснэгтийг эхний эгнээнээс сүүлчийн эгнээ хүртэл сканнердах) илүү их цаг хугацаа шаардагдана, шаардлагатай мөр хол байх тусам илүү их цаг хугацаа шаардагдана.
Дараах хэсгүүдэд бид одоо байгаа хоёр төрлийн индексийг, кластерт болон бөөгнөрөлгүй үзэж, индексийг хэрхэн үүсгэх талаар сурах болно.
Кластерт индексүүд
Кластер индексХүснэгт дэх өгөгдлийн физик дарааллыг тодорхойлдог. Өгөгдлийн сангийн хөдөлгүүр нь хүснэгтэд зөвхөн нэг кластер индекс үүсгэх боломжийг олгодог, учир нь Хүснэгтийн мөрүүдийг физикийн хувьд нэгээс олон аргаар эрэмбэлж болохгүй. Кластерт индекс ашиглан хайлтыг B+ модны үндэс зангилаанаас давхар холбоос бүхий жагсаалтад холбогдсон модны зангилаанууд руу чиглүүлнэ. хуудасны сүлжээ.
Кластерт индексийн чухал шинж чанар нь модны зангилаанууд нь мэдээллийн хуудас агуулсан байдаг. (Бүлэглэсэн индексийн зангилааны бусад бүх түвшний индексүүд нь индексийн хуудсуудыг агуулна.) Тодорхойлогдсон кластер индекстэй (тодорхой эсвэл далд хэлбэрээр) хүснэгтийг кластер хүснэгт гэнэ. Кластерт индексийн B+ модны бүтцийг доорх зурагт үзүүлэв.

Анхдагч түлхүүрийн хязгаарлалтаар тодорхойлогдсон үндсэн түлхүүр бүхий хүснэгт бүр дээр кластер индексийг анхдагчаар үүсгэнэ. Үүнээс гадна, кластерийн индекс бүр нь анхдагчаар өвөрмөц байдаг, i.e. Тодорхойлогдсон кластер индекстэй баганад өгөгдлийн утга бүр зөвхөн нэг удаа гарч ирж болно. Давхардсан утгыг агуулсан багана дээр кластер индекс үүсгэсэн бол өгөгдлийн сангийн систем давхардсан утгуудыг агуулсан мөрүүдэд дөрвөн байт танигч нэмж хоёрдмол утгагүй байдлыг баталгаажуулдаг.
Кластерт индексүүд нь асуулга нь хэд хэдэн утгыг хайх үед өгөгдөлд маш хурдан хандах боломжийг олгодог.
Кластерт бус индексүүд
Кластерт бус индексийн бүтэц нь кластерийн индекстэй яг адилхан боловч хоёр чухал ялгаа байдаг:
кластергүй индекс нь хүснэгтийн мөрүүдийн физик дарааллыг өөрчлөхгүй;
Бүлэггүй индексийн зангилааны хуудаснууд нь индексийн түлхүүрүүд болон хавчуургуудаас бүрдэнэ.
Хэрэв та хүснэгтэд нэг буюу хэд хэдэн кластергүй индексийг тодорхойлсон бол хүснэгтийн мөрүүдийн физик дараалал өөрчлөгдөхгүй. Өгөгдлийн сангийн систем нь бөөгнөрөлгүй индекс бүрийн хувьд индексийн хуудсанд хадгалагдах нэмэлт индексийн бүтцийг бий болгодог. Кластерт бус индексийн B+ модны бүтцийг доорх зурагт үзүүлэв.

Бүлэггүй индекс дэх хавчуурга нь индексийн түлхүүрт харгалзах мөр хаана байрлаж байгааг заана. Хүснэгт нь бөөгнөрсөн хүснэгт эсвэл бөөгнөрөл байх эсэхээс хамааран индексийн гол хавчуургын бүрэлдэхүүн хэсэг нь хоёр төрлийн байж болно. (SQL Server-ийн нэр томъёонд овоолго гэдэг нь кластер индексгүй хүснэгт юм.) Хэрэв бөөгнөрсөн индекс байгаа бол кластергүй индекс таб нь хүснэгтийн кластерын индексийн B+ модыг харуулдаг. Хэрэв хүснэгтэд кластерийн индекс байхгүй бол хавчуурга нь ижил байна мөр танигч (RID - мөр танигч), гурван хэсгээс бүрдэнэ: хүснэгт хадгалагдаж буй файлын хаяг, мөр хадгалагдаж буй физик блок (хуудас) хаяг, хуудасны мөрийн офсет.
Өмнө дурьдсанчлан, өгөгдөл хайлтыг хүснэгтийн төрлөөс хамааран кластергүй индексээр хоёр өөр аргаар хийж болно.
овоо - бөөгнөрөлгүй индексийн хайлтын бүтцийг тойрон гарах ба дараа нь мөрийг тодорхойлогч ашиглан мөрийг олж авна;
clustered table - бөөгнөрөлгүй индексийн бүтцийг хайх, дараа нь харгалзах кластерлагдсан индексийг давах.
Аль ч тохиолдолд оролт/гаралтын үйлдлүүдийн хэмжээ нэлээд том тул та бөөгнөрөлгүй индексийг болгоомжтой хийх хэрэгтэй бөгөөд хэрэв та үүнийг ашигласнаар гүйцэтгэлийг мэдэгдэхүйц сайжруулна гэдэгт итгэлтэй байвал л ашиглах хэрэгтэй.
Transact-SQL хэл ба индексүүд
Одоо бид индексүүдийн физик бүтэцтэй танилцсан тул энэ хэсэгт бид индексийг хэрхэн үүсгэх, өөрчлөх, устгах, мөн индексийн хуваагдлын мэдээллийг хэрхэн олж авах, индексийн мэдээллийг засварлах талаар авч үзэх болно. Энэ бүхэн нь системийн гүйцэтгэлийг сайжруулахын тулд индексийг ашиглах дараагийн хэлэлцүүлэгт бэлтгэх болно.
Индекс үүсгэх
Хүснэгт дээрх индексийг мэдэгдэл ашиглан үүсгэнэ ИНДЕКС ҮЗҮҮЛЭХ. Энэ заавар нь дараах синтакстай байна.
INDEX INDEX INDEX_нэрийг ҮЗҮҮЛЭХ ON хүснэгтийн нэр (багана1 ,...) [ ОРУУЛАХ (баганын_нэр [ ,... ]) ] [[, ] PAD_INDEX = (ON | OFF)] [[, ] DROP_EXISTING = (ON | OFF)] [[ , ] SORT_IN_TEMPDB = (ON | OFF)] [[, ] IGNORE_DUP_KEY = (ON | OFF)] [[, ] ALLOW_ROW_LOCKS = (ON | OFF)] [[, ] ALLOW_PAGE_LOCKS = (ON | OFF)] [[, ] STATISTICS_NORECOMPUTE = (ON | OFF)] [[, ] ОНЛАЙН = (ON | OFF)]] Синтакс конвенцууд
index_name параметр нь үүсгэх индексийн нэрийг зааж өгдөг. table_name параметрээр тодорхойлогдсон нэг хүснэгтийн нэг буюу хэд хэдэн багана дээр индекс үүсгэж болно. Индекс үүсгэсэн баганыг багана1 параметрээр тодорхойлно. Энэ параметрийн тоон дагавар нь хүснэгтийн олон багана дээр индекс үүсгэж болохыг харуулж байна. Өгөгдлийн сангийн систем нь үзэл бодол дээр индекс үүсгэхийг дэмждэг.
Та ямар ч хүснэгтийн баганыг индексжүүлж болно. Энэ нь VARBINARY(max), BIGINT, SQL_VARIANT өгөгдлийн төрлийн утгуудыг агуулсан баганыг мөн индексжүүлж болно гэсэн үг юм.
Индекс нь энгийн эсвэл нийлмэл байж болно. Энгийн индексийг нэг багана дээр үүсгэдэг бол нийлмэл индексийг олон багана дээр үүсгэдэг. Нийлмэл индекс нь түүний хэмжээ, баганын тоотой холбоотой тодорхой хязгаарлалттай байдаг. Индекс хамгийн ихдээ 900 байт, дээд тал нь 16 баганатай байж болно.
Өвөрмөц параметриндексжүүлсэн баганад зөвхөн нэг утгатай (өөрөөр хэлбэл давтагдахгүй) утгыг агуулж болохыг зааж өгнө. Нэг утгатай нийлмэл индексийн хувьд цорын ганц нь мөр бүрийн бүх баганын утгуудын хослол байх ёстой. Хэрэв UNIQUE түлхүүр үг тодорхойлогдоогүй бол индексжүүлсэн багана (ууд) дахь давхардсан утгыг зөвшөөрнө.
CLUSTERED параметркластерийн индексийг зааж өгдөг, мөн CLUSTERED бус параметр(анхдагч) нь индекс нь хүснэгтийн мөрүүдийн дарааллыг өөрчлөхгүй гэдгийг заадаг. Өгөгдлийн сангийн систем нь хүснэгтэд дээд тал нь 249 кластергүй индекс оруулахыг зөвшөөрдөг.
Өгөгдлийн сангийн хөдөлгүүр нь баганын утгуудын буурах дарааллаар индексүүдийг дэмжихийн тулд сайжруулсан. Баганын нэрний дараах ASC параметр нь индексийг баганын утгуудын өсөх дарааллаар үүсгэхийг, DESC параметр нь индексийн баганын утгуудын буурах дарааллыг зааж өгнө. Энэ нь индексийг ашиглахад илүү уян хатан байдлыг хангадаг. Буурах дарааллаар та утгууд нь эсрэг чиглэлд эрэмблэгдсэн баганууд дээр нийлмэл индекс үүсгэх хэрэгтэй.
ОРУУЛАХ параметрКластерт бус индексийн зангилааны хуудсанд нэмсэн түлхүүр бус баганыг тодорхойлох боломжийг танд олгоно. INCLUDE жагсаалтын баганын нэр давтагдах ёсгүй бөгөөд баганыг түлхүүр болон түлхүүргүй багана болгон ашиглах боломжгүй.
INCLUDE параметрийн ашиг тусыг үнэхээр ойлгохын тулд энэ нь юу болохыг ойлгох хэрэгтэй хамрах индекс. Хэрэв бүх асуулгын баганыг индекст оруулсан бол та гүйцэтгэлийн мэдэгдэхүйц сайжруулалтыг авах боломжтой Асуулга оновчтой болгох нь хүснэгтийн өгөгдөлд хандахгүйгээр индексийн хуудсууд дээрх бүх баганын утгыг олох боломжтой. Энэ чадварыг хамрах индекс буюу хамрах асуулга гэж нэрлэдэг. Тиймээс, кластер биш индексийн зангилааны хуудсанд нэмэлт түлхүүр бус багануудыг оруулснаар илүү олон хамрах хүрээний асуулга авч, тэдгээрийн гүйцэтгэлийг мэдэгдэхүйц сайжруулах боломжтой болно.
FILLFACTOR параметриндекс үүсгэх үед индексийн хуудас бүрийн хэдэн хувийг бөглөхийг зааж өгнө. FILLFACTOR параметрийн утгыг 1-ээс 100 хүртэлх мужид тохируулж болно. n=100 утгатай бол индексийн хуудас бүрийг 100% хүртэл дүүргэнэ, өөрөөр хэлбэл. Одоо байгаа зангилааны хуудас болон зангилаа бус хуудас нь шинэ мөр оруулах зайгүй байх болно. Тиймээс энэ утгыг зөвхөн статик хүснэгтэд ашиглахыг зөвлөж байна. (Өгөгдмөл утга n=0 нь индексийн зангилааны хуудсууд дүүрсэн бөгөөд завсрын хуудас бүр нэг оруулгад зориулсан сул зайтай гэсэн үг юм.)
Хэрэв FILLFACTOR параметрийг 1-ээс 99-ийн хооронд утгаар тохируулсан бол үүсгэсэн индексийн бүтцийн зангилааны хуудаснууд нь хоосон зайг агуулна. n-ийн утга их байх тусам индексийн зангилааны хуудсанд сул зай бага байна. Жишээлбэл, n=60 байвал индексийн зангилааны хуудас бүр ирээдүйн индексийн мөр оруулахад 40% сул зайтай байх болно. (Индексийн мөрүүдийг INSERT эсвэл UPDATE хэллэг ашиглан оруулна.) Иймд өгөгдөл нь нэлээд ойр ойрхон өөрчлөгддөг хүснэгтийн хувьд n=60 утга нь үндэслэлтэй байх болно. 1-ээс 99-ийн хооронд FILLFACTOR утгуудтай бол завсрын индексийн хуудаснууд тус бүр нэг оруулгад зориулсан чөлөөт зайг агуулна.
Индекс үүсгэсний дараа ашиглах явцад FILLFACTOR утгыг дэмждэггүй. Өөрөөр хэлбэл, энэ нь сул зайны хувь хэмжээг тогтоохдоо зөвхөн боломжтой өгөгдөлд нөөцөлсөн зайны хэмжээг заана. FILLFACTOR параметрийг анхны утга руу нь сэргээхийн тулд ALTER INDEX хэллэгийг ашиглана уу.
PAD_INDEX параметр FILLFACTOR параметртэй нягт холбоотой. FILLFACTOR параметр нь үндсэндээ индексийн зангилааны нийт хуудасны хэмжээний хувиар сул зайны хэмжээг тодорхойлдог. Мөн PAD_INDEX параметр нь FILLFACTOR параметрийн утга нь индекс дэх индексийн хуудас болон өгөгдлийн хуудасны аль алинд нь хамааралтай болохыг зааж өгдөг.
DROP_EXISTING параметрКластерт бус индекстэй хүснэгт дээр кластерын индексийг хуулбарлах үед гүйцэтгэлийг сайжруулах боломжийг танд олгоно. Дэлгэрэнгүй мэдээллийг доорх "Индексийг дахин бүтээх" хэсгээс үзнэ үү.
SORT_IN_TEMPDB параметр tempdb системийн мэдээллийн санд индекс үүсгэх үед ашигладаг завсрын эрэмбэлэх үйлдлүүдийн өгөгдлийг байрлуулахад ашигладаг. Хэрэв tempdb нь өгөгдлөөс өөр диск дээр байрладаг бол энэ нь гүйцэтгэлийг сайжруулж магадгүй юм.
IGNORE_DUP_KEY параметрИндексжүүлсэн баганад давхардсан утгыг оруулах оролдлогыг үл тоомсорлох боломжийг системд олгоно. Энэ сонголтыг зөвхөн INSERT мэдэгдэл нь давхардсан өгөгдлийг индексжүүлсэн баганад оруулах үед удаан үргэлжилсэн гүйлгээг цуцлахаас зайлсхийхийн тулд ашиглах ёстой. Энэ сонголтыг идэвхжүүлсэн үед INSERT мэдэгдэл нь индексийн өвөрмөц байдлыг зөрчсөн мөрүүдийг хүснэгтэд оруулахыг оролдох үед өгөгдлийн сангийн систем бүх мэдэгдлийг эвдэхийн оронд зүгээр л анхааруулга өгдөг. Энэ тохиолдолд Өгөгдлийн сангийн систем нь давхардсан түлхүүр утгууд бүхий мөрүүдийг оруулахгүй, зүгээр л тэдгээрийг үл тоомсорлож, зөв мөрүүдийг нэмнэ. Хэрэв энэ параметрийг тохируулаагүй бол бүх зааврын гүйцэтгэл хэвийн бусаар дуусна.
Хэзээ ALLOW_ROW_LOCKS параметридэвхжүүлсэн (асаалттай гэж тохируулсан), систем эгнээ түгжихийг хэрэгжүүлнэ. Үүнтэй адилаар идэвхжүүлсэн үед ALLOW_PAGE_LOCKS параметр, систем нь зэрэгцээ хандалтын үед хуудасны түгжээг ашигладаг. STATISTICS_NORECOMPUTE параметрзаасан индексийн статистикийн автомат дахин тооцооллын төлөвийг тодорхойлно.
Идэвхжүүлсэн ОНЛАЙН параметрхарилцах горимд индекс үүсгэх, дахин үүсгэх, устгах боломжийг танд олгоно. Энэ сонголт нь индексийг өөрчлөхийн зэрэгцээ үндсэн хүснэгт эсвэл кластерийн индекс болон холбогдох индексүүдийн өгөгдлийг нэгэн зэрэг өөрчлөх боломжийг олгодог. Жишээлбэл, кластерийн индексийг дахин үүсгэж байх үед та түүний өгөгдлийг үргэлжлүүлэн шинэчлэх, тухайн өгөгдөл дээр асуулга ажиллуулах боломжтой.
Параметр ONөгөгдмөл файлын бүлэг (өгөгдмөл утга) эсвэл заасан файлын бүлэг (файлын_бүлгийн утга) дээр заасан индексийг үүсгэдэг.
Доорх жишээнд Ажилтны хүснэгтийн Id баганад кластергүй индексийг хэрхэн үүсгэхийг харуулав.
SampleDb-г ашиглах; CREATE INDEX ix_empid ON Employee(Id);
Нэг утгатай нийлмэл индекс үүсгэхийг доорх жишээнд үзүүлэв.
SampleDb-г ашиглах; IX_empid_prnu ON Works_on (EmpId, ProjectNumber) FILLFACTOR= 80-тай Өвөрмөц индекс үүсгэх;
Энэ жишээнд багана тус бүрийн утгууд нэг оронтой байх ёстой. Индекс үүсгэх үед индексийн зангилааны хуудас бүрийн 80% -ийг дүүргэдэг.
Хэрэв баганад давхардсан утгууд байгаа бол та багана дээр өвөрмөц индекс үүсгэх боломжгүй. Утга бүр (NULL утгыг оруулаад) баганад яг нэг удаа гарч ирвэл л ийм индексийг үүсгэж болно. Нэмж дурдахад, байгаа өвөрмөц индекст багтсан баганад байгаа өгөгдлийн утгыг оруулах, өөрчлөх оролдлого нь давхардсан тохиолдолд системээс татгалзах болно.
Индекс хуваагдлын талаар мэдээлэл авах
Индекс ашиглалтын хугацаанд хуваагдаж, индексийн хуудсанд өгөгдөл хадгалах үйл явцыг үр ашиггүй болгодог. Индекс хуваагдал нь дотоод болон гадаад хуваагдал гэсэн хоёр төрөлтэй. Дотоод хуваагдал нь хуудас бүрт хадгалагдсан өгөгдлийн хэмжээг тодорхойлдог бол хуудаснууд логик дараалалгүй байх үед гадаад хуваагдал үүсдэг.
Дотоод индексийн хуваагдлын талаарх мэдээллийг авахын тулд DMV динамик удирдлагын харагдац гэж нэрлэдэг sys.dm_db_index_физик_стат. Энэхүү DMV нь заасан хуудасны өгөгдөл, индексийн эзлэхүүн, хуваагдлын талаарх мэдээллийг буцаана. Хуудас бүрийн хувьд B+ модны түвшин бүрт нэг мөр буцаана. Энэхүү DMV-ийг ашиглан та өгөгдлийн хуудсууд дахь мөрийн хуваагдлын зэрэгтэй холбоотой мэдээллийг авах боломжтой бөгөөд үүний үндсэн дээр та өгөгдлийг дахин зохион байгуулах эсэхээ шийдэж болно.
sys.dm_db_index_physical_stats харагдацын хэрэглээг доорх жишээнд үзүүлэв. (Багцын жишээг ажиллуулахын өмнө та Works_on хүснэгтэд байгаа бүх индексийг буулгах ёстой. Индексүүдийг хасахын тулд дараа нь харуулах DROP INDEX мэдэгдлийг ашиглана уу.)
SampleDb-г ашиглах; @dbId INT ЗАРЛАХ; @tabId INT ЗАРЛАХ; @indId INT ЗАРЛАХ; SET @dbId = DB_ID("SampleDb"); SET @tabId = OBJECT_ID("Ажилтан"); sys.dm_db_index_physical_stats (@dbId, @tabId, NULL, NULL, NULL);
Жишээнээс харахад sys.dm_db_index_physical_stats харагдац нь таван параметртэй байна. Эхний гурван параметр нь одоогийн мэдээллийн сан, хүснэгт, индексийн ID-г тодорхойлно. Дөрөв дэх параметр нь хуваалтын ID-г, сүүлийн параметр нь статистик мэдээллийг олж авахад ашигладаг сканнердах түвшинг тодорхойлдог. (Тухайн параметрийн өгөгдмөл утгыг NULL утгыг ашиглан тодорхойлж болно.)
Энэ харагдацын хамгийн чухал баганууд нь дундаж_хуваалцах_хувь болон дундаж_хуудасны_зайг_ашигласан_хувийн баганууд юм. Эхнийх нь хуваагдлын дундаж түвшинг хувиар, хоёр дахь нь эзэлсэн зайны хэмжээг хувиар илэрхийлдэг.
Индексийн мэдээллийг засварлах
Өмнөх хэсэгт хэлэлцсэн индексийн хуваагдлын мэдээлэлтэй танилцсаны дараа та энэ болон бусад индексийн мэдээллийг дараах системийн хэрэгслийг ашиглан засварлаж болно.
лавлах харах sys.indexes;
каталогийн харагдах байдал sys.index_columns;
системийн процедур sp_helpindex;
objectproperty өмчийн функцууд;
SQL серверт зориулсан Management Studio удирдлагын орчин;
DMV динамик удирдлагын харагдац sys.dm_db_index_usage_stats;
DMV динамик удирдлагын харагдац sys.dm_db_missing_index_details.
Каталог харах sys.indexesиндекс тус бүрийн мөр, кластерийн индексгүй хүснэгт бүрийн мөрийг агуулна. Энэ каталогийн харагдацын хамгийн чухал багана нь object_id, name, index_id багана юм. object_id баганад тухайн индексийг эзэмшдэг өгөгдлийн сангийн объектын нэрийг, name болон index_id баганад тухайн индексийн нэр болон ID-г тус тус агуулна.
Каталог харах sys.index_columnsиндекс эсвэл овоолгын хэсэг болох багана бүрийн мөрийг агуулна. Энэ мэдээллийг sys.indexes каталогийн харагдацаар олж авсан мэдээлэлтэй хамтад нь заасан индексийн шинж чанарын талаар нэмэлт мэдээлэл авах боломжтой.
Системийн журам sp_helpindexХүснэгтийн индексүүдийн талаарх мэдээлэл болон баганын статистик мэдээллийг буцаана. Энэ процедур нь дараах синтакстай байна:
sp_helpindex [@db_object = ] "нэр"
Энд @db_object хувьсагч нь хүснэгтийн нэрийг илэрхийлнэ.
Индекстэй холбоотойгоор, объект өмчийн функцнь IsIndexed болон IsIndexable гэсэн хоёр шинж чанартай. Эхний шинж чанар нь хүснэгт эсвэл харагдац нь индекстэй эсэх талаар мэдээлэл өгдөг бол хоёр дахь шинж чанар нь хүснэгт эсвэл харагдац индексжүүлж болох эсэхийг заана.
Одоо байгаа индексийн мэдээллийг SQL Server Management Studio ашиглан засварлахын тулд Өгөгдлийн сангийн хавтсаас хүссэн мэдээллийн санг сонгоод Хүснэгтийн зангилаа, уг зангилаа дотроос хүссэн хүснэгт болон түүний Indexes хавтасыг өргөжүүлнэ. Хүснэгтийн Индекс хавтас нь тухайн хүснэгтэд байгаа бүх индексийн жагсаалтыг харуулах болно. Индекс дээр давхар товшвол тухайн индексийн шинж чанаруудтай Index Properties харилцах цонх нээгдэнэ. (Мөн та Management Studio ашиглан шинэ индекс үүсгэх эсвэл байгаа индексийг устгах боломжтой.)
Гүйцэтгэл sys.dm_db_index_usage_statsянз бүрийн төрлийн индексийн үйлдлүүдийн тоо, төрөл тус бүрийг хамгийн сүүлд гүйцэтгэсэн тоог буцаана. Нэг асуулгад заасан индексийг тусад нь хайх, хайх, шинэчлэх үйлдэл бүрийг индексийн хэрэглээ гэж үзэж, тухайн DMV дахь харгалзах тоолуурыг нэгээр нэмэгдүүлнэ. Ингэснээр та индексийг хэр олон удаа ашигладаг талаар ерөнхий мэдээлэл авах боломжтой бөгөөд ингэснээр та аль индексийг илүү их, аль нь бага ашиглаж байгааг тодорхойлох боломжтой болно.
Гүйцэтгэл sys.dm_db_index_details дутуу байнаИндекс байхгүй хүснэгтийн баганын талаарх дэлгэрэнгүй мэдээллийг буцаана. Энэхүү DMV-ийн хамгийн чухал баганууд нь индекс_бариул болон объект_id багана юм. Эхний баганын утга нь тодорхой дутуу индексийг, хоёр дахь баганын утга нь индекс байхгүй байгаа хүснэгтийг тодорхойлно.
Индексүүдийг өөрчлөх
Өгөгдлийн сангийн хөдөлгүүр нь мэдэгдлийг дэмждэг цөөн тооны мэдээллийн сангийн системүүдийн нэг юм ӨӨРЧЛӨЛТИЙН ИНДЕКС. Энэ мэдэгдлийг индексийн засвар үйлчилгээ хийхэд ашиглаж болно. ALTER INDEX мэдэгдлийн синтакс нь CREATE INDEX мэдэгдлийн синтакстай маш төстэй юм. Өөрөөр хэлбэл, энэ мэдэгдэл нь CREATE INDEX мэдэгдэлд өмнө нь тайлбарласан ALLOW_ROW_LOCKS, ALLOW_PAGE_LOCKS, IGNORE_DUP_KEY, STATISTICS_NORECOMPUTE параметрүүдийн утгыг өөрчлөх боломжийг танд олгоно.
Дээрх сонголтуудаас гадна ALTER INDEX мэдэгдэл нь өөр гурван сонголтыг дэмждэг:
ДАХИН БУУДЛАХ параметр, индексийг дахин үүсгэхэд ашигладаг;
Параметрийг ДАХИН ЗОХИОН БАЙГУУЛАХ, индексийн зангилааны хуудсыг дахин зохион байгуулахад ашигладаг;
DIABLE параметр, индексийг идэвхгүй болгоход ашигладаг. Эдгээр гурван сонголтыг дараах дэд хэсгүүдэд авч үзнэ.
Индексийг сэргээж байна
INSERT, UPDATE, DELETE мэдэгдлийг ашиглан өгөгдөлд хийсэн аливаа өөрчлөлт нь өгөгдлийн хуваагдалд хүргэж болзошгүй. Хэрэв энэ өгөгдлийг индексжүүлсэн бол индексийн мэдээллийг янз бүрийн физик хуудсуудаар тарааж, индексийг хуваах боломжтой. Индекс өгөгдлийн хуваагдлын үр дүнд Өгөгдлийн сангийн хөдөлгүүр нэмэлт өгөгдөл унших үйлдлүүдийг гүйцэтгэхээс өөр аргагүй болж болох бөгөөд энэ нь системийн ерөнхий гүйцэтгэлийг бууруулдаг. Энэ тохиолдолд та бүх хуваагдсан индексүүдийг ДАХИН БҮТЭЭХ хэрэгтэй.
Үүнийг хоёр аргаар хийж болно:
ALTER INDEX мэдэгдлийн REBUILD параметрээр дамжуулан;
CREATE INDEX мэдэгдлийн DROP_EXISTING параметрээр дамжуулан.
REBUILD параметрийг индексийг дахин бүтээхэд ашигладаг. Хэрэв та энэ параметрийн индексийн нэрний оронд ALL-г зааж өгвөл хүснэгт дээрх бүх индексүүд дахин үүсгэгдэх болно. (Индексүүдийг динамикаар дахин үүсгэхийг зөвшөөрснөөр та тэдгээрийг буулгаж, дахин үүсгэх шаардлагагүй болно.)
CREATE INDEX мэдэгдлийн DROP_EXISTING сонголт нь мөн кластерт бус индекстэй хүснэгт дээр кластерын индексийг дахин үүсгэх үед гүйцэтгэлийг сайжруулж чадна. Энэ нь одоо байгаа кластертай эсвэл кластергүй индексийг хасч, заасан индексийг дахин үүсгэх ёстойг зааж өгсөн. Өмнө дурьдсанчлан, кластерлагдсан хүснэгт дээрх кластергүй индекс бүр нь модны зангилаанд хүснэгтийн кластерын индексийн харгалзах утгуудыг агуулна. Ийм учраас та кластерт индексийг хүснэгтэд буулгахдаа түүний бүх кластер бус индексийг дахин үүсгэх ёстой. DROP_EXISTING параметрийг ашигласнаар бөөгнөрөлгүй индексүүдийг дахин үүсгэх шаардлагагүй болно.
DROP_EXISTING сонголт нь илүү уян хатан бөгөөд индексийг бүрдүүлдэг баганыг өөрчлөх, бөөгнөрөлгүй индексийг кластер болгон өөрчлөх зэрэг хэд хэдэн сонголтоор хангадаг учраас REBUILD сонголтоос илүү хүчтэй.
Индекс зангилааны хуудсыг дахин зохион байгуулах
ALTER INDEX мэдэгдлийн REORGANIZE параметр нь заасан индекс дэх зангилааны хуудсуудыг өөрчлөн зохион байгуулснаар хуудасны физик дараалал нь логик дараалалд нь зүүнээс баруун тийш таарч байна. Энэ нь тодорхой хэмжээний индексийн хуваагдлыг арилгаж, индексийн гүйцэтгэлийг сайжруулдаг.
Индексийг идэвхгүй болгох
DISABLE сонголт нь заасан индексийг идэвхгүй болгодог. Идэвхгүй болгосон индексийг дахин идэвхжүүлэх хүртэл ашиглах боломжгүй. Холбогдох өгөгдөлд өөрчлөлт оруулахад идэвхгүй болсон индекс өөрчлөгдөхгүй гэдгийг анхаарна уу. Ийм учраас тахир дутуу индексийг дахин ашиглахын тулд үүнийг бүрэн дахин үүсгэх шаардлагатай. Идэвхгүй индексийг идэвхжүүлэхийн тулд ALTER TABLE мэдэгдлийн REBUILD сонголтыг ашиглана уу.
Хүснэгт дээрх кластерийн индексийг идэвхгүй болгох үед хүснэгтийн бүх өгөгдлийн хуудаснууд нь модны зангилаанд хадгалагддаг тул хүснэгтийн өгөгдөлд хандах боломжгүй болно.
Индексүүдийг устгах, нэрийг өөрчлөх
Одоогийн мэдээллийн сан дахь индексүүдийг устгахын тулд ашиглана уу DROP INDEX заавар. Хүснэгт дээр кластерийн индексийг буулгах нь маш их нөөц шаардсан үйлдэл байж болохыг анхаарна уу Бүх кластер биш индексүүдийг дахин үүсгэх шаардлагатай. (Бүх бөөгнөрөлгүй индексүүд нь зангилааны хуудсандаа заагч болгон кластерын индексийн индексийн түлхүүрийг ашигладаг.) Индексийг буулгахдаа DROP INDEX мэдэгдлийг ашиглахыг доорх жишээнд үзүүлэв:
SampleDb-г ашиглах; DROP INDEX ix_empid ON Ажилтан;
DROP INDEX заавар нь нэмэлт зүйлтэй Параметр рүү шилжих, утга нь CREATE INDEX мэдэгдлийн ON параметртэй ижил байна. Өөрөөр хэлбэл, та энэ параметрийг ашиглан кластерийн индексийн зангилааны хуудсанд байгаа өгөгдлийн мөрүүдийг хааш нь шилжүүлэхийг зааж өгч болно. Өгөгдлийг овоолгын хэлбэрээр шинэ байршил руу зөөв. Та шинэ өгөгдөл хадгалах байршилд анхдагч файлын бүлэг эсвэл нэртэй файлын бүлгийг зааж өгч болно.
DROP INDEX мэдэгдлийг PRIMARY KEY болон UNIQUE индекс зэрэг бүрэн бүтэн байдлын хязгаарлалтын үүднээс системээс далд хэлбэрээр үүсгэсэн индексүүдийг хасахад ашиглах боломжгүй. Ийм индексийг арилгахын тулд та холбогдох хязгаарлалтыг арилгах хэрэгтэй.
Индексүүдийн нэрийг sp_rename системийн процедурыг ашиглан өөрчилж болно.
Мэдээллийн сангийн диаграмм эсвэл объект Explorer ашиглан индексүүдийг Management Studio дээр үүсгэж, өөрчилж, устгаж болно. Гэхдээ хамгийн хялбар арга бол шаардлагатай хүснэгтийн Indexes хавтсыг ашиглах явдал юм. Management Studio дээрх индексүүдийг удирдах нь Management Studio дээрх хүснэгтүүдийг удирдахтай адил юм.
Өгөгдлийн сангийн систем нь индексийн тоонд бодит хязгаарлалт тавьдаггүй ч тоог хязгаарлах хэд хэдэн шалтгаан бий. Нэгдүгээрт, индекс бүр нь тодорхой хэмжээний дискний зай эзэлдэг тул өгөгдлийн сангийн индексийн хуудасны нийт тоо нь өгөгдлийн сангийн өгөгдлийн хуудасны тооноос давах магадлалтай. Хоёрдугаарт, өгөгдөл авахын тулд индекс ашиглахын ашиг тусаас ялгаатай нь индексийг хадгалах хэрэгцээ шаардлагаас шалтгаалан өгөгдөл оруулах, устгах нь тийм ашиг тусыг өгдөггүй. Хүснэгтэд илүү олон индекс байх тусам тэдгээрийг дахин зохион байгуулахад илүү их ажил шаардагдана. Дүрмээр бол байнга асуудаг индексүүдийг сонгоод дараа нь тэдгээрийн хэрэглээг үнэлэх нь ухаалаг хэрэг юм.
Индекс үүсгэх, ашиглах зарим удирдамжийг энэ хэсэгт өгсөн болно. Дараах зөвлөмжүүд нь зөвхөн ерөнхий дүрэм юм. Эцсийн эцэст, тэдгээрийн үр нөлөө нь өгөгдлийн санг практикт хэрхэн ашиглах, хамгийн олон удаа гүйцэтгэдэг асуулгын төрлөөс хамаарна. Хэзээ ч ашиглагдахгүй баганыг индексжүүлэх нь ямар ч сайн зүйл хийхгүй.
Индекс ба WHERE заалтын нөхцөл
Хэрэв SELECT мэдэгдлийн WHERE заалт нь нэг багана бүхий хайлтын нөхцөлийг агуулж байвал тухайн багана дээр индекс үүсгэнэ. Энэ нь ялангуяа өндөр сонгомол нөхцөлд ашиглахыг зөвлөж байна. Нөхцөлийн сонгомол чанар гэж бид нөхцөлийг хангасан мөрүүдийн тоог хүснэгтийн нийт мөрийн тоонд харьцуулсан харьцааг хэлнэ. Өндөр сонгомол байдал нь энэ харьцааны бага утгатай тохирч байна. Нөхцөл байдлын сонголт 5% -иас бага байх үед индексжүүлсэн багана ашиглан хайлтын боловсруулалт хамгийн амжилттай болно.
Нөхцөл байдлын сонголтын түвшин тогтмол 80% ба түүнээс дээш байвал баганыг индексжүүлж болохгүй. Энэ тохиолдолд индексийн хуудсуудад нэмэлт оролт/гаралтын үйлдлүүд шаардагдах бөгөөд энэ нь индексийг ашиглан цаг хугацааны хэмнэлтийг багасгах болно. Энэ тохиолдолд хүснэгтийг сканнердах замаар хайлт хийх нь илүү хурдан бөгөөд энэ нь хайлтыг оновчтой болгодог бөгөөд энэ нь индексийг ашиггүй болгодог.
Хэрэв байнга хэрэглэгддэг асуулгын хайлтын нөхцөл нь AND операторуудыг агуулж байвал SELECT мэдэгдлийн WHERE хэсэгт заасан хүснэгтийн бүх баганууд дээр нийлмэл индекс үүсгэх нь хамгийн сайн арга юм. Ийм нийлмэл индексийг үүсгэхийг доорх жишээнд үзүүлэв.
Энэ жишээ нь WHERE заалтын бүх баганууд дээр нийлмэл индекс үүсгэдэг. Энэ асуулгад хоёр нөхцөлийг хамтад нь AND-тай болгосон тул та эдгээр нөхцөлд хоёр багана дээр нийлмэл бөөгнөрөлгүй индекс үүсгэх хэрэгтэй.
Индексүүд болон нэгдэх оператор
Нэгдэх үйл ажиллагааны хувьд нэгдэж буй багана бүр дээр индекс үүсгэхийг зөвлөж байна. Холбогдсон баганууд нь ихэвчлэн нэг хүснэгтийн үндсэн түлхүүр, нөгөө хүснэгтийн харгалзах гадаад түлхүүрийг илэрхийлдэг. Хэрэв та харгалзах нэгдэх баганууд дээр PRIMARY KEY болон FOREIGN KEY бүрэн бүтэн байдлын хязгаарлалтыг зааж өгвөл зөвхөн гадаад түлхүүр багана дээр бөөгнөрөлгүй индекс үүсгэх хэрэгтэй. систем нь үндсэн түлхүүрийн багана дээр кластерийн индексийг далд хэлбэрээр үүсгэх болно.
Доорх жишээнд нэгдэх үйлдэлтэй асуулга болон нэмэлт шүүлтүүртэй бол ашиглах индексүүдийг хэрхэн үүсгэхийг харуулав.
Хамрах индекс
Өмнө дурьдсанчлан, бүх асуулгын баганыг индекст оруулах нь асуулгын гүйцэтгэлийг мэдэгдэхүйц сайжруулж чадна. Хамгаалах гэж нэрлэгддэг ийм индексийг үүсгэхийг доорх жишээнд үзүүлэв.
AdventureWorks2012-г ашиглах; GO DROP INDEX Person.Address.IX_Address_StateProvinceID; GO CREATE INDEX ix_address_zip ON Person.Address(Шуудангийн код) INCLUDE(Хот, Мужийн ID); GO СОНГОХ хот, муж, муж улсын ID-г хүнээс. Хаяг ХААНА Шуудангийн код = 84407;
Энэ жишээ нь эхлээд Хаяг хүснэгтээс IX_Address_StateProvinceID индексийг устгадаг. Дараа нь шуудангийн кодын баганаас гадна хоёр нэмэлт багана агуулсан шинэ индекс үүсгэгдэнэ. Эцэст нь жишээний төгсгөлд байгаа SELECT мэдэгдэл нь индекст хамрагдсан асуулгыг харуулж байна. Энэ асуулгын хувьд систем нь өгөгдлийн хуудсуудаас өгөгдөл хайх шаардлагагүй, учир нь асуулга оновчтой болгогч нь бөөгнөрөлгүй индексийн зангилааны хуудасны бүх баганын утгыг олох боломжтой.
Индекс хуудсууд нь харгалзах өгөгдлийн хуудсуудаас илүү олон оруулгуудыг агуулж байдаг тул хамрах индексүүдийг санал болгож байна. Нэмж хэлэхэд, энэ аргыг ашиглахын тулд шүүж буй баганууд нь индексийн эхний гол баганууд байх ёстой.
Тооцоолсон баганууд дээрх индексүүд
Өгөгдлийн сангийн хөдөлгүүр нь дараах тусгай төрлийн индексүүдийг үүсгэх боломжийг танд олгоно.
индексжүүлсэн үзэл бодол;
шүүж болох индексүүд;
тооцоолсон багана дээрх индексүүд;
хуваасан индексүүд;
баганын тогтвортой байдлын индексүүд;
XML индексүүд;
бүрэн текстийн индексүүд.
Энэ хэсэгт тооцоолсон баганууд болон тэдгээртэй холбоотой индексүүдийг авч үзнэ.
Тооцоолсон баганахүснэгтийн өгөгдлийн тооцооны үр дүнг хадгалдаг хүснэгтийн багана юм. Ийм багана нь виртуал эсвэл байнгын байж болно. Эдгээр хоёр төрлийн баганыг дараах дэд хэсгүүдэд авч үзнэ.
Виртуал тооцоолсон баганууд
Харгалзах кластерийн индексгүй тооцоолсон багана нь логик багана, i.e. Энэ нь хатуу диск дээр физик байдлаар хадгалагдаагүй болно. Тиймээс мөр рүү хандах бүрт үүнийг үнэлдэг. Виртуал тооцоолсон баганын хэрэглээг доорх жишээнд үзүүлэв.
SampleDb-г ашиглах; ХҮСНЭГТ захиалга үүсгэх (OrderId INT NULL, үнэ MONEY NOT NULL, Quantity INT NOT NULL, Quantity INT NOT NULL, Order Date DATETIME NOT NULL, Total AS Price * Тоо хэмжээ, Төөгүүлсэн огноо АС DATE ADD (ӨДӨР, 7, захиалгын огноо));
Энэ жишээн дэх Захиалгын хүснэгт нь нийт болон тээвэрлэсэн огноо гэсэн хоёр виртуал тооцоолсон баганатай. Нийт баганыг үнэ болон тоо хэмжээ гэсэн хоёр багана, тээвэрлэсэн огноо баганыг DATEADD функц болон захиалга өгөх огнооны баганыг ашиглан тооцно.
Тогтмол тооцоолсон багана
Өгөгдлийн сангийн систем нь үндсэн баганууд нь тодорхой өгөгдлийн төрлүүдтэй байдаг тодорхой тооцоолсон баганууд дээр индекс үүсгэх боломжийг олгодог. (Тооцоолсон багана нь ижил хүснэгтийн өгөгдлийн хувьд үргэлж ижил утгыг буцаадаг бол түүнийг тодорхойлогч гэж нэрлэдэг.)
Индексжүүлсэн тооцоолсон баганыг зөвхөн SET мэдэгдлийн дараах параметрүүдийг ON гэж тохируулсан тохиолдолд үүсгэж болно (эдгээр параметрүүд нь баганыг тодорхойлогч эсэхийг баталгаажуулдаг):
QUOTED_IDENTIFIER
CONCAT_NULL_YIELDS_NULL
Үүнээс гадна NUMERIC_ROUNDABORT параметрийг унтраасан байх ёстой.
Хэрэв та тооцоолсон багана дээр кластер индекс үүсгэвэл баганын утгууд нь хүснэгтийн харгалзах мөрөнд байх болно, учир нь кластерт индексийн зангилааны хуудаснууд нь өгөгдлийн мөрүүдийг агуулдаг. Дараах жишээ нь Захиалгын хүснэгтээс тооцоолсон нийт баганад кластер индекс үүсгэдэг:
SampleDb-г ашиглах; IX1 ON Захиалга (Нийт);
CREATE INDEX хэллэгийг гүйцэтгэсний дараа тооцоолсон нийт багана нь хүснэгтэд биет байдлаар харагдах болно. Энэ нь тооцоолсон баганын суурь баганын бүх шинэчлэлтүүд түүнийг шинэчлэхэд хүргэнэ гэсэн үг юм.
Баганыг ашиглан өөр аргаар тогтмол болгож болно PERSISTED параметр. Энэ сонголт нь харгалзах кластерийн индексийг үүсгэхгүйгээр тооцоолсон баганын бодит байдлыг тодорхойлох боломжийг олгодог. Энэ чадвар нь ойролцоогоор өгөгдлийн төрөл (хөвөгч эсвэл бодит) баганууд дээр үүсгэгдсэн физик тооцоолсон багануудыг үүсгэхэд шаардлагатай. (Өмнө дурьдсанчлан индексийг зөвхөн тооцоолсон багана дээр түүний суурь багана нь яг өгөгдлийн төрөлтэй бол үүсгэж болно.)
Эхлэгчдэд зориулсан энэ нийтлэлд би SQL асуулга гүйцэтгэх хурдыг нэмэгдүүлэхийн тулд шаардлагатай индексүүдийг хэрхэн тодорхойлох талаар авч үзэх болно.
Үнэн хэрэгтээ индексүүдтэй холбоотой маш олон нарийн мэдрэмжүүд байдаг бөгөөд энэ нь нэг чиглэлд болон эсрэг чиглэлд гүйцэтгэлд ихээхэн нөлөөлдөг. Та энэ тухай олон нийтлэлийг Интернетээс олж болно. Хаягжуулалт, санах ой хадгалах болон бусад олон зүйлийн ялгааг тайлбарласан их хэмжээний нийтлэлүүд.
Мэдээжийн хэрэг эдгээр нь үнэхээр хэрэгтэй зүйл боловч тэдгээр нь ихэвчлэн нэг жижиг нюансыг алддаг - эдгээр бүх шинж чанарууд нь үнэхээр мэдэгдэхүйц нөлөө үзүүлдэг мэдээллийн хэмжээ юм. Мөн энэ үзүүлэлтийг ихэвчлэн хэдэн зуун мянган бичлэгээр хэмждэг. Энгийнээр хэлбэл, хэрэв таны хүснэгтэд 1-30 мянга орчим бичлэг байгаа бөгөөд бид ачаалагдсан системд зориулсан ямар нэгэн завсрын өгөгдөл хадгалах биш харин вэбсайт (эсвэл ижил төстэй эх сурвалж) тухай ярьж байгаа бол ихэнхдээ энэ нь илүү чухал юм. зүгээр л зөв индексийг бий болгох. Та техникийн хувьд маш сайн мэдлэгтэй байх албагүй гэдгийг энд тэмдэглэх нь чухал юм. Энгийн логик ашиглан олон ашигтай индексийг барьж болно.
Анхаарна уу: Энэ нь асуулга нь өөрөө илүү их эсвэл бага оновчтой хийгдсэн гэж үздэг, жишээлбэл, select дээр нэмэлт талбар байхгүй гэх мэт.
Бүхэл тоо тодорхойлогч талбаруудын индекс.
Хэрэв танд бүхэл тоо тодорхойлогч талбар байгаа бол (энэ нь хүснэгтийн танигч эсвэл өөр хүснэгтийн мөрийг зааж байгаа танигч байх нь хамаагүй) түүнд зориулж тусдаа индекс үүсгэ.
Гол нь энэ. Хэрэв талбар нь өөрөө хүснэгтэд байгаа бичлэгүүдийн тодорхойлогч бол бид үндсэн түлхүүрийн тухай ярьж байна (энэ нь бас индекс юм). Сайтууд ихэвчлэн таних тэмдэгтэй ажилладаг тул ийм индекс нь олон давуу талтай. Хэрэв энэ нь лавлах хүснэгтийн мөр тодорхойлогч бол индекс бас хэрэгтэй. Хэрэв танд шүүсэн өгөгдөл хэрэгтэй бол индексгүй бол эдгээр сангууд тийм ч их ашиггүй байдаг (зөвхөн мэдээллийн сангийн хэмжээ байж магадгүй).
Хэрэв эхний тохиолдолд бүх зүйл маш энгийн бөгөөд ойлгомжтой бол хоёр дахь тохиолдолд (лавлах номтой) би энгийн жишээ өгөх болно.
Нийтлэл (нийтлэл - id, нэр, текст) ба тайлбар (сэтгэгдэл - id, нийтлэл_id, текст) гэсэн хоёр хүснэгт байна гэж бодъё. Эхний хүснэгтэд 200 бичлэг (нийтлэл), хоёр дахь хүснэгтэд 2000 бичлэг (нийтлэл тус бүрд 10 тайлбар) байна. Үүний дагуу хэрэглэгч бүр ямар нэгэн нийтлэлийг нээх үед дараах хүсэлтийг гүйцэтгэнэ.
Хэрэв sql хайлтыг article_id талбарт индексгүйгээр гүйцэтгэсэн бол тайлбар бүхий хүснэгтийг бүхэлд нь (бүх 2000 бичлэг) тухай бүр бүрэн сканнердах болно. Хэрэв article_id талбарт индекс нэмсэн бол өгөгдлийн санд 20-оос илүүгүй бичлэг (нарийвчилж хэлэхэд хамгийн муу тохиолдолд 18 орчим) харах шаардлагатай болно. Энд тооцоо хийх нь энгийн. Хамгийн муу тохиолдолд индексийн хайлт нь ижил индексийн талбарын утгатай бичлэгийн тоо + бичлэгийн тоо хоёртын логарифмын хурдаар явагдана. Энэ тохиолдолд нийтлэл бүр 10 бичлэгтэй (тэдгээрийн утгууд давтагдана) + 200-ийн log2 (зөвхөн 200 өгүүлэл байгаа тул = 2000 / 10) = 10 + 8 (дугуйрсан) = 18.
Мэдээжийн хэрэг, ийм индекс бүр нь эзэлдэг дискний зайнаас гадна оруулах, шинэчлэх, устгахад зориулсан мэдээллийн сангийн нэмэлт зардлыг оруулдаг. Эцсийн эцэст, хүснэгтийн өгөгдлийг өөрөө өөрчлөхөөс гадна түүний индексийг дахин бүтээх шаардлагатай байна. Гэхдээ би аль хэдийн хэлсэнчлэн ердийн вэбсайтуудын хувьд энэ нь тийм ч том асуудал биш юм. Хэдийгээр та sql асуулгадаа ашигладаггүй хүснэгт дээр индекс үүсгэсэн ч энэ нь мэдэгдэхүйц асуудал үүсгэхгүй. Нэмж дурдахад нэмэлт модуль суулгаж эсвэл өөрөө асуулга оруулснаар энэ индекс маш хэрэгтэй байж болно.
Анхаарна уу: Гэсэн хэдий ч, энэ нь "боломжтой бүх талбарт индекс хийхийг зөвшөөрөх" сонголтод бус бүхэл тоон индексүүдэд хамаатай гэдгийг санаарай.
Хамгийн түгээмэл асуулгад зориулсан энгийн ба нийлмэл индексүүд.
Олон мэдээллийн санд асуулгад зориулсан үр дүнгийн кэш байдаг. Нэг хүсэлтийг хоёр удаа дараалан гүйцэтгэхийг хичээгээрэй - эхний тохиолдолд хүсэлтийг биелүүлэхэд удаан хугацаа шаардагдана, хоёр дахь удаагаа хурдан. Эхний удаа өгөгдлийг тооцоолохдоо хоёр дахь удаагаа кэшээс өгөгдлийг өгнө. Гэсэн хэдий ч асуулгад зориулж кэш бүтээгдээгүй тохиолдолд (жишээлбэл, шүүлтүүр нь суурилагдсан өгөгдлийн сангийн функцийг ашиглан тооцоолсон нөхцлүүдийг агуулж байгаа үед), ижил төрлийн боловч өөр өөр асуулгад ашигладаг тохиолдолд энэ нь тийм ч их тус болохгүй. параметрүүд, мөн ийм тохиолдолд, маш олон хүсэлт байгаа тул өгөгдөл нь кэшэд маш богино хугацаанд хадгалагддаг.
Тиймээс, байнга гүйцэтгэдэг асуулгад зориулж тогтмол болон нийлмэл индексийг үе үе бий болгох нь зүйтэй болов уу. Хоёр жишээг харцгаая.
Энгийн индекс.
Танд хүснэгт байна гэж бодъё - бүтээгдэхүүн (бүтээгдэхүүн - ID, код, нэр, текст). Сайтын хэрэглэгчид ихэвчлэн үсэг, тоон кодоор бүтээгдэхүүн хайж байдаг (нийтлэл - кодын талбар). Үүний дагуу хүсэлт дараах байдалтай байна.
Энэ тохиолдолд "код" талбарт тусдаа индекс үүсгэх нь утга учиртай тул мэдээллийн сан нь хүснэгтийн бүх бичлэгийг бүрэн скан хийх шаардлагагүй болно. Гэсэн хэдий ч мэдээллийн санд талбайн төрөл, хэмжээ хязгаарлагдмал байж болохыг анхаарна уу. Тиймээс та эхлээд ийм талбарт индекс үүсгэх боломжтой эсэхийг шалгах хэрэгтэй.
Нийлмэл индекс.
Нийлмэл индекстэй жишээ өгөхийн өмнө би нэг чухал зүйлийг бага зэрэг тодруулахыг хүсч байна - индекс дэх талбаруудын дараалал чухал юм. Хайлтыг эхлээд эхний талбар, дараа нь дараагийнх нь (гэх мэт) хийдэг. Тиймээс, хэрэв та зөвхөн сүүлчийн талбарын тодорхой утгыг мэддэг бол ийм индекс тохирохгүй, учир нь эхний талбарын тодорхой утгыг мэдэхгүй бол аль багц бичлэгийг шалгах шаардлагатайг тодорхойлох боломжгүй юм. яагаад мэдээллийн сан нь хүснэгтэд байгаа бүх бүртгэлийг сканнердах шаардлагатай болдог. Энгийнээр хэлбэл, индекс (багана_1, багана_2) нь индекстэй (багана_2, багана_1) тэнцүү биш байна.
Одоо дараах нөхцөл байдлыг төсөөлье. Гурван хүснэгт байдаг: хэрэглэгч (хэрэглэгч - id, нэр), ангилал (муур - id, нэр) болон нийтлэл (нийтлэл - id, cat_id, хэрэглэгчийн_id, нэр, текст). Мөн та сайт дээр ийм зүйл хийсэн - нийтлэлийн доод хэсэгт тухайн ангиллын ижил хэрэглэгчийн нийтлэлүүдийн бүрэн жагсаалтыг харуулав. Үүний зэрэгцээ хэрэглэгчид маш их үр бүтээлтэй байсан тул янз бүрийн ангилалд (жишээлбэл, жижиг түүх, богино тэмдэглэл гэх мэт) маш олон нийтлэл бичдэг. Энэ тохиолдолд хүсэлт дараах байдлаар харагдах болно.
Хэрэв та тодорхойлогч талбарт индекс хийсэн бол энэ нь танд туслах болно, гэхдээ тийм ч их биш. Нэгдүгээрт, ижил магадлалтай хоёр индекс байна. Нэг нь ангилалд, хоёр дахь нь хэрэглэгчдэд зориулагдсан. Аль нь илүү дээр байх нь ерөнхийдөө тодорхойгүй байна. Түүнчлэн, хэрэглэгчид 1000 нийтлэл, ангилал 1000 нийтлэлтэй байж болох тул энэ нь тийм ч их тус болохгүй байж магадгүй юм. Хоёрдугаарт, тодорхой хэрэглэгчийн (эсвэл категорийн) бүртгэлийг багасгасан ч гэсэн хоёр дахь талбарыг, өөрөөр хэлбэл бүрэн сканнерыг (бага хэмжээний бичлэгийн хувьд ч) ашиглан сканнердах шаардлагатай болно. Жишээлбэл, хэрэв хэрэглэгчид 1000 бүртгэлтэй бол та бүх 1000 бичлэгийг тухайн ангилалд хамаарах эсэхийг шалгах хэрэгтэй болно.
Олон тооны бичлэг, байнга дуудлагын хувьд энэ нь маш үнэтэй sql query юм. Тиймээс, энэ тохиолдолд нийлмэл индекс хийх нь зүйтэй, жишээлбэл, (user_id, cat_id) Энэ тохиолдолд хэрэглэгчээр хайсны дараа ангилалаар дараагийн хайлт илүү хурдан байх болно, учир нь үр дүнд нь индекс байх болно. бичлэгүүд. Үүний дагуу 1000 бүртгэлийг шалгахын оронд нэлээд цөөхөн шалгах болно (шалгалтыг ердийн индекс - логарифм + бичлэгийн тоотой ижил аргаар тооцдог).
Ийм нөхцөлд талбайн дарааллыг хэрхэн тодорхойлох вэ? Энд байгаа бүх зүйл маш энгийн бөгөөд шүүлтүүрийн тухай нийтлэлд тайлбарласантай төстэй (эхэнд байгаа холбоосыг үзнэ үү). Шүүлтүүр хэрэглэх тусам бичлэгийн тоо аль болох бага болдог гэдгийг сануулъя. Тиймээс хүснэгтийн талбарын утга тус бүрийн дундаж бичлэгийн тоог шалгах нь зүйтэй юм. Үүнээс бага тоотой талбар эхлээд явах ёстой. Жишээлбэл, өгөгдсөн SQL асуулгын хувьд дараахь зүйлийг шалгах нь зүйтэй.
Хэрэглэгчдэд зориулсан дундаж бичлэгийн тоог тооцоолох -- Бичлэгийн дундаж тоог авг(өгөгдлийн тоо)-аас дундажаар -- Бүх бичлэгийг танигчаар бүлэглэх (нийтлэлээс count(*)-ыг `count' гэж сонгох -- Хэрэглэгчээр бүлэглэх user_id) өгөгдөл болгон; -- Сонгох ангиллын бичлэгийн дундаж тоог тооцоолох -- Бичлэгийн дундаж тоог дундажаар (өгөгдлийн тоо) дунджаас авах -- Бүх бичлэгийг id-р бүлэглэх (нийтлэлээс count(*)-ыг `count' гэж сонгох -- Ангилалаар бүлэглэх cat_id ) өгөгдөл болгон бүлэг ;
Үүний дагуу, хэрэв хэрэглэгчдийн дундаж тоо бага байвал энэ талбар хамгийн түрүүнд байх ёстой, учир нь эхний хайлт хийсний дараа шалгах цөөн тооны бүртгэл байх болно. Үгүй бол категорийн ID хамгийн түрүүнд байх ёстой.
Гэсэн хэдий ч ийм нөхцөл байдалд бүртгэлүүд их бага хэмжээгээр жигд тархсан эсэхийг шалгах нь зүйтэй гэдгийг ойлгох нь зүйтэй. Эцсийн эцэст, 1 хэрэглэгч 2000 нийтлэл бичсэн бол үлдсэн нь ердөө 100. Ийм нөхцөлд ангиллын шүүлтүүрийг сонгох нь зүйтэй, учир нь ихэнх уншигчид тухайн хэрэглэгчийн нийтлэлийг үзэх болно. Тиймээс заримдаа зөвхөн тодорхойлогчдын бүлэглэлийг (дунджийг тооцохгүйгээр) тооцоолж, үр дүнг хурдан үзэх нь зүйтэй.
Хэрэв та гурав ба түүнээс дээш талбарт индекс үүсгэх шаардлагатай бол ижил зүйлийг хийх хэрэгтэй бөгөөд зөвхөн танигчаар бүлэглэх талбаруудын тоог нэмэгдүүлэх хэрэгтэй. Энгийн үгээр хэлбэл, эхлээд эхний талбарыг шалгаад хамгийн бага тоог тодорхойл, дараа нь "багана_1"-ийн оронд "багана_1, багана_2" хэлбэрээр, дараа нь "багана_1, багана_3" хэлбэрээр үлдсэн талбаруудтай төрөл бүрийн сонголтуудыг зааж өгнө. гэх мэт. Энэ тохиолдолд хүн бүр дундаж бичлэгийн тоо багасч, багасдаг хослолуудыг сонгодог.
Мөн индексүүд, энэ тусгай хайлтын хүснэгтүүд, өгөгдлийн хайлтыг хурдасгахын тулд мэдээллийн сангийн хайлтын систем ашиглаж болно. Энгийнээр хэлбэл, индекс нь хүснэгтийн өгөгдөлд заагч юм. Мэдээллийн сан дахь индекс нь номын ард байгаа индекстэй маш төстэй юм.
Жишээлбэл, хэрэв та тодорхой сэдвээр номны бүх хуудасны холбоосыг авахыг хүсвэл эхлээд бүх сэдвийг цагаан толгойн үсгийн дарааллаар жагсааж, дараа нь нэг буюу хэд хэдэн тодорхой хуудасны дугаарыг заадаг индексээс лавлана уу.
Индекс нь асуулга, өгүүлбэрийг хурдасгахад тусалдаг боловч мэдэгдлийн хамт өгөгдөл оруулах ажлыг удаашруулдаг ШИНЭЧЛЭХТэгээд INSERT. Өгөгдөлд нөлөөлөхгүйгээр индексийг үүсгэж эсвэл устгаж болно.
Индекс үүсгэх нь мэдэгдлийг агуулдаг ИНДЕКС ҮЗҮҮЛЭХ, энэ нь хүснэгтийг зааж өгөх индексийг нэрлэх, аль багана эсвэл баганыг индексжүүлэх, индекс өсөх эсвэл буурах дарааллаар байгааг зааж өгөх боломжийг олгодог.
Хязгаарлалттай индексүүд нь өвөрмөц байж болно Өвөрмөц, ингэснээр индекс нь багана эсвэл индекс бүхий баганын хослолд давхардсан оруулгуудаас сэргийлнэ.
CREATE INDEX команд
Үндсэн синтакс ИНДЕКС ҮЗҮҮЛЭХдараах байдлаар:
CREATE INDEX index_name ON table_name;
Нэг баганын индексүүд
Хүснэгтийн зөвхөн нэг багана дээр нэг баганын индекс үүсгэгддэг. Үндсэн синтакс нь дараах байдалтай байна.
CREATE INDEX index_name ON хүснэгтийн нэр(баганын_нэр);
Өвөрмөц индексүүд
Өвөрмөц индексийг зөвхөн үйл ажиллагаанд төдийгүй мэдээллийн бүрэн бүтэн байдлыг хангахад ашигладаг. Өвөрмөц индекс нь хүснэгтэд давхардсан утгыг оруулахыг зөвшөөрдөггүй. Үндсэн синтакс нь дараах байдалтай байна.
Хүснэгтийн_нэр (баганын_нэр) дээрх Өвөрмөц INDEX индекс_нэрийг ҮЗҮҮЛЭХ;
Нийлмэл индексүүд
Нийлмэл индекс гэдэг нь хүснэгтийн хоёр ба түүнээс дээш багана дээрх индекс юм. Үүний үндсэн синтакс нь дараах байдалтай байна.
Хүснэгтийн нэр дээрх индексийн_нэрийг CREATE INDEX (багана1, багана2);
Та нэг багана эсвэл нийлмэл индекс дээр индекс үүсгэсэн эсэхээс үл хамааран WHERE асуулгад шүүлтүүрийн нөхцөл болгон ашиглаж болох багана(ууд)-ыг анхаарч үзээрэй.
Хэрэв зөвхөн нэг багана ашиглагдаж байгаа бол индексийг нэг баганад сонгох ёстой. Хэрэв WHERE зүйлд шүүлтүүр болгон ашигладаг хоёр ба түүнээс дээш багана байгаа бол нийлмэл индекс нь илүү сайн сонголт байх болно.
Далд индексүүд
Далд индексүүд нь объект үүсгэх үед өгөгдлийн сангийн сервер дээр автоматаар үүсгэгддэг индексүүд юм. Индексүүд нь үндсэн түлхүүр болон өвөрмөц хязгаарлалт дээр автоматаар үүсгэгддэг.
DROP INDEX команд
SQL командыг ашиглан индексийг устгаж болно DROP. Гүйцэтгэл нь удаан эсвэл илүү сайн байж болзошгүй тул та индексийг устгахдаа болгоомжтой байх хэрэгтэй.
Үндсэн синтакс нь дараах байдалтай байна.
DROP INDEX индексийн нэр;
Та индекс дээрх бодит жишээг харахын тулд INDEX хязгаарлалтын жишээг харж болно.
Та хэзээ индексээс зайлсхийх ёстой вэ?
Хэдийгээр индексүүд нь өгөгдлийн сангийн гүйцэтгэлийг сайжруулах зорилготой боловч тэдгээрээс зайлсхийх үе байдаг.
Дараах заавар нь индексийн хэрэглээг хэзээ дахин авч үзэхийг зааж өгсөн болно.
- Индексийг жижиг хүснэгтэд ашиглаж болохгүй.
- Байнга том хэмжээний шинэчлэлт хийх эсвэл оруулах үйлдэлтэй хүснэгтүүд.
- Олон тооны тэг утгыг агуулсан баганууд дээр индексийг ашиглаж болохгүй.
- Байнга өөрчлөгддөг баганыг индексжүүлж болохгүй.