Im ersten Halbjahr 2016 erfuhr die Welt von vielen Entwicklungen im Bereich neuronaler Netze – Google (Go-Netzwerkplayer AlphaGo), Microsoft (eine Reihe von Diensten zur Bildidentifizierung), Startups MSQRD, Prisma und andere demonstrierten ihre Algorithmen.
Lesezeichen
Die Redakteure der Seite erzählen Ihnen, was neuronale Netze sind, wofür sie benötigt werden, warum sie den Planeten jetzt und nicht erst Jahre früher oder später erobert haben, wie viel Sie damit verdienen können und wer die wichtigsten Marktteilnehmer sind. Auch Experten von MIPT, Yandex, Mail.Ru Group und Microsoft äußerten ihre Meinung.
Was sind neuronale Netze und welche Probleme können sie lösen?
Neuronale Netze sind eine der Richtungen in der Entwicklung künstlicher Intelligenzsysteme. Die Idee besteht darin, die Funktionsweise des menschlichen Nervensystems – nämlich seine Fähigkeit, zu lernen und Fehler zu korrigieren – möglichst genau nachzubilden. Dies ist das Hauptmerkmal jedes neuronalen Netzwerks – es ist in der Lage, auf der Grundlage früherer Erfahrungen selbstständig zu lernen und zu handeln, wodurch jedes Mal immer weniger Fehler gemacht werden.
Das neuronale Netzwerk ahmt nicht nur die Aktivität, sondern auch die Struktur des menschlichen Nervensystems nach. Ein solches Netzwerk besteht aus einer Vielzahl einzelner Rechenelemente („Neuronen“). In den meisten Fällen gehört jedes „Neuron“ zu einer bestimmten Schicht des Netzwerks. Die Eingabedaten werden sequentiell auf allen Ebenen des Netzwerks verarbeitet. Die Parameter jedes „Neurons“ können sich abhängig von den Ergebnissen ändern, die anhand früherer Eingabedatensätze erzielt wurden, und somit die Betriebsreihenfolge des gesamten Systems ändern.
Der Leiter der Mail.ru-Suchabteilung der Mail.Ru Group, Andrey Kalinin, stellt fest, dass neuronale Netze in der Lage sind, die gleichen Probleme wie andere Algorithmen für maschinelles Lernen zu lösen, der Unterschied liegt nur im Trainingsansatz.
Alle Aufgaben, die neuronale Netze lösen können, haben irgendwie mit Lernen zu tun. Zu den Hauptanwendungsgebieten neuronaler Netze zählen Prognosen, Entscheidungsfindung, Mustererkennung, Optimierung und Datenanalyse.
Vlad Shershulsky, Direktor für Technologiekooperationsprogramme bei Microsoft in Russland, stellt fest, dass neuronale Netze mittlerweile überall eingesetzt werden: „Viele große Internetseiten nutzen sie beispielsweise, um Reaktionen auf Benutzerverhalten natürlicher und für ihr Publikum nützlicher zu gestalten.“ Neuronale Netze liegen den meisten modernen Spracherkennungs- und -synthesesystemen sowie der Bilderkennung und -verarbeitung zugrunde. Sie werden in einigen Navigationssystemen eingesetzt, sei es in Industrierobotern oder in selbstfahrenden Autos. Auf neuronalen Netzen basierende Algorithmen schützen Informationssysteme vor Angriffen durch Eindringlinge und helfen, illegale Inhalte im Netzwerk zu erkennen.“
Shershulsky geht davon aus, dass neuronale Netze in naher Zukunft (5 bis 10 Jahre) noch häufiger eingesetzt werden:
Stellen Sie sich einen landwirtschaftlichen Mähdrescher vor, dessen Antriebe mit vielen Videokameras ausgestattet sind. Es macht fünftausend Bilder pro Minute von jeder Pflanze auf ihrer Flugbahn und analysiert mithilfe eines neuronalen Netzwerks, ob es sich um Unkraut handelt, ob sie von Krankheiten oder Schädlingen befallen ist. Und jede Pflanze wird individuell behandelt. Fiktion? Eigentlich nicht mehr. Und in fünf Jahren könnte es zur Norm werden. - Vlad Shershulsky, Microsoft
Mikhail Burtsev, Leiter des Labors für neuronale Systeme und Deep Learning am MIPT Center for Living Systems, liefert eine vorläufige Karte der Entwicklung neuronaler Netze für 2016–2018:
- Systeme zur Erkennung und Klassifizierung von Objekten in Bildern;
- Sprachinteraktionsschnittstellen für das Internet der Dinge;
- Systeme zur Überwachung der Servicequalität in Callcentern;
- Systeme zur Identifizierung von Problemen (einschließlich der Vorhersage von Wartungszeiten), Anomalien und cyberphysischen Bedrohungen;
- geistige Sicherheits- und Überwachungssysteme;
- Ersetzen einiger Funktionen von Callcenter-Betreibern durch Bots;
- Videoanalysesysteme;
- selbstlernende Systeme, die das Management von Materialflüssen oder die Lage von Gegenständen (in Lagern, Transport) optimieren;
- Intelligente, selbstlernende Steuerungssysteme für Produktionsprozesse und Geräte (einschließlich Robotik);
- das Aufkommen universeller On-the-Fly-Übersetzungssysteme für Konferenzen und den persönlichen Gebrauch;
- das Aufkommen von Bot-Beratern für den technischen Support oder persönlichen Assistenten mit Funktionen, die denen eines Menschen ähneln.
Grigory Bakunov, Director of Technology Distribution bei Yandex, glaubt, dass die Grundlage für die Verbreitung neuronaler Netze in den nächsten fünf Jahren die Fähigkeit solcher Systeme sein wird, verschiedene Entscheidungen zu treffen: „Die Hauptsache, die neuronale Netze jetzt für einen Menschen tun, ist zu sparen.“ ihn vor unnötigen Entscheidungen. Sie können also fast überall dort eingesetzt werden, wo nicht sehr intelligente Entscheidungen von einem lebenden Menschen getroffen werden. In den nächsten fünf Jahren wird diese Fähigkeit genutzt, um die menschliche Entscheidungsfindung durch eine einfache Maschine zu ersetzen.“
Warum sind neuronale Netze gerade jetzt so beliebt?
Wissenschaftler entwickeln seit mehr als 70 Jahren künstliche neuronale Netze. Der erste Versuch, ein neuronales Netzwerk zu formalisieren, geht auf das Jahr 1943 zurück, als zwei amerikanische Wissenschaftler (Warren McCulloch und Walter Pitts) einen Artikel über die logische Berechnung menschlicher Ideen und neuronaler Aktivität vorlegten.
Doch bis vor Kurzem, sagt Andrey Kalinin von der Mail.Ru Group, sei die Geschwindigkeit neuronaler Netze zu niedrig gewesen, als dass sie sich verbreitet hätten, weshalb solche Systeme hauptsächlich in Entwicklungen im Zusammenhang mit Computer Vision eingesetzt worden seien und in anderen Bereichen andere Algorithmen zum Einsatz gekommen seien maschinelles Lernen.
Ein arbeitsintensiver und zeitaufwändiger Teil des Entwicklungsprozesses neuronaler Netze ist das Training. Damit ein neuronales Netzwerk die zugewiesenen Probleme korrekt lösen kann, muss es seine Arbeit auf zig Millionen Eingabedatensätzen „ausführen“. Mit dem Aufkommen verschiedener beschleunigter Lerntechnologien verbinden Andrei Kalinin und Grigory Bakunov die Verbreitung neuronaler Netze.
Das Wichtigste, was jetzt passiert ist, ist, dass verschiedene Tricks aufgetaucht sind, die es ermöglichen, neuronale Netze zu erstellen, die viel weniger anfällig für Umschulungen sind – Grigory Bakunov, Yandex
„Erstens ist eine große und öffentlich zugängliche Sammlung beschrifteter Bilder (ImageNet) erschienen, auf der man lernen kann. Zweitens ermöglichen moderne Grafikkarten, neuronale Netze zu trainieren und hunderte Male schneller zu nutzen. Drittens sind fertige, vorab trainierte neuronale Netze erschienen, die Bilder erkennen, auf deren Grundlage Sie eigene Anwendungen erstellen können, ohne das neuronale Netz lange für die Arbeit vorbereiten zu müssen. All dies sorgt für eine sehr leistungsstarke Entwicklung neuronaler Netze speziell im Bereich der Bilderkennung“, bemerkt Kalinin.
Wie groß ist der Markt für neuronale Netze?
„Sehr einfach zu berechnen. Sie können jeden Bereich nehmen, in dem gering qualifizierte Arbeitskräfte eingesetzt werden, beispielsweise Call-Center-Agenten, und einfach alle Personalressourcen abziehen. Ich würde sagen, dass wir über einen Multimilliarden-Dollar-Markt sprechen, selbst innerhalb eines einzelnen Landes. Es ist leicht zu verstehen, wie viele Menschen auf der Welt in gering qualifizierten Berufen beschäftigt sind. Selbst wenn wir also sehr abstrakt sprechen, sprechen wir meiner Meinung nach von einem 100-Milliarden-Dollar-Markt auf der ganzen Welt“, sagt Grigory Bakunov, Direktor für Technologievertrieb bei Yandex.
Schätzungen zufolge werden mehr als die Hälfte der Berufe automatisiert sein – das ist das maximale Volumen, um das der Markt für maschinelle Lernalgorithmen (und insbesondere neuronale Netze) wachsen kann – Andrey Kalinin, Mail.Ru Group
„Algorithmen für maschinelles Lernen sind der nächste Schritt bei der Automatisierung aller Prozesse und bei der Entwicklung jeder Software. Daher deckt sich der Markt zumindest mit dem gesamten Softwaremarkt, sondern übertrifft ihn vielmehr, weil es möglich wird, neue intelligente Lösungen zu entwickeln, die für alte Software unzugänglich sind“, fährt Andrey Kalinin fort, Leiter der Mail.ru-Suchabteilung bei Mail. Ru-Gruppe.
Warum erstellen Entwickler neuronaler Netze mobile Anwendungen für den Massenmarkt?
In den letzten Monaten sind mehrere hochkarätige Unterhaltungsprojekte mit neuronalen Netzen auf den Markt gekommen – das sind der beliebte Videodienst, das soziale Netzwerk Facebook und russische Anwendungen zur Bildverarbeitung (Investitionen der Mail.Ru Group im Juni) und andere.
Die Fähigkeiten ihrer eigenen neuronalen Netze wurden sowohl von Google (die AlphaGo-Technologie gewann gegen den Champion in Go; im März 2016 versteigerte das Unternehmen 29 von neuronalen Netzen gezeichnete Gemälde usw.) als auch von Microsoft (das CaptionBot-Projekt, das erkennt Bilder in Fotos und generiert automatisch Bildunterschriften dafür; das WhatDog-Projekt, das die Rasse eines Hundes anhand eines Fotos bestimmt; der HowOld-Dienst, der das Alter einer Person auf einem Foto bestimmt usw.; Im Juni integrierte das Team einen Dienst zum Erkennen von Autos auf Fotos in die Anwendung Avto.ru; im Mai erstellte sie das Album LikeMo.net zum Zeichnen im Stil berühmter Künstler.
Solche Unterhaltungsdienste werden nicht geschaffen, um globale Probleme zu lösen, auf die neuronale Netze abzielen, sondern um die Fähigkeiten eines neuronalen Netzes zu demonstrieren und sein Training durchzuführen.
„Spiele sind ein charakteristisches Merkmal unseres Verhaltens als Spezies. Einerseits können Spielsituationen genutzt werden, um nahezu alle typischen Szenarien menschlichen Verhaltens zu simulieren, andererseits können Spieleentwickler und insbesondere Spieler viel Freude daran haben. Es gibt auch einen rein utilitaristischen Aspekt. Ein gut gestaltetes Spiel macht den Spielern nicht nur Freude: Beim Spielen trainieren sie auch den Algorithmus des neuronalen Netzwerks. Schließlich basieren neuronale Netze auf dem Lernen durch Beispiele“, sagt Vlad Shershulsky von Microsoft.
„Dies geschieht zunächst einmal, um die Leistungsfähigkeit der Technologie zu zeigen. Es gibt eigentlich keinen anderen Grund. Wenn wir über Prisma sprechen, ist klar, warum sie es getan haben. Die Jungs haben eine Art Pipeline gebaut, die es ihnen ermöglicht, mit Bildern zu arbeiten. Um dies zu demonstrieren, wählten sie eine recht einfache Methode zur Erstellung von Stilisierungen. Warum nicht? „Das ist nur eine Demonstration der Funktionsweise der Algorithmen“, sagt Grigory Bakunov von Yandex.
Andrey Kalinin von der Mail.Ru Group ist anderer Meinung: „Das ist natürlich aus Sicht der Öffentlichkeit beeindruckend. Andererseits würde ich nicht sagen, dass Unterhaltungsprodukte nicht auch in nützlicheren Bereichen eingesetzt werden können. Beispielsweise ist die Aufgabe der Stilisierung von Bildern für eine Reihe von Branchen äußerst relevant (Design, Computerspiele, Animation sind nur einige Beispiele), und die vollständige Nutzung neuronaler Netze kann die Kosten und Methoden zur Erstellung von Inhalten für diese Branchen erheblich optimieren. ”
Hauptakteure auf dem Markt für neuronale Netze
Wie Andrey Kalinin feststellt, unterscheiden sich die meisten neuronalen Netze auf dem Markt im Großen und Ganzen nicht wesentlich voneinander. „Die Technologie ist bei jedem ungefähr gleich. Aber die Nutzung neuronaler Netze ist ein Vergnügen, das sich nicht jeder leisten kann. Um ein neuronales Netzwerk unabhängig zu trainieren und viele Experimente damit durchzuführen, benötigen Sie große Trainingssätze und eine Flotte von Maschinen mit teuren Grafikkarten. Offensichtlich haben große Unternehmen solche Möglichkeiten“, sagt er.
Unter den wichtigsten Marktteilnehmern nennt Kalinin Google und seine Abteilung Google DeepMind, die das AlphaGo-Netzwerk geschaffen hat, sowie Google Brain. Microsoft hat in diesem Bereich eigene Entwicklungen – diese werden vom Microsoft Research Labor durchgeführt. Die Erstellung neuronaler Netze wird bei IBM, Facebook (einer Abteilung von Facebook AI Research), Baidu (Baidu Institute of Deep Learning) und anderen durchgeführt. Viele Entwicklungen werden an technischen Universitäten auf der ganzen Welt durchgeführt.
Grigory Bakunov, Vertriebsdirektor von Yandex Technology, weist darauf hin, dass es auch bei Start-ups interessante Entwicklungen im Bereich neuronaler Netze gibt. „Ich erinnere mich zum Beispiel an die Firma ClarifAI. Dies ist ein kleines Startup, das einst von Leuten von Google gegründet wurde. Jetzt sind sie vielleicht die Besten der Welt, wenn es darum geht, den Inhalt eines Bildes zu bestimmen.“ Zu diesen Startups gehören MSQRD, Prisma und andere.
In Russland werden Entwicklungen im Bereich neuronaler Netze nicht nur von Startups, sondern auch von großen Technologieunternehmen durchgeführt – beispielsweise nutzt die Holding Mail.Ru Group neuronale Netze zur Verarbeitung und Klassifizierung von Texten in der Suche und Bildanalyse. Das Unternehmen führt auch experimentelle Entwicklungen im Zusammenhang mit Bots und Konversationssystemen durch.
Yandex baut auch eigene neuronale Netze auf: „Grundsätzlich werden solche Netze bereits bei der Arbeit mit Bild und Ton eingesetzt, aber wir erforschen ihre Möglichkeiten auch in anderen Bereichen.“ Jetzt führen wir viele Experimente zur Verwendung neuronaler Netze bei der Arbeit mit Text durch.“ Entwicklungen werden an Universitäten durchgeführt: Skoltech, MIPT, Moskauer Staatsuniversität, Higher School of Economics und anderen.
Wenn Sie Nachrichten aus der Welt der Wissenschaft und Technologie verfolgen, haben Sie wahrscheinlich schon etwas über das Konzept neuronaler Netze gehört.
Im Jahr 2016 schlug beispielsweise das neuronale Netzwerk AlphaGo von Google einen der besten professionellen Counter-Strike: Global Offensive-Spieler der Welt mit einer Punktzahl von 4:1. YouTube kündigte außerdem an, dass sie neuronale Netze nutzen werden, um ihre Videos besser zu verstehen.
Aber was ist ein neuronales Netzwerk? Wie funktioniert das? Und warum sind sie in der maschinellen Bearbeitung so beliebt?
Computer als Gehirn
Moderne Neurowissenschaftler diskutieren das Gehirn oft als eine Art Computer. Neuronale Netze haben das Gegenteil zum Ziel: einen Computer zu bauen, der wie ein Gehirn funktioniert.
Natürlich haben wir nur ein oberflächliches Verständnis der äußerst komplexen Funktionen des Gehirns, aber durch die Erstellung vereinfachter Simulationen der Art und Weise, wie das Gehirn Daten verarbeitet, können wir einen Computertyp bauen, der ganz anders funktioniert als ein Standardcomputer.
Computerprozessoren verarbeiten Daten sequentiell („in der Reihenfolge“). Sie führen nacheinander viele Operationen an einem Datensatz durch. Parallele Verarbeitung („mehrere Threads gleichzeitig verarbeiten“) beschleunigt einen Computer erheblich, indem mehrere Prozessoren in Reihe geschaltet werden.
In der folgenden Abbildung erfordert das Parallelverarbeitungsbeispiel fünf verschiedene Prozessoren:
Ein künstliches neuronales Netzwerk (so genannt, um es von echten neuronalen Netzwerken im Gehirn zu unterscheiden) hat einen grundlegend anderen Aufbau. Es ist sehr vernetzt. Dadurch können Sie Daten sehr schnell verarbeiten, aus diesen Daten lernen und Ihre eigene interne Struktur aktualisieren, um die Leistung zu verbessern.
Der hohe Grad der Vernetzung hat jedoch einige bemerkenswerte Konsequenzen. Neuronale Netze sind beispielsweise sehr gut darin, unklare Datenstrukturen zu erkennen.
Lernfähigkeit
Die Lernfähigkeit eines neuronalen Netzwerks ist seine größte Stärke. In einer Standard-Computerarchitektur muss ein Programmierer einen Algorithmus entwerfen, der dem Computer sagt, was er mit den eingehenden Daten tun soll, um sicherzustellen, dass der Computer die richtige Antwort liefert.
Die Antwort auf E/A kann so einfach sein wie „Wenn die A-Taste gedrückt wird“, „A wird auf dem Bildschirm angezeigt“ oder komplexer als die Durchführung komplexer Statistiken. Andererseits erfordern neuronale Netze nicht dieselben Algorithmen. Durch Lernmechanismen können sie im Wesentlichen eigene Algorithmen entwickeln. Maschinenalgorithmen sorgen dafür, dass sie korrekt funktionieren.
Es ist wichtig zu beachten, dass die aktuelle Technologie immer noch Einschränkungen mit sich bringt, da es sich bei neuronalen Netzen um Programme handelt, die auf Maschinen geschrieben werden, die Standardhardware für die serielle Verarbeitung verwenden. Tatsächlich ist die Erstellung einer Hardwareversion eines neuronalen Netzwerks ein völlig anderes Problem.
Von Neuronen zu Knoten
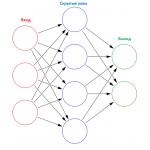
Nachdem wir nun den Grundstein für die Funktionsweise neuronaler Netze gelegt haben, können wir uns mit einigen Einzelheiten befassen. Der Grundaufbau eines künstlichen neuronalen Netzes sieht folgendermaßen aus:

Jeder der Kreise wird als „Knoten“ bezeichnet und simuliert ein einzelnes Neuron. Auf der linken Seite befinden sich die Eingabeknoten, in der Mitte die ausgeblendeten Knoten und auf der rechten Seite die Ausgabeknoten.
Im einfachsten Sinne akzeptieren Eingabeknoten Eingabewerte, die binär 1 oder 0, Teil eines RGB-Farbwerts, der Status einer Schachfigur oder irgendetwas anderes sein können. Diese Knoten stellen Informationen dar, die in das Netzwerk gelangen.
Jeder Eingabeknoten ist mit mehreren versteckten Knoten verbunden (manchmal mit jedem versteckten Knoten, manchmal mit einer Teilmenge). Eingabeknoten nehmen die Informationen, die sie erhalten, und geben sie an die verborgene Ebene weiter.
Beispielsweise könnte ein Eingabeknoten ein Signal („Feuer“ im neurowissenschaftlichen Sprachgebrauch) senden, wenn er eine 1 empfängt, und inaktiv bleiben, wenn er eine Null empfängt. Jeder versteckte Knoten hat einen Schwellenwert: Wenn alle seine summierten Eingaben einen bestimmten Wert erreichen, wird er ausgelöst.
Von Synapsen zu Verbindungen
Jede Verbindung, die einer anatomischen Synapse entspricht, hat auch ein bestimmtes Gewicht, wodurch das Netzwerk der Aktion eines bestimmten Knotens mehr Aufmerksamkeit schenken kann. Hier ist ein Beispiel:

Wie Sie sehen, ist das Gewicht der Verbindung „B“ höher als das der Verbindung „A“ und „C“. Nehmen wir an, der versteckte Knoten „4“ wird nur ausgelöst, wenn er eine Gesamteingabe von „2“ oder mehr erhält. Das heißt, wenn „1“ oder „3“ einzeln feuert, dann wird „4“ nicht feuern, sondern „1“ und „3“ zusammen lösen den Knoten aus. Knoten „2“ kann über die Verbindung „B“ auch den Knoten selbst initiieren.
Nehmen wir das Wetter als praktisches Beispiel. Nehmen wir an, Sie entwerfen ein einfaches neuronales Netzwerk, um zu bestimmen, ob eine Wintersturmwarnung erfolgen sollte.
Mit den oben genannten Verbindungen und Gewichten kann Knoten 4 nur dann auslösen, wenn die Temperatur unter -18 °C liegt und der Wind über 48 km/s weht, oder er wird auslösen, wenn die Schneewahrscheinlichkeit mehr als 70 Prozent beträgt. Temperaturen werden an Knoten 1, Winde an Knoten 3 und die Schneewahrscheinlichkeit an Knoten 2 weitergeleitet. Jetzt kann Knoten 4 all dies berücksichtigen, wenn er bestimmt, welches Signal an die Ausgabeebene gesendet werden soll.
Besser als einfache Logik
Natürlich könnte diese Funktion auch einfach mit einfachen UND/ODER-Gattern implementiert werden. Aber komplexere neuronale Netze, wie die folgenden, sind zu viel komplexeren Operationen fähig.

Die Knoten der Ausgabeschicht funktionieren auf die gleiche Weise wie die verborgene Schicht: Die Ausgabeknoten summieren die Eingaben der verborgenen Schicht, und wenn sie einen bestimmten Wert erreichen, lösen die Ausgabeknoten bestimmte Signale aus und senden sie. Am Ende des Prozesses sendet die Ausgabeschicht eine Reihe von Signalen, die das Ergebnis der Eingabe anzeigen.
Während das oben gezeigte Netzwerk einfach ist, können tiefe neuronale Netzwerke viele verborgene Schichten und Hunderte von Knoten haben.

Fehlerbehebung
Dieser Vorgang ist noch relativ einfach. Aber wo neuronale Netze wirklich benötigt werden, ist das Lernen. Die meisten neuronalen Netze verwenden einen Backpropagation-Prozess, der Signale durch das Netzwerk zurücksendet.
Bevor Entwickler ein neuronales Netzwerk bereitstellen, durchlaufen sie eine Trainingsphase, in der es eine Reihe von Eingaben mit bekannten Ausgaben empfängt. Beispielsweise kann ein Programmierer einem neuronalen Netzwerk beibringen, Bilder zu erkennen. Die Eingabe könnte ein Bild eines Autos sein, und die korrekte Ausgabe wäre das Wort „Auto“.
Der Programmierer stellt ein Bild als Eingabe bereit und sieht, was aus den Ausgabeknoten kommt. Wenn das Netzwerk mit „Flugzeug“ antwortet, teilt der Programmierer dem Computer mit, dass es falsch ist.
Das Netzwerk nimmt dann Anpassungen an seinen eigenen Verbindungen vor und verändert so die Gewichtung verschiedener Verbindungen zwischen Knoten. Diese Aktion basiert auf einem speziellen Lernalgorithmus, der dem Netzwerk hinzugefügt wird. Das Netzwerk passt die Verbindungsgewichte weiter an, bis die korrekte Ausgabe erfolgt.
Dies ist eine Vereinfachung, aber neuronale Netze können nach ähnlichen Prinzipien sehr komplexe Operationen lernen.
Kontinuierliche Verbesserung
Auch nach dem Training geht die Backpropagation (Training) weiter – und hier werden neuronale Netze wirklich sehr, sehr cool. Sie lernen während der Verwendung weiter, integrieren neue Informationen und nehmen Änderungen an den Gewichten verschiedener Verbindungen vor, wodurch sie bei der Aufgabe, für die sie entwickelt wurden, immer effektiver werden.
Es kann so einfach sein wie Mustererkennung oder so komplex wie das Spielen von CS:GO.
Daher verändern und verbessern sich neuronale Netze ständig. Und das kann unerwartete Folgen haben und zu Netzwerken führen, die Dinge priorisieren, die ein Programmierer nicht als Priorität betrachten würde.
Neben dem oben beschriebenen Prozess, der als überwachtes Lernen bezeichnet wird, gibt es noch eine weitere Methode: unüberwachtes Lernen.
In dieser Situation nehmen neuronale Netze Eingabedaten und versuchen, sie genau so wie ihre Ausgabe wiederherzustellen, indem sie Backpropagation verwenden, um ihre Verbindungen zu aktualisieren. Das hört sich vielleicht wie eine sinnlose Übung an, aber auf diese Weise lernen Netzwerke, nützliche Funktionen zu extrahieren und diese Funktionen zu verallgemeinern, um ihre Modelle zu verbessern.
Fragen der Tiefe
Backpropagation ist eine sehr effektive Methode, neuronale Netze zu trainieren, wenn sie nur aus wenigen Schichten bestehen. Mit zunehmender Anzahl verborgener Schichten nimmt die Effizienz der Rückausbreitung ab. Dies ist ein Problem für tiefe Netzwerke. Durch Backpropagation sind sie oft nicht effizienter als einfache Netzwerke.
Wissenschaftler haben eine Reihe von Lösungen für dieses Problem entwickelt, deren Einzelheiten recht komplex sind und den Rahmen dieses Einführungsteils sprengen würden. Laienhaft ausgedrückt versuchen viele dieser Lösungen, die Komplexität des Netzwerks zu reduzieren, indem sie ihm beibringen, Daten zu „komprimieren“.

Um dies zu erreichen, lernt das Netzwerk, weniger identifizierende Merkmale aus den Eingabedaten zu extrahieren und wird so letztendlich effizienter in seinen Berechnungen. Im Wesentlichen führt das Netzwerk Verallgemeinerungen und Abstraktionen durch, ähnlich wie Menschen lernen.
Nach diesem Training kann das Netzwerk Knoten und Verbindungen entfernen, die es für weniger wichtig hält. Dadurch wird das Netzwerk effizienter und das Lernen einfacher.
Anwendungen für neuronale Netze
Auf diese Weise modellieren neuronale Netze, wie das Gehirn mithilfe mehrerer Knotenebenen – Eingabe, verborgen und Ausgabe – lernt, und sie können sowohl in überwachten als auch in unbeaufsichtigten Situationen lernen. Komplexe Netzwerke sind in der Lage, Abstraktionen und Verallgemeinerungen vorzunehmen, was sie effizienter und lernfähiger macht.
Wofür können wir diese spannenden Systeme nutzen?
Theoretisch können wir neuronale Netze für fast alles nutzen. Und Sie haben sie wahrscheinlich verwendet, ohne es zu merken. Sie sind beispielsweise bei der Sprach- und visuellen Erkennung sehr verbreitet, da sie lernen können, bestimmte Merkmale zu erkennen, die in Tönen oder Bildern häufig vorkommen.
Wenn Sie also „OK Google“ sagen, leitet Ihr iPhone Ihre Sprache durch ein neuronales Netzwerk, um zu verstehen, was Sie sagen. Vielleicht gibt es ein anderes neuronales Netzwerk, das lernt, vorherzusagen, wonach Sie wahrscheinlich fragen werden.
Selbstfahrende Autos können neuronale Netze nutzen, um visuelle Daten zu verarbeiten und so Verkehrsregeln einzuhalten und Kollisionen zu vermeiden. Roboter aller Art können von neuronalen Netzen profitieren, die ihnen helfen, Aufgaben effizient auszuführen. Computer können lernen, Spiele wie Schach oder CS:GO zu spielen. Wenn Sie jemals mit einem Chatbot interagiert haben, nutzt dieser wahrscheinlich ein neuronales Netzwerk, um entsprechende Antworten vorzuschlagen.
Die Internetsuche kann von neuronalen Netzen stark profitieren, da das hocheffiziente Parallelverarbeitungsmodell schnell viele Daten generieren kann. Das neuronale Netzwerk kann auch Ihre Gewohnheiten lernen, um Ihre Suchergebnisse zu personalisieren oder vorherzusagen, wonach Sie in naher Zukunft suchen werden. Dieses Vorhersagemodell wird offensichtlich für Vermarkter (und jeden, der komplexes menschliches Verhalten vorhersagen muss) sehr wertvoll sein.
Mustererkennung, optische Bilderkennung, Börsenprognosen, Routenfindung, Big-Data-Verarbeitung, medizinische Kostenanalyse, Umsatzprognosen, künstliche Intelligenz in Videospielen – die Möglichkeiten sind nahezu endlos. Die Fähigkeit neuronaler Netze, Muster zu lernen, Verallgemeinerungen vorzunehmen und Verhalten erfolgreich vorherzusagen, macht sie in unzähligen Situationen wertvoll.
Die Zukunft neuronaler Netze
Neuronale Netze haben sich von sehr einfachen Modellen zu Lernsimulatoren auf hohem Niveau entwickelt. Sie befinden sich auf unseren Telefonen, Tablets und vielen der von uns genutzten Webdienste. Es gibt viele andere maschinelle Lernsysteme.
Aber neuronale Netze gehören aufgrund ihrer Ähnlichkeit (in sehr vereinfachter Form) mit dem menschlichen Gehirn zu den faszinierendsten. Während wir die Modelle kontinuierlich weiterentwickeln und verbessern, können wir nicht sagen, wozu sie in der Lage sind.
Kennen Sie interessante Anwendungen neuronaler Netze? Haben Sie selbst Erfahrung mit ihnen? Was begeistert Sie an dieser Technologie am meisten? Teilen Sie Ihre Gedanken in den Kommentaren unten mit!
Ein künstliches neuronales Netzwerk ist eine Ansammlung von Neuronen, die miteinander interagieren. Sie sind in der Lage, Daten zu empfangen, zu verarbeiten und zu erzeugen. Es ist ebenso schwer vorstellbar wie die Funktionsweise des menschlichen Gehirns. Damit Sie das jetzt lesen können, funktioniert das neuronale Netzwerk in unserem Gehirn: Unsere Neuronen erkennen Buchstaben und setzen sie in Worte.
Ein künstliches neuronales Netzwerk ist wie ein Gehirn. Es wurde ursprünglich programmiert, um einige komplexe Rechenprozesse zu vereinfachen. Heute haben neuronale Netze viel mehr Möglichkeiten. Einige davon befinden sich auf Ihrem Smartphone. Ein anderer Teil hat bereits in seiner Datenbank vermerkt, dass Sie diesen Artikel geöffnet haben. Wie das alles passiert und warum, lesen Sie weiter.
Wie alles begann
Die Menschen wollten unbedingt verstehen, woher der Geist eines Menschen kommt und wie das Gehirn funktioniert. Mitte des letzten Jahrhunderts erkannte der kanadische Neuropsychologe Donald Hebb dies. Hebb untersuchte die Interaktion von Neuronen untereinander, untersuchte das Prinzip, nach dem sie zu Gruppen (wissenschaftlich gesprochen Ensembles) zusammengefasst werden, und schlug den ersten wissenschaftlichen Algorithmus zum Training neuronaler Netze vor.
Einige Jahre später modellierte eine Gruppe amerikanischer Wissenschaftler ein künstliches neuronales Netzwerk, das quadratische Formen von anderen Formen unterscheiden konnte.
Wie funktioniert ein neuronales Netzwerk?
Forscher haben herausgefunden, dass ein neuronales Netzwerk eine Ansammlung von Schichten von Neuronen ist, von denen jede für die Erkennung eines bestimmten Kriteriums verantwortlich ist: Form, Farbe, Größe, Textur, Klang, Lautstärke usw. Jahr für Jahr, als Ergebnis von Millionen von Durch Experimente und jede Menge Berechnungen wurden dem einfachsten Netzwerk neue und neue Schichten von Neuronen hinzugefügt. Sie arbeiten abwechselnd. Zum Beispiel bestimmt der erste, ob ein Quadrat quadratisch ist oder nicht, der zweite versteht, ob ein Quadrat rot ist oder nicht, der dritte berechnet die Größe des Quadrats und so weiter. Nicht Quadrate, nicht Rot und Formen mit ungeeigneter Größe landen in neuen Gruppen von Neuronen und werden von diesen erforscht.
Was sind neuronale Netze und was können sie?
Wissenschaftler haben neuronale Netze entwickelt, um komplexe Bilder, Videos, Texte und Sprache unterscheiden zu können. Heutzutage gibt es viele Arten neuronaler Netze. Sie werden je nach Architektur klassifiziert – Datenparametersätze und das Gewicht dieser Parameter haben eine bestimmte Priorität. Nachfolgend sind einige davon aufgeführt.
Faltungs-Neuronale Netze
Neuronen werden in Gruppen eingeteilt, jede Gruppe berechnet eine ihr gegebene Eigenschaft. Im Jahr 1993 präsentierte der französische Wissenschaftler Yann LeCun der Welt LeNet 1, das erste Faltungs-Neuronale Netzwerk, das von Hand auf Papier geschriebene Zahlen schnell und genau erkennen konnte. Sehen Sie selbst:
Heutzutage werden Faltungs-Neuronale Netze hauptsächlich für Multimedia-Zwecke verwendet: Sie arbeiten mit Grafiken, Audio und Video.
Wiederkehrende neuronale Netze
Neuronen merken sich nacheinander Informationen und bauen auf der Grundlage dieser Daten weitere Aktionen auf. 1997 haben deutsche Wissenschaftler die einfachsten rekurrenten Netzwerke in Netzwerke mit langem Kurzzeitgedächtnis umgewandelt. Darauf aufbauend wurden dann Netzwerke mit kontrollierten rekurrenten Neuronen entwickelt.
Mithilfe solcher Netzwerke werden heute Texte geschrieben und übersetzt, Bots so programmiert, dass sie sinnvolle Dialoge mit Menschen führen, sowie Seiten- und Programmcodes erstellt.
Der Einsatz dieser Art von neuronalen Netzen bietet die Möglichkeit, Daten zu analysieren und zu generieren, Datenbanken zusammenzustellen und sogar Vorhersagen zu treffen.
Im Jahr 2015 veröffentlichte SwiftKey die weltweit erste Tastatur, die auf einem rekurrenten neuronalen Netzwerk mit kontrollierten Neuronen läuft. Dann lieferte das System beim Tippen Hinweise basierend auf den zuletzt eingegebenen Wörtern. Letztes Jahr trainierten Entwickler ein neuronales Netzwerk, um den Kontext des eingegebenen Textes zu untersuchen, und die Hinweise wurden aussagekräftig und nützlich:

Kombinierte neuronale Netze (Faltung + rekurrent)
Solche neuronalen Netze sind in der Lage, den Bildinhalt zu verstehen und zu beschreiben. Und umgekehrt: Zeichnen Sie Bilder gemäß der Beschreibung. Das auffälligste Beispiel wurde von Kyle MacDonald demonstriert, der mit einem neuronalen Netzwerk einen Spaziergang durch Amsterdam machte. Das Netzwerk erkannte sofort, was sich vor ihm befand. Und fast immer genau:

Neuronale Netze sind ständig selbstlernend. Durch diesen Prozess:
1. Skype hat Simultanübersetzungsfunktionen für 10 Sprachen eingeführt. Darunter sind für einen Moment Russisch und Japanisch – einige der schwierigsten der Welt. Natürlich muss die Qualität der Übersetzung erheblich verbessert werden, aber die Tatsache, dass Sie jetzt mit Kollegen aus Japan auf Russisch kommunizieren und sicher sein können, dass Sie verstanden werden, ist inspirierend.
2. Yandex hat zwei Suchalgorithmen basierend auf neuronalen Netzen erstellt: „Palekh“ und „Korolev“. Die erste Methode half dabei, die relevantesten Websites für Suchanfragen mit geringer Häufigkeit zu finden. „Palekh“ studierte die Seitenüberschriften und verglich ihre Bedeutung mit der Bedeutung der Anfragen. Basierend auf Palekh erschien Korolev. Dieser Algorithmus wertet nicht nur den Titel, sondern den gesamten Textinhalt der Seite aus. Die Suche wird immer präziser und Websitebesitzer beginnen, den Seiteninhalt intelligenter anzugehen.
3. SEO-Kollegen von Yandex haben ein musikalisches neuronales Netzwerk geschaffen: Es komponiert Gedichte und schreibt Musik. Die Neurogruppe heißt symbolisch Neurona und hat bereits ihr erstes Album:

4. Google Inbox nutzt neuronale Netze, um auf Nachrichten zu antworten. Die Technologieentwicklung ist in vollem Gange und das Netzwerk untersucht bereits heute die Korrespondenz und generiert mögliche Antwortoptionen. Sie müssen keine Zeit mit Tippen verschwenden und haben keine Angst, eine wichtige Vereinbarung zu vergessen.

5. YouTube verwendet neuronale Netze, um Videos zu bewerten, und zwar nach zwei Prinzipien gleichzeitig: Ein neuronales Netz untersucht Videos und die Reaktionen des Publikums darauf, das andere erforscht Nutzer und ihre Vorlieben. Deshalb sind YouTube-Empfehlungen immer auf den Punkt gebracht.
6. Facebook arbeitet aktiv an DeepText AI, einem Kommunikationsprogramm, das Fachjargon versteht und Chats von obszöner Sprache befreit.
7. Apps wie Prisma und Fabby, die auf neuronalen Netzen basieren, erstellen Bilder und Videos:

Colorize stellt die Farben in Schwarzweißfotos wieder her (Überraschung, Oma!).

MakeUp Plus wählt den perfekten Lippenstift für Mädchen aus einer echten Auswahl echter Marken aus: Bobbi Brown, Clinique, Lancome und YSL sind bereits im Geschäft.

8.
Apple und Microsoft verbessern ständig ihre neuronalen Siri und Contana. Im Moment führen sie nur unsere Befehle aus, aber in naher Zukunft werden sie die Initiative ergreifen: Empfehlungen geben und unsere Wünsche antizipieren.
Was erwartet uns in Zukunft noch?
Selbstlernende neuronale Netze können den Menschen ersetzen: Den Anfang machen Texter und Korrektoren. Roboter erstellen bereits Texte mit Bedeutung und ohne Fehler. Und sie tun es viel schneller als Menschen. Sie werden weiterhin mit Callcenter-Mitarbeitern, technischem Support, Moderatoren und Administratoren öffentlicher Seiten in sozialen Netzwerken beschäftigt sein. Neuronale Netze können bereits ein Skript lernen und es per Sprache wiedergeben. Wie sieht es mit anderen Bereichen aus?
Agrarsektor
Das neuronale Netzwerk wird in spezielle Geräte implementiert. Erntemaschinen steuern automatisch, scannen Pflanzen, untersuchen den Boden und übertragen Daten an ein neuronales Netzwerk. Sie entscheidet, ob gegossen, gedüngt oder gegen Schädlinge gespritzt wird. Anstelle von ein paar Dutzend Arbeitern benötigen Sie höchstens zwei Spezialisten: einen Vorgesetzten und einen technischen.
Medizin
Microsoft arbeitet derzeit aktiv an der Entwicklung eines Heilmittels gegen Krebs. Wissenschaftler beschäftigen sich mit Bioprogrammierung – sie versuchen, den Prozess der Entstehung und Entwicklung von Tumoren zu digitalisieren. Wenn alles klappt, werden Programmierer einen Weg finden, einen solchen Prozess zu blockieren, und durch Analogie wird ein Medikament geschaffen.
Marketing
Marketing ist hochgradig personalisiert. Schon jetzt können neuronale Netze in Sekundenschnelle bestimmen, welche Inhalte welchem Nutzer zu welchem Preis angezeigt werden sollen. Künftig wird die Beteiligung des Vermarkters am Prozess auf ein Minimum reduziert: Neuronale Netze werden Anfragen anhand von Daten zum Nutzerverhalten vorhersagen, den Markt scannen und die am besten geeigneten Angebote bereitstellen, wenn eine Person über den Kauf nachdenkt.
E-Commerce
E-Commerce wird überall implementiert. Sie müssen nicht mehr über einen Link zum Online-Shop gehen: Sie können mit einem Klick alles dort kaufen, wo Sie es sehen. Sie lesen diesen Artikel beispielsweise einige Jahre später. Der Lippenstift im Screenshot aus der MakeUp Plus-Anwendung gefällt dir wirklich gut (siehe oben). Du klickst darauf und gelangst direkt zum Warenkorb. Oder schauen Sie sich ein Video über das neueste Modell der Hololens (Mixed-Reality-Brille) an und geben Sie sofort eine Bestellung direkt auf YouTube auf.
In fast allen Bereichen werden Spezialisten mit Kenntnissen oder zumindest Verständnis für die Struktur neuronaler Netze, maschinellem Lernen und Systemen der künstlichen Intelligenz geschätzt. Wir werden Seite an Seite mit Robotern existieren. Und je mehr wir über sie wissen, desto ruhiger wird unser Leben.
P.S. Zinaida Falls ist ein neuronales Yandex-Netzwerk, das Gedichte schreibt. Bewerten Sie die Arbeit, die die Maschine geschrieben hat, nachdem sie von Mayakovsky trainiert wurde (Rechtschreibung und Zeichensetzung erhalten geblieben):
« Das»
Das
einfach alles
etwas
in der Zukunft
und Macht
diese Person
ist alles auf der Welt oder nicht
Überall ist Blut
miteinander umgehen
dick werden
Ruhm zu
Land
mit einem Knall im Schnabel
Beeindruckend, oder?
Guten Tag, mein Name ist Natalia Efremova und ich bin wissenschaftliche Mitarbeiterin bei NtechLab. Heute werde ich über die Arten neuronaler Netze und ihre Anwendungen sprechen.
Zunächst möchte ich ein paar Worte zu unserem Unternehmen sagen. Das Unternehmen ist neu, vielleicht wissen viele von Ihnen noch nicht, was wir tun. Letztes Jahr haben wir den MegaFace-Wettbewerb gewonnen. Dies ist ein internationaler Gesichtserkennungswettbewerb. Im selben Jahr wurde unser Unternehmen eröffnet, das heißt, wir sind seit etwa einem Jahr, sogar noch etwas länger, auf dem Markt. Dementsprechend sind wir eines der führenden Unternehmen in der Gesichtserkennung und biometrischen Bildverarbeitung.
Der erste Teil meines Berichts richtet sich an diejenigen, die mit neuronalen Netzen nicht vertraut sind. Ich bin direkt am Deep Learning beteiligt. Ich arbeite seit mehr als 10 Jahren in diesem Bereich. Obwohl es vor etwas weniger als einem Jahrzehnt erschien, gab es früher einige Grundlagen neuronaler Netze, die dem Deep-Learning-System ähnelten.
In den letzten 10 Jahren haben sich Deep Learning und Computer Vision rasant weiterentwickelt. Alles, was in diesem Bereich von Bedeutung ist, ist in den letzten 6 Jahren geschehen.
Ich werde über praktische Aspekte sprechen: wo, wann, was im Hinblick auf Deep Learning für die Bild- und Videoverarbeitung, für die Bild- und Gesichtserkennung einzusetzen ist, da ich in einem Unternehmen arbeite, das dies tut. Ich erzähle Ihnen ein wenig über Emotionserkennung und welche Ansätze in Spielen und Robotik verwendet werden. Ich werde auch über die nicht standardmäßige Anwendung von Deep Learning sprechen, etwas, das gerade erst in wissenschaftlichen Institutionen auftaucht und in der Praxis noch wenig genutzt wird, wie es angewendet werden kann und warum es schwierig ist, es anzuwenden.
Der Bericht wird aus zwei Teilen bestehen. Da die meisten mit neuronalen Netzen vertraut sind, werde ich zunächst kurz darauf eingehen, wie neuronale Netze funktionieren, was biologische neuronale Netze sind, warum es für uns wichtig ist zu wissen, wie sie funktionieren, was künstliche neuronale Netze sind und welche Architekturen in welchen Bereichen verwendet werden .
Ich entschuldige mich sofort, ich überspringe ein wenig die englische Terminologie, da ich das meiste, was auf Russisch heißt, nicht einmal weiß. Vielleicht auch Sie.
Daher wird der erste Teil des Berichts den Faltungs-Neuronalen Netzen gewidmet sein. Wie Convolutional Neural Networks (CNN) und Bilderkennung funktionieren, erkläre ich Ihnen anhand eines Beispiels aus der Gesichtserkennung. Ich erzähle Ihnen ein wenig über rekurrente neuronale Netze (RNN) und Reinforcement Learning am Beispiel von Deep-Learning-Systemen.
Als nicht standardmäßige Anwendung neuronaler Netze werde ich darüber sprechen, wie CNN in der Medizin funktioniert, um Voxelbilder zu erkennen, und wie neuronale Netze verwendet werden, um Armut in Afrika zu erkennen.
Was sind neuronale Netze?
Der Prototyp für die Schaffung neuronaler Netze waren seltsamerweise biologische neuronale Netze. Viele von Ihnen wissen vielleicht, wie man ein neuronales Netzwerk programmiert, aber ich glaube, einige wissen nicht, woher es kommt. Zwei Drittel aller Sinnesinformationen, die zu uns gelangen, stammen von den visuellen Wahrnehmungsorganen. Mehr als ein Drittel der Oberfläche unseres Gehirns wird von den beiden wichtigsten Sehbahnen eingenommen – der dorsalen Sehbahn und der ventralen Sehbahn.Die dorsale Sehbahn beginnt in der primären Sehzone, an unserem Scheitel, und setzt sich nach oben fort, während die ventrale Bahn am Hinterkopf beginnt und etwa hinter den Ohren endet. Die gesamte wichtige Mustererkennung, die in uns stattfindet, alles, was uns bewusst ist und eine Bedeutung hat, findet genau dort statt, hinter den Ohren.
Warum ist das wichtig? Denn oft ist es notwendig, neuronale Netze zu verstehen. Erstens reden alle darüber, und ich bin es schon gewohnt, dass so etwas passiert, und zweitens ist es eine Tatsache, dass alle Bereiche, die in neuronalen Netzen zur Bilderkennung verwendet werden, genau aus der ventralen Sehbahn zu uns kamen, wo jeweils ein kleiner Zone ist für ihre streng definierte Funktion verantwortlich.
Das Bild kommt von der Netzhaut zu uns, durchläuft eine Reihe von Sehzonen und endet in der Schläfenzone.
In den fernen 60er Jahren des letzten Jahrhunderts, als die Erforschung der visuellen Bereiche des Gehirns gerade erst begann, wurden die ersten Experimente an Tieren durchgeführt, da es kein fMRT gab. Das Gehirn wurde mithilfe von Elektroden untersucht, die in verschiedene Sehbereiche implantiert wurden.
Der erste visuelle Bereich wurde 1962 von David Hubel und Torsten Wiesel untersucht. Sie führten Experimente an Katzen durch. Den Katzen wurden verschiedene bewegliche Objekte gezeigt. Die Gehirnzellen reagierten auf den Reiz, den das Tier erkannte. Auch heute noch werden viele Experimente auf diese drakonische Weise durchgeführt. Dennoch ist dies der effektivste Weg, um herauszufinden, was jede kleine Zelle in unserem Gehirn tut.
Auf die gleiche Weise wurden viele weitere wichtige Eigenschaften der visuellen Bereiche entdeckt, die wir jetzt im Deep Learning nutzen. Eine der wichtigsten Eigenschaften ist die Vergrößerung der rezeptiven Felder unserer Zellen, wenn wir uns von den primären Sehbereichen zu den Schläfenlappen, also den späteren Sehbereichen, bewegen. Das Empfangsfeld ist der Teil des Bildes, den jede Zelle unseres Gehirns verarbeitet. Jede Zelle hat ihr eigenes Empfangsfeld. Die gleiche Eigenschaft bleibt in neuronalen Netzen erhalten, wie Sie wahrscheinlich alle wissen.
Mit zunehmenden rezeptiven Feldern nehmen auch die komplexen Reize zu, die neuronale Netze normalerweise erkennen.

Hier sehen Sie Beispiele für die Komplexität von Reizen, die verschiedenen zweidimensionalen Formen, die in den Bereichen V2, V4 und verschiedenen Teilen der Schläfenfelder bei Makakenaffen erkannt werden. Darüber hinaus werden mehrere MRT-Experimente durchgeführt.

Hier können Sie sehen, wie solche Experimente durchgeführt werden. Dies ist ein 1-Nanometer-Teil der IT-Kortexzonen des Affen, wenn verschiedene Objekte erkannt werden.
Fassen wir es zusammen. Eine wichtige Eigenschaft, die wir von den visuellen Bereichen übernehmen wollen, ist, dass die Größe der rezeptiven Felder zunimmt und die Komplexität der Objekte, die wir erkennen, zunimmt.
Computer Vision
Bevor wir lernten, dies auf Computer Vision anzuwenden, existierte es im Allgemeinen nicht als solches. Auf jeden Fall hat es nicht so gut funktioniert wie jetzt.Wir übertragen all diese Eigenschaften auf das neuronale Netzwerk, und jetzt funktioniert es, wenn man nicht einen kleinen Exkurs zu den Datensätzen einbaut, auf den ich später noch eingehen werde.
Aber zuerst ein wenig über das einfachste Perzeptron. Es wird auch im Bild und Abbild unseres Gehirns geformt. Das einfachste Element, das einer Gehirnzelle ähnelt, ist ein Neuron. Verfügt über Eingabeelemente, die standardmäßig von links nach rechts und gelegentlich von unten nach oben angeordnet sind. Links sind die Eingabeteile des Neurons, rechts die Ausgabeteile des Neurons.
Das einfachste Perzeptron kann nur die einfachsten Operationen ausführen. Um komplexere Berechnungen durchführen zu können, benötigen wir eine Struktur mit mehr verborgenen Schichten.

Im Fall von Computer Vision brauchen wir noch mehr verborgene Schichten. Und nur dann wird das System sinnvoll erkennen, was es sieht.
Was bei der Bilderkennung passiert, erkläre ich Ihnen am Beispiel von Gesichtern.
Für uns ist es ganz einfach, dieses Bild zu betrachten und zu sagen, dass es genau das Gesicht der Statue zeigt. Vor 2010 war dies jedoch eine unglaublich schwierige Aufgabe für Computer Vision. Wer sich schon einmal mit diesem Thema beschäftigt hat, weiß wahrscheinlich, wie schwierig es war, den Gegenstand, den wir auf dem Bild finden wollen, ohne Worte zu beschreiben.
Wir mussten dies auf geometrische Weise tun, das Objekt beschreiben, die Beziehungen des Objekts beschreiben, wie diese Teile zueinander in Beziehung stehen können, dann dieses Bild auf dem Objekt finden, sie vergleichen und das bekommen, was wir schlecht erkannt haben. Normalerweise war es etwas besser, als eine Münze zu werfen. Etwas besser als das Zufallsniveau.
So funktioniert es jetzt nicht. Wir unterteilen unser Bild entweder in Pixel oder in bestimmte Patches: 2x2, 3x3, 5x5, 11x11 Pixel – wie es für die Ersteller des Systems praktisch ist, in dem sie als Eingabeschicht für das neuronale Netzwerk dienen.
Signale von diesen Eingabeschichten werden über Synapsen von Schicht zu Schicht übertragen, wobei jede Schicht ihre eigenen spezifischen Koeffizienten hat. Also gehen wir von Schicht zu Schicht, von Schicht zu Schicht, bis wir feststellen, dass wir das Gesicht erkannt haben.
Herkömmlicherweise können alle diese Teile in drei Klassen unterteilt werden. Wir bezeichnen sie mit X, W und Y, wobei X unser Eingabebild ist, Y ein Satz von Beschriftungen ist und wir unsere Gewichte ermitteln müssen. Wie berechnen wir W?
Angesichts unseres X und Y scheint dies einfach zu sein. Was jedoch mit einem Sternchen gekennzeichnet ist, ist eine sehr komplexe nichtlineare Operation, die leider keine Umkehrung hat. Selbst mit zwei gegebenen Komponenten der Gleichung ist es sehr schwierig, sie zu berechnen. Daher müssen wir schrittweise durch Ausprobieren und Auswählen des Gewichts W sicherstellen, dass der Fehler so weit wie möglich abnimmt, vorzugsweise so, dass er gleich Null wird.

Dieser Prozess erfolgt iterativ, wir reduzieren ständig, bis wir den Wert des Gewichts W finden, der ausreichend zu uns passt.
Übrigens hat kein einziges neuronales Netzwerk, mit dem ich gearbeitet habe, einen Fehler von Null erreicht, aber es hat ganz gut funktioniert.

Dies ist das erste Netzwerk, das 2012 den internationalen ImageNet-Wettbewerb gewann. Dies ist das sogenannte AlexNet. Dies ist das Netzwerk, das erstmals erklärt hat, dass Faltungs-Neuronale Netze existieren, und seitdem haben Faltungs-Neuronale Netze ihre Positionen in allen internationalen Wettbewerben nie aufgegeben.
Obwohl dieses Netzwerk recht klein ist (es hat nur 7 verborgene Schichten), enthält es 650.000 Neuronen mit 60 Millionen Parametern. Um iterativ zu lernen, die notwendigen Gewichte zu finden, benötigen wir viele Beispiele.
Das neuronale Netz lernt am Beispiel eines Bildes und einer Beschriftung. So wie uns in der Kindheit beigebracht wurde: „Das ist eine Katze und das ist ein Hund“, werden neuronale Netze anhand einer Vielzahl von Bildern trainiert. Tatsache ist jedoch, dass es bis 2010 keinen ausreichend großen Datensatz gab, der eine solche Anzahl von Parametern zum Erkennen von Bildern lehren könnte.
Die größten Datenbanken, die es vor dieser Zeit gab, waren PASCAL VOC, das nur 20 Objektkategorien hatte, und Caltech 101, das am California Institute of Technology entwickelt wurde. Die letzte hatte 101 Kategorien, und das war eine ganze Menge. Diejenigen, die ihre Objekte in keiner dieser Datenbanken finden konnten, mussten ihre Datenbanken aufladen, was, wie ich sagen werde, furchtbar schmerzhaft ist.
Im Jahr 2010 erschien jedoch die ImageNet-Datenbank, die 15 Millionen Bilder enthielt, aufgeteilt in 22.000 Kategorien. Dies löste unser Problem, neuronale Netze zu trainieren. Jetzt kann jeder, der eine akademische Adresse hat, ganz einfach auf die Website der Basis gehen, einen Zugang anfordern und diese Basis zum Training seiner neuronalen Netze erhalten. Sie reagieren meiner Meinung nach recht schnell am nächsten Tag.
Im Vergleich zu früheren Datensätzen handelt es sich um eine sehr große Datenbank.

Das Beispiel zeigt, wie unbedeutend alles war, was davor war. Zeitgleich mit der ImageNet-Basis entstand der ImageNet-Wettbewerb, ein internationaler Wettbewerb, an dem alle teilnehmenden Teams teilnehmen können.
Dieses Jahr wurde das Gewinnernetzwerk in China erstellt und hatte 269 Schichten. Ich weiß nicht, wie viele Parameter es gibt, ich vermute, dass es auch viele sind.
Tiefe neuronale Netzwerkarchitektur
Herkömmlicherweise kann es in zwei Teile unterteilt werden: diejenigen, die studieren, und diejenigen, die nicht studieren.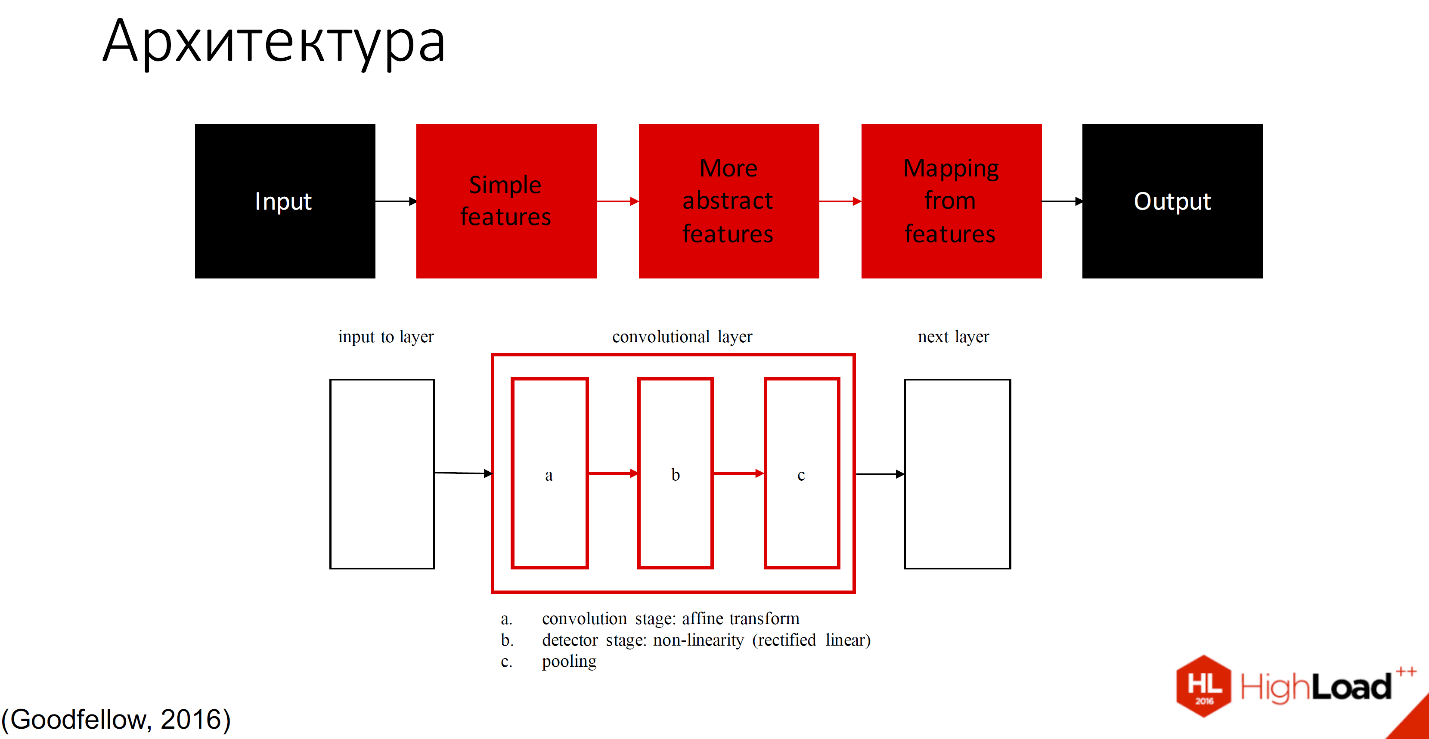
Schwarz zeigt die Teile an, die nicht lernen; alle anderen Schichten sind lernfähig. Es gibt viele Definitionen dafür, was sich in jeder Faltungsschicht befindet. Eine der akzeptierten Bezeichnungen ist, dass eine Schicht mit drei Komponenten in Faltungsstufe, Detektorstufe und Poolingstufe unterteilt ist.
Ich werde nicht auf Details eingehen; es wird noch viele weitere Berichte geben, in denen detailliert erläutert wird, wie dies funktioniert. Ich erzähle es Ihnen anhand eines Beispiels.
Da die Organisatoren mich gebeten hatten, viele Formeln nicht zu erwähnen, habe ich sie komplett verworfen.

Das Eingabebild fällt also in ein Netzwerk von Schichten, die als Filter unterschiedlicher Größe und unterschiedlicher Komplexität der von ihnen erkannten Elemente bezeichnet werden können. Diese Filter bilden einen eigenen Index oder eine Reihe von Merkmalen, die dann in den Klassifikator eingehen. Normalerweise ist dies entweder SVM oder MLP – mehrschichtiges Perzeptron, je nachdem, was für Sie am bequemsten ist.
Ähnlich wie bei einem biologischen neuronalen Netzwerk werden Objekte unterschiedlicher Komplexität erkannt. Mit zunehmender Anzahl der Schichten verlor alles die Verbindung zum Kortex, da es im neuronalen Netzwerk nur eine begrenzte Anzahl von Zonen gibt. 269 oder viele, viele Abstraktionszonen, so dass nur eine Zunahme der Komplexität, Anzahl der Elemente und Empfangsfelder aufrechterhalten wird.

Wenn wir uns das Beispiel der Gesichtserkennung ansehen, dann wird unser Empfangsfeld der ersten Schicht klein sein, dann etwas größer, größer usw., bis wir schließlich das gesamte Gesicht erkennen können.

Aus der Sicht dessen, was sich in unseren Filtern befindet, werden zuerst geneigte Stäbchen plus etwas Farbe, dann Teile von Gesichtern und dann ganze Gesichter von jeder Zelle der Ebene erkannt.
Es gibt Leute, die behaupten, dass eine Person immer besser erkennt als ein Netzwerk. Stimmt das?
Im Jahr 2014 beschlossen Wissenschaftler, zu testen, wie gut wir im Vergleich zu neuronalen Netzen erkennen. Sie nahmen die beiden derzeit besten Netzwerke – AlexNet und das Netzwerk von Matthew Ziller und Fergus – und verglichen sie mit der Reaktion verschiedener Bereiche des Gehirns eines Makaken, dem auch beigebracht wurde, einige Objekte zu erkennen. Die Gegenstände stammten aus der Tierwelt, damit der Affe nicht verwirrt wurde, und es wurden Experimente durchgeführt, um herauszufinden, wer sie besser erkennen konnte.
Da es unmöglich ist, vom Affen eine eindeutige Reaktion zu erhalten, wurden ihm Elektroden implantiert und die Reaktion jedes Neurons direkt gemessen.
Es stellte sich heraus, dass Gehirnzellen unter normalen Bedingungen genauso gut reagierten wie das damals hochmoderne Modell, also Matthew Zillers Netzwerk.
Mit zunehmender Geschwindigkeit der Darstellung von Objekten und zunehmender Menge an Rauschen und Objekten im Bild sinken jedoch die Erkennungsgeschwindigkeit und -qualität unseres Gehirns und des Gehirns von Primaten erheblich. Selbst das einfachste Faltungs-Neuronale Netzwerk kann Objekte besser erkennen. Das heißt, offiziell funktionieren neuronale Netze besser als unser Gehirn.
Klassische Probleme Faltungs-Neuronaler Netze
Es gibt tatsächlich nicht viele von ihnen; sie gehören drei Klassen an. Dazu gehören Aufgaben wie Objektidentifikation, semantische Segmentierung, Gesichtserkennung, Erkennung menschlicher Körperteile, semantische Kantenerkennung, Hervorhebung von Aufmerksamkeitsobjekten in einem Bild und Hervorhebung von Oberflächennormalen. Sie lassen sich grob in drei Ebenen einteilen: von den Aufgaben auf der niedrigsten Ebene bis zu den Aufgaben auf der höchsten Ebene.
Schauen wir uns am Beispiel dieses Bildes an, was jede Aufgabe bewirkt.
- Grenzen definieren- Dies ist die Aufgabe der untersten Ebene, für die Faltungs-Neuronale Netze bereits klassisch verwendet werden.
- Bestimmung des Vektors zur Normalen ermöglicht es uns, aus einem zweidimensionalen ein dreidimensionales Bild zu rekonstruieren.
- Auffälligkeit, Identifizierung von Aufmerksamkeitsobjekten- Darauf würde eine Person beim Betrachten dieses Bildes achten.
- Semantische Segmentierung ermöglicht es Ihnen, Objekte entsprechend ihrer Struktur in Klassen einzuteilen, ohne etwas über diese Objekte zu wissen, also noch bevor sie erkannt werden.
- Hervorhebung semantischer Grenzen- Dies ist die Auswahl von Grenzen, die in Klassen unterteilt sind.
- Hervorhebung menschlicher Körperteile.
- Und die höchste Aufgabe ist Erkennung der Objekte selbst, was wir nun am Beispiel der Gesichtserkennung betrachten werden.
Gesichtserkennung
Als Erstes führen wir einen Gesichtsdetektor über das Bild, um ein Gesicht zu finden. Anschließend normalisieren wir das Gesicht, zentrieren es und verarbeiten es in einem neuronalen Netzwerk. Anschließend erhalten wir einen Satz oder Vektor von Merkmalen, die eindeutig sind beschreibt die Merkmale dieses Gesichts.
Dann können wir diesen Merkmalsvektor mit allen Merkmalsvektoren vergleichen, die in unserer Datenbank gespeichert sind, und erhalten einen Verweis auf eine bestimmte Person, auf ihren Namen, auf ihr Profil – alles, was wir in der Datenbank speichern können.
Genau so funktioniert unser FindFace-Produkt – es ist ein kostenloser Dienst, der Sie bei der Suche nach Personenprofilen in der VKontakte-Datenbank unterstützt.
Darüber hinaus verfügen wir über eine API für Unternehmen, die unsere Produkte ausprobieren möchten. Wir bieten Dienste zur Gesichtserkennung, Verifizierung und Benutzeridentifizierung an.
Wir haben nun 2 Szenarien entwickelt. Die erste ist die Identifizierung, die Suche nach einer Person in einer Datenbank. Die zweite Möglichkeit ist die Verifizierung, dabei handelt es sich um einen Vergleich zweier Bilder mit einer gewissen Wahrscheinlichkeit, dass es sich um dieselbe Person handelt. Darüber hinaus entwickeln wir derzeit Emotionserkennung, Bilderkennung auf Video und Liveness-Erkennung – dabei handelt es sich um ein Verständnis dafür, ob die Person vor der Kamera oder ein Foto lebt.
Einige Statistiken. Bei der Identifizierung erreichen wir bei der Durchsuchung von 10.000 Fotos eine Genauigkeit von etwa 95 %, abhängig von der Qualität der Datenbank, und eine Verifizierungsgenauigkeit von 99 %. Und außerdem ist dieser Algorithmus sehr resistent gegen Veränderungen – wir müssen nicht in die Kamera schauen, wir können einige behindernde Objekte haben: Brillen, Sonnenbrillen, einen Bart, eine medizinische Maske. In manchen Fällen können wir sogar die unglaublichen Herausforderungen für Computer Vision meistern, wie etwa eine Brille und eine Maske.
Sehr schnelle Suche, die Verarbeitung von 1 Milliarde Fotos dauert 0,5 Sekunden. Wir haben einen einzigartigen Schnellsuchindex entwickelt. Wir können auch mit Bildern geringer Qualität arbeiten, die von CCTV-Kameras aufgenommen wurden. Das alles können wir in Echtzeit verarbeiten. Sie können Fotos über die Weboberfläche, über Android, iOS hochladen und 100 Millionen Benutzer und deren 250 Millionen Fotos durchsuchen.
Wie ich bereits sagte, haben wir beim MegaFace-Wettbewerb den ersten Platz belegt – ein Analogon für ImageNet, aber für Gesichtserkennung. Es läuft schon seit mehreren Jahren, letztes Jahr waren wir die Besten unter 100 Teams aus der ganzen Welt, darunter auch Google.
Wiederkehrende neuronale Netze
Wir verwenden wiederkehrende neuronale Netze, wenn es für uns nicht ausreicht, nur ein Bild zu erkennen. In Fällen, in denen es für uns wichtig ist, die Konsistenz aufrechtzuerhalten, benötigen wir die Reihenfolge des Geschehens und verwenden gewöhnliche wiederkehrende neuronale Netze.Dies wird zur Erkennung natürlicher Sprache, zur Videoverarbeitung und sogar zur Bilderkennung verwendet.
Ich werde nicht über die Erkennung natürlicher Sprache sprechen – nach meinem Bericht werden zwei weitere folgen, die auf die Erkennung natürlicher Sprache abzielen. Daher werde ich am Beispiel der Emotionserkennung über die Arbeit wiederkehrender Netzwerke sprechen.
Was sind wiederkehrende neuronale Netze? Dies ist ungefähr das Gleiche wie bei gewöhnlichen neuronalen Netzen, jedoch mit Rückmeldung. Wir benötigen Feedback, um den vorherigen Zustand des Systems an den Eingang des neuronalen Netzwerks oder an einige seiner Schichten zu übertragen.
Nehmen wir an, wir verarbeiten Emotionen. Selbst in einem Lächeln – einer der einfachsten Emotionen – gibt es mehrere Momente: von einem neutralen Gesichtsausdruck bis zu dem Moment, in dem wir ein volles Lächeln haben. Sie folgen einander der Reihe nach. Um dies gut zu verstehen, müssen wir in der Lage sein, zu beobachten, wie dies geschieht, und das, was im vorherigen Frame war, auf den nächsten Schritt des Systems zu übertragen.

Im Jahr 2005 stellte ein Team aus Montreal beim Emotion Recognition in the Wild-Wettbewerb ein wiederkehrendes System speziell zur Erkennung von Emotionen vor, das sehr einfach aussah. Es hatte nur wenige Faltungsschichten und arbeitete ausschließlich mit Video. In diesem Jahr fügten sie außerdem Audioerkennung und aggregierte Frame-by-Frame-Daten hinzu, die aus Faltungs-Neuronalen Netzen gewonnen wurden, sowie Audiosignaldaten mit dem Betrieb eines wiederkehrenden Neuronalen Netzes (mit Zustandsrückgabe) und belegten den ersten Platz im Wettbewerb.
Verstärkungslernen
Der nächste Typ neuronaler Netze, der in letzter Zeit sehr häufig verwendet wird, aber nicht so viel Beachtung gefunden hat wie die beiden vorherigen Typen, ist Deep Reinforcement Learning.Tatsache ist, dass wir in den beiden vorherigen Fällen Datenbanken verwenden. Wir haben entweder Daten von Gesichtern, Daten von Bildern oder Daten mit Emotionen von Videos. Wenn wir das nicht haben, wenn wir es nicht filmen können, wie können wir dann einem Roboter beibringen, Gegenstände aufzuheben? Wir machen das automatisch – wir wissen nicht, wie es funktioniert. Ein weiteres Beispiel: Das Zusammenstellen großer Datenbanken in Computerspielen ist schwierig, und es ist nicht notwendig, es viel einfacher zu machen.
Jeder hat wahrscheinlich vom Erfolg des Deep Reinforcement Learning bei Atari und Go gehört.
Wer hat von Atari gehört? Nun ja, jemand hat es gehört, okay. Ich denke, jeder hat von AlphaGo gehört, daher werde ich Ihnen nicht einmal sagen, was genau dort passiert.

Was ist bei Atari los? Die Architektur dieses neuronalen Netzwerks ist links dargestellt. Sie lernt, indem sie mit sich selbst spielt, um die maximale Belohnung zu erhalten. Die maximale Belohnung ist der schnellstmögliche Ausgang des Spiels mit der höchstmöglichen Punktzahl.
Oben rechts befindet sich die letzte Schicht des neuronalen Netzwerks, die die gesamte Anzahl der Zustände des Systems darstellt, das nur zwei Stunden lang gegen sich selbst spielte. Erwünschte Ergebnisse des Spiels mit der maximalen Belohnung werden in Rot dargestellt, unerwünschte in Blau. Das Netzwerk baut ein bestimmtes Feld auf und bewegt sich durch seine trainierten Schichten zu dem Zustand, den es erreichen möchte.
In der Robotik ist die Situation etwas anders. Warum? Hier haben wir mehrere Schwierigkeiten. Erstens haben wir nicht viele Datenbanken. Zweitens müssen wir drei Systeme gleichzeitig koordinieren: die Wahrnehmung des Roboters, seine Aktionen mit Hilfe von Manipulatoren und sein Gedächtnis – was im vorherigen Schritt getan wurde und wie es getan wurde. Im Allgemeinen ist das alles sehr schwierig.
Tatsache ist, dass derzeit kein einziges neuronales Netzwerk, nicht einmal Deep Learning, diese Aufgabe effektiv genug bewältigen kann, sodass Deep Learning nur ein Teil dessen ist, was Roboter leisten müssen. Sergey Levin hat beispielsweise kürzlich ein System bereitgestellt, das einem Roboter beibringt, Objekte zu greifen.

Hier sind die Experimente, die er an seinen 14 Roboterarmen durchgeführt hat.
Was ist hier los? In diesen Becken, die Sie vor sich sehen, befinden sich verschiedene Gegenstände: Stifte, Radiergummis, kleinere und größere Tassen, Lappen, unterschiedliche Texturen, unterschiedliche Härte. Es ist unklar, wie man einem Roboter beibringen kann, sie einzufangen. Viele Stunden und sogar Wochen lang trainierten die Roboter, diese Objekte zu greifen, und es wurden Datenbanken darüber erstellt.
Datenbanken sind eine Art Umweltreaktion, die wir sammeln müssen, um dem Roboter beibringen zu können, in Zukunft etwas zu tun. Aus diesen Systemzuständen sollen künftig Roboter lernen.
Nicht standardmäßige Anwendungen neuronaler Netze
Leider ist dies das Ende, ich habe nicht mehr viel Zeit. Ich erzähle Ihnen von den nicht standardmäßigen Lösungen, die es derzeit gibt und die vielen Prognosen zufolge in Zukunft Anwendung finden werden.Nun, Stanford-Wissenschaftler haben kürzlich eine sehr ungewöhnliche Anwendung eines neuronalen CNN-Netzwerks zur Vorhersage von Armut entwickelt. Was haben sie gemacht?
Das Konzept ist eigentlich sehr einfach. Tatsache ist, dass in Afrika das Ausmaß der Armut alle vorstellbaren und unvorstellbaren Grenzen überschreitet. Sie haben nicht einmal die Möglichkeit, soziodemografische Daten zu sammeln. Daher liegen uns seit 2005 überhaupt keine Daten darüber vor, was dort passiert.
Wissenschaftler sammelten Tag- und Nachtkarten von Satelliten und speisten sie über einen bestimmten Zeitraum in ein neuronales Netzwerk ein.
Das neuronale Netzwerk wurde auf ImageNet vorkonfiguriert, das heißt, die ersten Filterebenen wurden so konfiguriert, dass es einige sehr einfache Dinge erkennen konnte, zum Beispiel Dächer von Häusern, um auf Tageskarten nach Siedlungen zu suchen verglichen mit Nachtkarten die Ausleuchtung desselben Flächenbereichs, um zu sagen, wie viel Geld die Bevölkerung mindestens für die nächtliche Beleuchtung ihrer Häuser zur Verfügung hat.

Hier sehen Sie die Ergebnisse der vom neuronalen Netzwerk erstellten Prognose. Die Prognose wurde mit unterschiedlichen Auflösungen erstellt. Und Sie sehen – das allerletzte Bild – echte Daten, die 2005 von der ugandischen Regierung gesammelt wurden.
Sie können sehen, dass das neuronale Netzwerk eine ziemlich genaue Vorhersage gemacht hat, selbst mit einer leichten Verschiebung seit 2005.
Natürlich gab es Nebenwirkungen. Wissenschaftler, die sich mit Deep Learning beschäftigen, sind immer wieder überrascht, verschiedene Nebenwirkungen zu entdecken. Zum Beispiel, dass das Netzwerk gelernt hat, Wasser, Wälder, Großbaustellen, Straßen zu erkennen – und das alles ohne Lehrer, ohne vorgefertigte Datenbanken. Im Allgemeinen völlig unabhängig. Es gab bestimmte Schichten, die beispielsweise auf Straßen reagierten.
Und die letzte Anwendung, über die ich sprechen möchte, ist die semantische Segmentierung von 3D-Bildern in der Medizin. Im Allgemeinen ist die medizinische Bildgebung ein komplexer Bereich, der nur sehr schwer zu bearbeiten ist.
Dafür gibt es mehrere Gründe.
- Wir haben nur sehr wenige Datenbanken. Es ist nicht so einfach, ein Bild eines Gehirns zu finden, noch dazu eines beschädigten, und es ist auch unmöglich, es von irgendwoher zu machen.
- Selbst wenn wir ein solches Bild haben, müssen wir einen Arzt hinzuziehen und ihn zwingen, alle mehrschichtigen Bilder manuell zu platzieren, was sehr zeitaufwändig und äußerst ineffizient ist. Nicht alle Ärzte verfügen über die Ressourcen, dies zu tun.
- Es ist eine sehr hohe Präzision erforderlich. Das medizinische System kann keine Fehler machen. Beim Erkennen wurden beispielsweise Katzen nicht erkannt – keine große Sache. Und wenn wir den Tumor nicht erkannt haben, dann ist das nicht mehr so gut. Die Anforderungen an die Systemzuverlässigkeit sind hier besonders hoch.
- Bilder bestehen aus dreidimensionalen Elementen – Voxeln, nicht Pixeln, was für Systementwickler zusätzliche Komplexität mit sich bringt.
Einsatzgebiete: Erkennung von Schäden nach einem Aufprall, Suche nach einem Tumor im Gehirn, in der Kardiologie zur Bestimmung der Herzfunktion.

Hier ist ein Beispiel zur Bestimmung des Plazentavolumens.
Automatisch funktioniert es gut, aber nicht gut genug, um in die Produktion freigegeben zu werden, also fängt es gerade erst an. Es gibt mehrere Startups, die solche medizinischen Bildverarbeitungssysteme entwickeln. Generell wird es in naher Zukunft viele Startups im Bereich Deep Learning geben. Sie sagen, dass Risikokapitalgeber in den letzten sechs Monaten mehr Budget für Deep-Learning-Startups bereitgestellt haben als in den letzten fünf Jahren.
Dieser Bereich entwickelt sich aktiv, es gibt viele interessante Richtungen. Wir leben in interessanten Zeiten. Wenn Sie sich mit Deep Learning beschäftigen, ist es wahrscheinlich an der Zeit, Ihr eigenes Startup zu gründen.
Nun, ich werde es wahrscheinlich hier zusammenfassen. Vielen Dank.
Beginnen wir unsere Betrachtung des Materials mit der Einführung und Definition des eigentlichen Konzepts eines künstlichen neuronalen Systems.
kann als analoges Computersystem betrachtet werden, das einfache Datenverarbeitungselemente verwendet, die größtenteils parallel miteinander verbunden sind. Datenverarbeitungselemente führen sehr einfache logische oder arithmetische Operationen an ihren Eingabedaten durch. Die Grundlage für die Funktionsweise eines künstlichen neuronalen Systems besteht darin, dass jedem Element eines solchen Systems Gewichtskoeffizienten zugeordnet sind. Diese Gewichte stellen die im System gespeicherten Informationen dar.Diagramm eines typischen künstlichen Neurons
Ein Neuron kann viele Eingänge, aber nur einen Ausgang haben. Das menschliche Gehirn enthält ungefähr Neuronen, und jedes Neuron kann Tausende von Verbindungen zu anderen haben. Die Eingangssignale des Neurons werden mit Gewichtungskoeffizienten multipliziert und addiert, um den Gesamteingang des Neurons zu erhalten – ICH: Reis. 1. Typisches künstliches Neuron Die Funktion, die den Ausgang eines Neurons mit seinen Eingängen verbindet, wird Aktivierungsfunktion genannt. Es hat die Form einer Sigmoidfunktion θ
. Die Formalisierung der Neuronenantwort besteht darin, dass das ursprüngliche Signal beim Empfang sehr kleiner und sehr großer Eingangssignale an eine der Grenzen gesendet wird. Darüber hinaus ist jedem Neuron ein Schwellenwert zugeordnet – θ
, der in der Formel zur Berechnung des Ausgangssignals vom gesamten Eingangssignal subtrahiert wird. Infolgedessen wird das Ausgangssignal eines Neurons – O oft wie folgt beschrieben: Backpropagation-Netzwerkstruktur“ src="https://libtime.ru/uploads/images/00/00/01/2014/06/27/set -s- obratnym-rasprostraneniyem.png" alt="Backpropagation-Netzwerkstruktur" width="450" height="370">
Рис. 2. Сеть с обратным распространением
!} Backpropagation-Netzwerk gliedert sich in der Regel in drei Segmente, es können aber auch weitere Segmente gebildet werden. Die zwischen den Eingabe- und Ausgabesegmenten liegenden Segmente (Segmente) werden als versteckte Segmente bezeichnet, da nur die Eingabe- und Ausgabesegmente von der Außenwelt visuell wahrgenommen werden. Ein Netzwerk, das den Wert einer logischen XOR-Operation auswertet, erzeugt nur dann eine wahre Ausgabe, wenn nicht alle seine Eingaben wahr oder nicht alle seine Eingaben falsch sind. Die Anzahl der Knoten in einem verborgenen Sektor kann je nach Zweck des Projekts variieren.
Reis. 1. Typisches künstliches Neuron Die Funktion, die den Ausgang eines Neurons mit seinen Eingängen verbindet, wird Aktivierungsfunktion genannt. Es hat die Form einer Sigmoidfunktion θ
. Die Formalisierung der Neuronenantwort besteht darin, dass das ursprüngliche Signal beim Empfang sehr kleiner und sehr großer Eingangssignale an eine der Grenzen gesendet wird. Darüber hinaus ist jedem Neuron ein Schwellenwert zugeordnet – θ
, der in der Formel zur Berechnung des Ausgangssignals vom gesamten Eingangssignal subtrahiert wird. Infolgedessen wird das Ausgangssignal eines Neurons – O oft wie folgt beschrieben: Backpropagation-Netzwerkstruktur“ src="https://libtime.ru/uploads/images/00/00/01/2014/06/27/set -s- obratnym-rasprostraneniyem.png" alt="Backpropagation-Netzwerkstruktur" width="450" height="370">
Рис. 2. Сеть с обратным распространением
!} Backpropagation-Netzwerk gliedert sich in der Regel in drei Segmente, es können aber auch weitere Segmente gebildet werden. Die zwischen den Eingabe- und Ausgabesegmenten liegenden Segmente (Segmente) werden als versteckte Segmente bezeichnet, da nur die Eingabe- und Ausgabesegmente von der Außenwelt visuell wahrgenommen werden. Ein Netzwerk, das den Wert einer logischen XOR-Operation auswertet, erzeugt nur dann eine wahre Ausgabe, wenn nicht alle seine Eingaben wahr oder nicht alle seine Eingaben falsch sind. Die Anzahl der Knoten in einem verborgenen Sektor kann je nach Zweck des Projekts variieren. Eigenschaften neuronaler Netze
Es ist zu beachten, dass neuronale Netze keine Programmierung im üblichen Sinne des Wortes erfordern. Um neuronale Netze zu trainieren, werden spezielle Trainingsalgorithmen für neuronale Netze verwendet, wie z. B. Counterpropagation und Backpropagation. Der Programmierer „programmiert“ das Netzwerk, indem er Eingaben und entsprechende Ausgaben festlegt. Das Netzwerk lernt, indem es Gewichte für synaptische Verbindungen zwischen Neuronen automatisch anpasst. Die Gewichtungskoeffizienten bestimmen zusammen mit den Schwellenwerten der Neuronen die Art der Datenverteilung im Netzwerk und stellen so die richtige Reaktion auf die im Trainingsprozess verwendeten Daten ein. Das Netzwerk zu trainieren, um die richtigen Antworten zu erhalten, kann zeitaufwändig sein. Wie viel hängt davon ab, wie viele Bilder während des Netzwerktrainings gelernt werden müssen, sowie von den Fähigkeiten der verwendeten Hardware und unterstützenden Software. Sobald das Training jedoch abgeschlossen ist, ist das Netzwerk in der Lage, Antworten in hoher Geschwindigkeit bereitzustellen. Auf seine Art Architektur künstliches neuronales System unterscheidet sich von anderen Computersystemen. In einem klassischen Informationssystem wird die Fähigkeit realisiert, diskrete Informationen mit Speicherelementen zu verbinden. Beispielsweise speichert ein Informationssystem normalerweise Daten über ein bestimmtes Objekt in einer Gruppe benachbarter Speicherelemente. Folglich wird die Fähigkeit, auf Daten zuzugreifen und diese zu manipulieren, durch die Schaffung einer Eins-zu-Eins-Beziehung zwischen den Attributen eines Objekts und den Adressen der Speicherzellen, in denen sie gespeichert sind, erreicht. Im Gegensatz zu solchen Systemen werden Modelle künstlicher neuronaler Systeme auf der Grundlage moderner Theorien der Gehirnfunktion entwickelt, nach denen Informationen mithilfe von Gewichten im Gehirn dargestellt werden. Es besteht jedoch keine direkte Korrelation zwischen einem bestimmten Wert des Gewichtungskoeffizienten und einem bestimmten Element der gespeicherten Informationen. Diese verteilte Darstellung von Informationen ähnelt der in Hologrammen verwendeten Bildspeicher- und Präsentationstechnologie. Bei dieser Technologie wirken die Linien des Hologramms wie Beugungsgitter. Mit ihrer Hilfe wird beim Durchtritt eines Laserstrahls das gespeicherte Bild reproduziert, die Daten selbst jedoch nicht direkt interpretiert. Neuronales Netzwerk als Mittel zur Lösung eines Problems. Neuronales Netzwerk fungiert als akzeptables Mittel zur Lösung eines Problems, wenn eine große Menge empirischer Daten vorliegt, aber kein Algorithmus vorhanden ist, der in der erforderlichen Geschwindigkeit eine ausreichend genaue Lösung liefern könnte. In diesem Zusammenhang hat die Technologie der Darstellung von Daten aus einem künstlichen neuronalen System erhebliche Vorteile gegenüber anderen Informationstechnologien. Diese Vorteile lässt sich wie folgt formulieren:
Neuronales Netzwerk als Mittel zur Lösung eines Problems. Neuronales Netzwerk fungiert als akzeptables Mittel zur Lösung eines Problems, wenn eine große Menge empirischer Daten vorliegt, aber kein Algorithmus vorhanden ist, der in der erforderlichen Geschwindigkeit eine ausreichend genaue Lösung liefern könnte. In diesem Zusammenhang hat die Technologie der Darstellung von Daten aus einem künstlichen neuronalen System erhebliche Vorteile gegenüber anderen Informationstechnologien. Diese Vorteile lässt sich wie folgt formulieren: - Der neuronale Netzwerkspeicher ist fehlertolerant. Bei der Entfernung einzelner Teile des neuronalen Netzes kommt es lediglich zu einer Verschlechterung der Informationsqualität, nicht jedoch zu deren vollständigem Verschwinden. Dies liegt daran, dass die Informationen in verteilter Form gespeichert werden.
- Die Qualität der Informationen im neuronalen Netzwerk, die einer Reduzierung unterliegen, nimmt proportional zum entfernten Teil des Netzwerks allmählich ab. Es gibt keinen katastrophalen Informationsverlust.
- Daten in einem neuronalen Netzwerk werden auf natürliche Weise mithilfe des assoziativen Gedächtnisses gespeichert. Assoziatives Gedächtnis ist ein Gedächtnis, in dem es ausreicht, nach teilweise präsentierten Daten zu suchen, um alle Informationen vollständig wiederherzustellen. Dies ist der Unterschied zwischen assoziativem Speicher und gewöhnlichem Speicher, bei dem Daten durch Angabe der genauen Adresse der entsprechenden Speicherelemente erhalten werden.
- ermöglichen Ihnen die Durchführung von Extrapolationen und Interpolationen auf der Grundlage der darin gespeicherten Informationen. Das heißt, durch Training können Sie dem Netzwerk die Möglichkeit geben, in den Daten nach wichtigen Merkmalen oder Beziehungen zu suchen. Das Netzwerk ist dann in der Lage, Zusammenhänge in den neu empfangenen Daten zu extrapolieren und zu identifizieren. Beispielsweise wurde in einem Experiment ein neuronales Netzwerk anhand eines hypothetischen Beispiels trainiert. Nach Abschluss der Schulung erlangte das Netzwerk die Fähigkeit, Fragen, für die keine Schulung angeboten wurde, richtig zu beantworten.
- Neuronale Netze sind plastisch. Selbst nach dem Entfernen einer bestimmten Anzahl von Neuronen kann das Netzwerk auf seine primäre Ebene umtrainiert werden (natürlich nur, wenn noch genügend Neuronen darin vorhanden sind). Dieses Merkmal ist auch charakteristisch für das menschliche Gehirn, bei dem zwar einzelne Teile geschädigt sein können, aber im Laufe der Zeit mit Hilfe des Trainings ein primäres Maß an Fähigkeiten und Wissen erreicht wird.