В началото на всеки семестър се събират студенти от магистърската програма на катедрата на МиИТ на Академичния университет (Санкт Петербург) и представители на партньорски компании. Представителите говорят за проекти, по които да работят, а учениците ги избират.
В един от проектите, направени в Parallels Labs, нашият студент проучи възможността за внедряване на виртуален хардуерен модул за сигурност (HSM). В резултат на това той добави внедряването на VHSM към проекта OpenVZ с отворен код. Прочетете повече за неговото решение под разреза.
Какво е HSM
Нека си представим приложение, което подписва данни, изпратени до сървъра, използвайки частен ключ. Нека загубата на този ключ е неприемлива за собственика му. Как да защитим такъв ценен ключ от изтичане в резултат на дистанционно хакване на системата? Подходът на HSM предполага, че изобщо не трябва да даваме на уязвимата част от системата достъп до съдържанието на ключа. HSM е физическо устройство, което само съхранява цифрови ключове или други секретни данни, управлява ги, генерира ги и също така извършва криптографски операции, използвайки ги. Всички операции с данни се извършват вътре в HSM и потребителят има достъп само до резултатите от тези операции. Вътрешната памет на устройството е защитена от физически достъп и хакване. При опит за проникване всички чувствителни данни се унищожават.За да започне да използва HSM, потребителят трябва да се удостовери. Ако удостоверяването се извършва чрез клиентско приложение на HSM, работещо в уязвима част на системата, тогава е възможно нападател да прихване паролата на HSM. Прихваната парола ще позволи на атакуващия да използва HSM, без да получи секретните данни, съхранявани в него. Поради това е препоръчително да се извърши удостоверяване чрез заобикаляне на уязвимата част на системата, например чрез физическо въвеждане на ПИН.
Основната пречка пред използването на HSM е високата им цена. В зависимост от класа на устройството, цената може да варира от $10 (USB токени, смарт карти) до $30 000+ (устройства с хардуерно криптографско ускорение, защита от хакване, функции за висока наличност). Доставчиците на облачни решения не са пренебрегнали пазара на HSM. Например Amazon продава своя облачен HSM на средна цена от $1373 на месец.
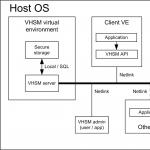
Една от основните характеристики на HSM е изолирането на уязвимата част от системата, която използва криптографски услуги от HSM, който изпълнява тези услуги. Обърнете внимание, че отделните екземпляри (виртуални машини, контейнери и т.н.) в облака са изолирани един от друг, така че ако преместим функциите на HSM извън уязвимия екземпляр в друг, изолиран от външния свят, ще възпроизведем доста точно функционалността на физическият HSM. Ние наричаме този подход виртуален HSM (VHSM). Нека да разгледаме как е реализиран от нашия студент за проекта OpenVZ.
Какво е OpenVZ
OpenVZ е една от технологиите за стартиране на множество изолирани Linux операционни системи на едно Linux ядро. В същото време те казват, че всяка Linux OS работи в отделен контейнер. За да опростим, ядрото на Linux всъщност има вградена функционалност, която позволява приложенията, присвоени на различни контейнери, да бъдат изолирани, така че да не знаят за съществуването на другия. Приложенията не могат да променят своя контейнер. За по-добра изолация и сигурност комуникацията между приложения от различни контейнери, използващи IPC, е забранена. Това обикновено се прави чрез мрежови връзки. В резултат на това виждаме сходството на контейнерите с „обикновените“ виртуални машини. OpenVZ и базираните на него технологии са популярни сред хостинг доставчиците за създаване на VPS. Академичният университет вече е реализирал проекти, свързани с виртуализация на контейнери. Например . Parallels е основният разработчик на OpenVZ. Беше съвсем естествено да внедрим VHSM специално за OpenVZ.Виртуална HSM архитектура

- Client VE е OpenVZ контейнер, в който се изпълняват потребителски приложения, които изискват криптографски услуги, като криптиране, подписване и т.н. Контейнерът е достъпен за отдалечени атаки за кражба на цифрови ключове.
- VHSM виртуална среда (VHSM VE) е OpenVZ контейнер, в който работи VHSM сървърът, демон, който получава команди от приложения в Client VE и ги изпълнява. Няма други приложения, работещи във VHSM VE. VHSM VE е изолиран от обикновените потребителски контейнери с помощта на OpenVZ. Контейнерът няма мрежови интерфейси и не е достъпен през мрежата.
- Transport е модул на ядрото на Linux, предназначен да прехвърля съобщения от Client VE към VHSM VE и обратно.
- VHSM API е библиотека, която внедрява част от стандартния интерфейс PKCS #11 за HSM, предава команди на приложението от ClientVE към VHSM сървъра с помощта на транспорт и връща резултата от командата на приложението в ClientVE.
VHSM виртуална среда
VHSM сървърът е отговорен за удостоверяването на потребителите, взаимодействието със секретното хранилище на данни и извършването на криптографски операции. В допълнение към VHSM сървъра, VHSM VE съдържа Secure Storage, база данни, която съхранява важна информация в криптирана форма. Всеки потребител на VHSM има свой собствен главен ключ, с който данните му се криптират. Главният ключ се генерира от паролата на потребителя с помощта на функцията PBKDF2. Солта, предадена му като вход, се съхранява некриптирана в базата данни. По този начин VHSM не съхранява главния ключ на потребителя в базата данни и използването на PBKDF2 значително намалява скоростта на грубо форсиране на оригиналната парола на потребителя, когато базата данни е открадната.Потребителят се регистрира във VHSM от администратор, чиято роля може да бъде както лице, така и програма. Когато потребител се регистрира, VHSM генерира 256-битов ключ за удостоверяване и го криптира с главен ключ, използвайки AES-GCM. След това, преди да използва VHSM, потребителят се удостоверява с двойка вход-парола. По време на удостоверяване главният ключ, образуван от парола и сол, се използва за дешифриране на ключа за удостоверяване на потребителя. Използването на GCM ви позволява да проверите правилността на главния ключ по време на декриптиране. Главният ключ се получава от паролата на потребителя и следователно проверката на неговата коректност ви позволява да проверите самата парола на потребителя, предадена по време на удостоверяване. След успешно удостоверяване криптографските услуги, използващи цифровите ключове на потребителя, съхранени във VHSM, стават достъпни за потребителя.
VHSM изисква явен избор на контейнери, от които конкретен потребител може да управлява VHSM. Информацията за контейнера, от който е получена потребителската команда, се предоставя от OpenVZ.
VHSM API
Това е C библиотека, разположена в потребителски контейнери и внедрява част от стандартния PKCS#11 интерфейс за HSM, който ви позволява да управлявате ключове, данни, сесии, цифрови подписи, криптиране и т.н. Нека да разгледаме конкретен пример за използване на VHSM API:- Приложението в персонализирания контейнер трябва да подпише съобщението, което изпраща.
- Използвайки VHSM API, приложението генерира двойка публичен-частен ключ, получава ID на частния ключ и публичния ключ.
- Приложението предава съобщението на VHSM API за подписване с частен ключ с необходимия ID. VHSM API връща подписано съобщение.
- Подписаното съобщение и публичният ключ се изпращат до получателя на съобщението. В този случай частният ключ не е достъпен за клиентския контейнер.
VHSM транспорт
Както бе споменато по-горе, приложенията, работещи в различни контейнери, не могат да комуникират помежду си, използвайки Linux IPC механизми. Следователно, за транспортиране на съобщения от клиенти до сървъра и обратно, беше внедрен зареждаем модул на ядрото на Linux. Модулът управлява Netlink сървъра в ядрото и VHSM клиентите и VHSM сървърът се свързват към него. Сървърът Netlink отговаря за предаването на съобщения от източника (VHSM клиент) до дестинацията (VHSM сървър) и обратно. Заедно със съобщенията се добавя идентификаторът на контейнера източник на съобщения, така че например сървърът да може да отхвърля заявки от контейнери, от които на определен потребител е забранено да използва VHSM.Заключение
Основната цел на създаването на VHSM беше да се елиминира възможността за кражба на секретни ключове от паметта на потребителски приложения, работещи в потребителски контейнер. Тази цел беше постигната, защото секретните данни са достъпни само в изолиран контейнер (VHSM VE). Изолацията се изпълнява от OpenVZ.Изтичането на база данни от VHSM VE няма да доведе до незабавна загуба на секретни данни, защото те се съхраняват в криптирана форма. Ключът за криптиране не се съхранява в базата данни, а се генерира от паролата на потребителя, предадена по време на удостоверяване.
Като всяка технология за информационна сигурност, представеното решение е още една бариера пред нападателя и не осигурява пълна защита на информацията.
На английски това означава Uniform Resource Locator, което в превод на руски означава „унифициран локатор на ресурси“. На руски това съкращение обикновено се произнася като „u-er-el“, „yu-ar-el“ или просто „url“. Нека се опитаме да разберем по-подробно какво е URL. Всеки документ (уеб страница) в Интернет има определено местоположение, което може да бъде точно определено. С помощта на URL се посочва точният път до конкретна уеб страница. Точно както посочвате пътя до който и да е файл на вашия компютър, URL адресът се изгражда според конкретен модел, който обикновено изглежда по следния начин:
http://name.ru/papka/document.html
Където http - показва вида на протокола, чрез който се прехвърлят данните, name.ru - означава името на домейна на сайта, papka е папка, а document.html е конкретна страница, към която води този URL.
Тъй като нашият URL адрес http://name.ru/papka/document.html е измислен, даден е само като пример и съответно не води до никаква уеб страница, тогава ако се опитаме да щракнем върху него, ще бъдем отведени до страница, съдържаща информация за грешката. Може да изглежда различно, но определено ще видим надписа „404 не е намерен“. „Не е намерено“ в превод означава „не е намерено“, а появата на страница 404 означава, че URL адресът на уеб страницата е въведен непълно, неправилно (с грешка или печатна грешка) или исканата страница вече не се намира на този адрес, защото е бил изтрит или преименуван
Грешка 404 често възниква, когато щракнете върху връзка, намерена на друга страница и връзката е остаряла. Авторът на сайта може да е преместил необходимия ни документ, да го е преименувал или изтрил. Какво да направите, ако по време на прехода се появи страница 404? Първо проверете дали URL адресът е правилен, ако го знаем. Поправете всички грешки или правописни грешки и опитайте отново. Ако възникне грешка 404, когато следвате връзка към непознат ресурс, трябва да опитате да отидете на главната страница и да използвате търсенето в сайта - възможно е необходимата информация все още да бъде намерена.
Между другото, много разработчици на уебсайтове се грижат страницата 404 на сайта им да не изглежда плашещо безнадеждна. Тук е поставен хумористичен текст със забавна картинка, за да развесели изгубения потребител, както и връзки към основния сайт, лента за търсене или карта на сайта. Ако страницата 404 изглежда недружелюбна и няма връзки, които да следвате, можете да опитате ръчно да съкратите URL адреса, оставяйки само името на сайта - в нашия пример то ще бъде http://name.ru/ и по този начин се опитайте да получите към главната страница на сайта, откъдето можете да отидете на страницата, която търсите.
URL адрес(URL, от английски Uniform Resource Locator) - индекс на разположението на сайта в Интернет. URL адресът съдържа името на домейна и пътя до страницата, включително името на файла на тази страница.
Тим Бърнърс-Лий (член на Европейския съвет за ядрена война в Женева) измисли URL адреса през 1990 г., който по това време беше просто адрес за съхраняване на файлове в системата.
Наред с големите предимства (наличието на интернет навигация), URL адресът на страницата има и недостатък - работи само с латински букви, цифри и някои символи. Ако трябва да използвате например кирилица, тогава URL адресът трябва да бъде прекодиран по специален начин..ru/wiki/%D1%87%D1%82%D0%BE-%D1%82%D0%B0%D0 %BA%D0%BE %D0%B5-url/. Такова кодиране се извършва в две стъпки: първо всеки знак се преобразува в поредица от два байта, след което всеки байт се пренаписва в шестнадесетичен.
Колко означава URL адресът на уебсайт в SEO?
Търсачките вземат предвид появата на ключови фрази в URL адресите. Най-голямо влияние оказват срещанията в адреса на домейна и поддомейните; срещанията в пътя до страницата и името на файла на страницата играят по-малка, но все пак много важна роля. В тази връзка в интернет активно се развива вид печалба, наречен киберсквотинг. Същността му е да се регистрират имена на домейни на пазарна стойност с цел последваща препродажба на завишена цена.
HTTP е протокол за прехвърляне на хипертекст между разпределени системи. Всъщност http е основен елемент на съвременната мрежа. Като уважаващи себе си уеб разработчици трябва да знаем възможно най-много за него.
Нека погледнем този протокол през призмата на нашата професия. В първата част ще разгледаме основите и ще разгледаме заявките/отговорите. В следващата статия ще разгледаме по-подробни функции, като кеширане, обработка на връзката и удостоверяване.
Също така в тази статия ще се позовавам главно на стандарта RFC 2616: Hypertext Transfer Protocol -- HTTP/1.1.
Основи на HTTP
HTTP позволява комуникация между множество хостове и клиенти и поддържа набор от мрежови настройки.
По принцип TCP/IP се използва за комуникация, но това не е единственият възможен вариант. По подразбиране TCP/IP използва порт 80, но могат да се използват и други.
Комуникацията между хоста и клиента се осъществява на два етапа: заявка и отговор. Клиентът генерира HTTP заявка, в отговор на която сървърът предоставя отговор (съобщение). Малко по-късно ще разгледаме тази схема на работа по-подробно.
Текущата версия на HTTP протокола е 1.1, в която са въведени някои нови функции. Според мен най-важните от тях са: поддръжка за постоянно отворена връзка, нов механизъм за пренос на данни, кодиране на пренос на парчета, нови хедъри за кеширане. Ще разгледаме част от това във втората част на тази статия.
URL адрес
Ядрото на уеб комуникацията е заявката, която се изпраща чрез Uniform Resource Locator (URL). Сигурен съм, че вече знаете какво е URL, но за пълнота реших да кажа няколко думи. Структурата на URL адреса е много проста и се състои от следните компоненти:

Протоколът може да бъде http за редовни връзки или https за по-сигурен обмен на данни. Портът по подразбиране е 80. Това е последвано от пътя до ресурса на сървъра и верига от параметри.
Методи
Използвайки URL, ние определяме точното име на хоста, с който искаме да комуникираме, но какво действие трябва да извършим, може да бъде съобщено само чрез HTTP метода. Разбира се, има няколко вида действия, които можем да предприемем. HTTP имплементира най-необходимите, подходящи за нуждите на повечето приложения.
Съществуващи методи:
ВЗЕМЕТЕ: Достъп до съществуващ ресурс. URL адресът изброява цялата необходима информация, така че сървърът да може да намери и върне искания ресурс като отговор.
ПУБЛИКУВАНЕ: Използва се за създаване на нов ресурс. POST заявката обикновено съдържа цялата необходима информация за създаване на нов ресурс.
СЛАГАМ: Актуализирайте текущия ресурс. Заявката PUT съдържа данните, които трябва да бъдат актуализирани.
ИЗТРИЙ: Използва се за изтриване на съществуващ ресурс.
Тези методи са най-популярните и най-често се използват от различни инструменти и рамки. В някои случаи заявките PUT и DELETE се изпращат чрез изпращане на POST, чието съдържание показва действието, което трябва да се извърши върху ресурса: създаване, актуализиране или изтриване.
HTTP поддържа и други методи:
ГЛАВА: Подобно на GET. Разликата е, че при този тип заявка не се предава съобщение. Сървърът получава само заглавките. Използва се например за определяне дали даден ресурс е бил модифициран.
СЛЕДИ: по време на предаване заявката преминава през много точки за достъп и прокси сървъри, всеки от които въвежда своя собствена информация: IP, DNS. Използвайки този метод, можете да видите цялата междинна информация.
НАСТРОИКИ: Използва се за дефиниране на сървърни възможности, настройки и конфигурация за конкретен ресурс.
Статус кодове
В отговор на заявка от клиента, сървърът изпраща отговор, който съдържа и статус код. Този код има специално значение, така че клиентът да може по-ясно да разбере как да интерпретира отговора:
1xx: Информационни съобщения
Набор от тези кодове беше въведен в HTTP/1.1. Сървърът може да изпрати заявка във формата: Expect: 100-continue, което означава, че клиентът все още изпраща останалата част от заявката. Клиентите, изпълняващи HTTP/1.0, игнорират тези заглавки.
2xx: Съобщения за успех
Ако клиентът получи код от серията 2xx, тогава заявката е изпратена успешно. Най-често срещаният вариант е 200 ОК. С GET заявка сървърът изпраща отговор в тялото на съобщението. Има и други възможни отговори:
- 202 Прието: Заявката е приета, но може да не съдържа ресурса в отговора. Това е полезно за асинхронни заявки от страната на сървъра. Сървърът определя дали да изпрати ресурса или не.
- 204 Няма съдържание: Няма съобщение в тялото на отговора.
- 205 Нулиране на съдържанието: Инструктира сървъра да нулира представянето на документа.
- 206 Частично съдържание: Отговорът съдържа само част от съдържанието. Допълнителните заглавки определят общата дължина на съдържанието и друга информация.
3xx: Пренасочване
Един вид съобщение към клиента за необходимостта от предприемане на още едно действие. Най-честият случай на използване е пренасочване на клиента към друг адрес.
- 301 Преместен за постоянно: Ресурсът вече може да бъде намерен на различен URL адрес.
- 303 Вижте други: Ресурсът може временно да бъде намерен на различен URL адрес. Заглавката Location съдържа временен URL адрес.
- 304 Не е променено: Сървърът определя, че ресурсът не е бил модифициран и клиентът трябва да използва кешираната версия на отговора. За проверка на идентичността на информацията се използва ETag (Entity Tag hash);
4xx: Грешки на клиента
Този клас съобщения се използва от сървъра, ако той реши, че заявката е изпратена по погрешка. Най-често срещаният код е 404 Not Found. Това означава, че ресурсът не е намерен на сървъра. Други възможни кодове:
- 400 Лоша заявка: Въпросът е формулиран неправилно.
- 401 Неразрешено: Изисква се удостоверяване, за да направите заявка. Информацията се предава чрез заглавката за оторизация.
- 403 Забранено: Сървърът не позволи достъп до ресурса.
- 405 Методът не е разрешен: Използван е невалиден HTTP метод за достъп до ресурса.
- 409 Конфликт: сървърът не може да обработи напълно заявката, защото се опитва да промени по-нова версия на ресурс. Това често се случва с PUT заявки.
5xx: Сървърни грешки
Поредица от кодове, които се използват за откриване на сървърна грешка при обработка на заявка. Най-често: 500 вътрешна грешка на сървъра. Други възможности:
- 501 Не е изпълнено: Сървърът не поддържа исканата функционалност.
- 503 Услугата не е достъпна: Това може да се случи, ако сървърът има грешка или е претоварен. Обикновено в този случай сървърът не отговаря и времето, дадено за отговор, изтича.
Формати на съобщения за заявка/отговор
На следващото изображение можете да видите схематичен процес на изпращане на заявка от клиента, обработка и изпращане на отговор от сървъра.

Нека да разгледаме структурата на съобщение, предадено чрез HTTP:
Съобщение =
Трябва да има празен ред между заглавката и тялото на съобщението. Може да има няколко заглавия:
Основният текст на отговора може да съдържа цялата или част от информацията, ако съответната функция е активирана (Трансфер-кодиране: на части). HTTP/1.1 също поддържа заглавката Transfer-Encoding.
Общи заглавия
Ето няколко типа заглавки, които се използват както в заявки, така и в отговори:
General-header = Cache-Control | Връзка | Дата | Прагма | Трейлър | Трансфер-кодиране | Надграждане | Чрез | Внимание
Вече разгледахме част от това в тази статия, някои от които ще разгледаме по-подробно във втората част.
Заглавието via се използва в TRACE заявка и се актуализира от всички прокси сървъри.
Заглавието Pragma се използва за изброяване на персонализирани заглавки. Например Pragma: no-cache е същото като Cache-Control: no-cache. Ще говорим повече за това във втора част.
Заглавието Date се използва за съхраняване на датата и часа на заявката/отговора.
Заглавието Upgrade се използва за промяна на протокола.
Transfer-Encoding има за цел да раздели отговора на множество части с помощта на Transfer-Encoding: chunked. Това е нова функция в HTTP/1.1.
Заглавки на обекти
Заглавките на обекта предават мета информация за съдържанието:
Заглавка на обект = Разрешаване | Кодиране на съдържание | Съдържание-Език | Дължина на съдържанието | Съдържание-Местоположение | Съдържание-MD5 | Обхват на съдържание | Тип съдържание | Изтича | Последно модифициран
Всички заглавки с префикс Content- предоставят информация за структурата, кодирането и размера на тялото на съобщението.
Заглавката Expires съдържа времето и датата на изтичане на обекта. Стойността „никога не изтича“ означава време + 1 код от текущия момент. Last-Modified съдържа часа и датата на последната промяна на обекта.
Използвайки тези заглавки, можете да посочите информацията, необходима за вашите задачи.
Формат на заявката
Заявката изглежда по следния начин:
Ред за заявка = Метод SP URI SP HTTP-версия CRLF Метод = "ОПЦИИ" | "ГЛАВА" | "ВЗЕМЕТЕ" | "ПОСТ" | "ПОСТАВЕТЕ" | "ИЗТРИВАНЕ" | "ТРЕЙС"
SP е разделителят между токените. HTTP версията е посочена в HTTP-версия. Действителната заявка изглежда така:
GET /articles/http-basics HTTP/1.1 Хост: www.articles.com Връзка: keep-alive Cache-Control: no-cache Pragma: no-cache Accept: text/html,application/xhtml+xml,application/xml; q=0,9,*/*;q=0,8
Списък с възможни заглавки на заявки:
Заглавка на заявка = Приемам | Accept-Charset | Accept-Encoding | Accept-Language | Упълномощаване | Очаквайте | От | Домакин | Ако съвпадение | If-Modified-Since | Ако-няма съвпадение | Ако диапазон | If-Unmodified-Since | Макс-напред | Прокси-упълномощаване | Обхват | Референт | TE | Потребителски агент
Заглавката Accept указва поддържаните MIME типове, език и кодиране на знаци. Заглавките From, Host, Referer и User-Agent съдържат информация за клиента. If- префиксите са предназначени да създават условия. Ако условието не премине, ще възникне грешка 304 Not Modified.
Формат на отговора
Форматът на отговора се различава само по състоянието и броя на заглавките. Състоянието изглежда така:
Статус-ред = HTTP-версия SP код на състояние SP причина-фраза CRLF
- HTTP версия
- Код на състоянието
- Съобщение за състояние, което може да се чете от човека
Нормалното състояние изглежда така:
HTTP/1.1 200 OK
Заглавките на отговорите могат да бъдат както следва:
Response-header = Приемане на диапазони | Възраст | ETag | Местоположение | Прокси-удостоверяване | Повторен опит-след | Сървър | Променете | WWW-удостоверяване
- Възраст е времето в секунди, когато съобщението е създадено на сървъра.
- ETag MD5 обекти за проверка за промени и модификации на отговора.
- Местоположението се използва за пренасочване и съдържа новия URL адрес.
- Сървърът указва сървъра, където е генериран отговорът.
Мисля, че това е достатъчно теория за днес. Сега нека да разгледаме инструментите, които можем да използваме за наблюдение на HTTP съобщения.
Инструменти за откриване на HTTP трафик
Има много инструменти за наблюдение на HTTP трафик. Ето някои от тях:
Най-често използваните са Chrome Developers Tools:

Ако говорим за дебъгер, можете да използвате Fiddler:

За да наблюдавате HTTP трафика, ще ви трябват curl, tcpdump и tshark.
Библиотеки за работа с HTTP - jQuery AJAX
Тъй като jQuery е толкова популярен, той също има инструменти за обработка на HTTP отговори за AJAX заявки. Информация за jQuery.ajax(настройки) можете да намерите на официалния уебсайт.
Чрез предаване на обект за настройки и използване на функцията за обратно извикване beforeSend, можем да зададем заглавките на заявката с помощта на метода setRequestHeader().
$.ajax(( url: "http://www.articles.com/latest", тип: "GET", beforeSend: функция (jqXHR) ( jqXHR.setRequestHeader("Accepts-Language", "en-US,en "); )))
Ако искате да обработите състоянието на заявката, можете да го направите по следния начин:
$.ajax(( statusCode: ( 404: function() ( alert("страницата не е намерена"); ) ) ));
Долен ред
Ето го, обиколка на основите на HTTP протокола. Втората част ще съдържа още повече интересни факти и примери.
Почти всеки потребител, работещ в Интернет, среща препратки към URL адрес, URL адреси, покани за преминаване към връзка и използване на връзката. За тези, които не са запознати или са нови за тези понятия, реших да напиша материал, в който ще ви кажа какво е URL, как да използвате URL, на какви части е разделен URL адресът, а също така ще обясня как да намерите правилната връзка в Интернет.
URL адрес- това е адрес, указващ пътя към интернет ресурс, на който се намират различни видове файлове (документи, снимки, видео, аудио и др.). Съкращението URL означава „Uniform Resource Locator“, на руски обикновено се произнася като „url“, „yu-ar-el“, „u-er-el“, често се използва просто думата „линк“.
Спомням си, че преди време търсих какво е URL адрес, за да разкажа компетентно на брат ми всички тънкости на концепцията. И аз самият се заинтересувах, когато се появи този термин.
Автор на концепцията за URL е британецът Тим Бърнс-Лий, а самото изобретение (1990 г.) бележи качествен скок в развитието на Интернет технологиите. Сега URL адресът е идентификатор на адресите на почти всички ресурси в мрежата, докато самият термин URL постепенно се заменя с по-широкия термин URI (Uniform Resource Identifier).
URL адреси на публикации в социалните медии

На какви части е разделен URL адресът?
Класически пример за URL адрес изглежда така:
http://адрес_на_сайт/папка/страница.html
Както можете да видите, URL адресът е разделен на няколко части:
Първа част (http://)определя протокола, който ще се използва. Най-просто казано, той говори за метода, който ще се използва за получаване на достъп до желания ресурс.
Протоколът „HTTP“, използван в този URL, означава „Протокол за прехвърляне на хипертекст“ и се използва в по-голямата част от случаите. Но можете да намерите URL адреси, използвайки други протоколи, например FTP (протокол за прехвърляне на файлове), HTTPS (сигурен протокол за прехвърляне на хипертекст - защитена, криптирана версия на HTTP), mailto (имейл адрес) и други.
Общо има няколко десетки типа URL протоколи: ftp, http, rtmp, rtsp, https, gopher, mailto, news, nntp, smb, prospero, telnet, wais, xmpp, file, data и др., но обикновено няколко използват се основни, изброени от мен малко по-нагоре.

Втора част(Адрес на сайт) е името на домейна. Технически това е просто линия от символи, букви или комбинация от думи, която позволява на хората лесно да запомнят адреса на любимата си страница. В противен случай връзките към ресурси ще изглеждат като http://192.168.384..
Трета част (папка/страница.html)обикновено сочи към страница с ресурси, до която потребителят иска да получи достъп. Може да бъде просто под формата на име или под формата на път към конкретен файл през набор от папки, като последните обикновено са разделени с наклонена черта (/). Разширението на интернет страниците може да бъде различно - php, htm, html, shtml, asp и редица други.
Тези обяснения могат да се видят нагледно във видеото:
Съкращения, използвани преди името на домейна www(World Wide Web) не е задължително, можете да използвате адреса на сайта без него, сайтът със сигурност ще се отвори.
Характеристики на използване на URL адрес
Ако посоченият от потребителя URL адрес не е правилен, тогава системата ще ни покаже грешка 404 с бележка „Страницата не е намерена!“ Това означава, че потребителят е въвел или грешен, или остарял адрес на страницата, следователно се изисква точност, точност и внимание при въвеждане на адреса. Когато въвеждате URL, бих препоръчал да използвате , като копирате адреса на страницата с помощта на функциите „copy/paste“. Можете също да опитате да въведете съкратен URL адрес под формата само на основното име на сайта (без папки и страници), а на главната страница на сайта потърсете връзка към страницата, от която се нуждаем.

Недостатъци на URL адресите
След като описахме, че това е URL връзка, нека да разгледаме всички недостатъци на URL. Наред с предимствата, че улесняват навигацията в Интернет, URL адресите имат своите недостатъци. Това работи само с цифри, латински букви и някои символи, кирилицата обикновено трябва да бъде прекодирана (URL Encoding) на два етапа, в първия от които всеки кирилски знак се преобразува в два байта, а след това всеки от байтовете се пренаписва с шестнадесетичната система.
Освен това се препоръчва използването на предимно малки букви в адреса (някои Unix системи ще възприемат техните варианти с главни букви като различни знаци, което може да доведе до грешка при отваряне на страницата), а също така е забранено използването на интервали в URL адресите.
Как да намерите URL адрес. Отметки.
За да намерите необходимия URL адрес, можете да използвате търсачки, в които трябва да въведете ключовите думи за вашето търсене. Например, ако имате нужда от филм, въведете името му или имената на актьорите, ако музика - имената на изпълнителите и името на композицията. Щраквайки върху „Търсене“, ще получите много сайтове с URL адреси, като щракнете върху които можете да намерите желания резултат.
URL адресът на страницата, на която се намирате в момента, се намира в горната част на адресната лента на вашия браузър.
За да запомните URL адреса на страницата, от която се нуждаете, използвайте лентата с отметки на вашия браузър. Например в популярния браузър Mozilla Firefox иконата на отметки под формата на звездичка се намира горе вдясно на нивото на адресната лента. Щраквайки върху него, ще можете да въведете име за вашата отметка, както и папка, където да поставите отметките (обикновено използвам специален панел с отметки, който ви позволява да получите достъп до всяка от тях с едно щракване).
Заключение
Използването на URL адреси значително опрости интернет, позволявайки на много потребители лесно и бързо да имат достъп до сайтовете, от които се нуждаят. Ако все още имате въпроси, след като прочетете статията „Какво е URL адрес?“, напишете ги в коментарите към статията.
Всичко, което е необходимо днес, е да въведете името на сайта и неговото разширение в адресната лента, след което потребителят получава почти незабавен достъп до ресурса. И всичко това, без да е необходимо да запомните доста сложна поредица от трицифрени числа, всичко се прави лесно, бързо, ефективно - общо взето това, което е необходимо, нали.
Във връзка с