Ցուցանիշներ- սա առաջին բանն է, որ դուք պետք է լավ հասկանաք ձեր աշխատանքում SQL Server, բայց տարօրինակ կերպով հիմնական հարցերը շատ հաճախ չեն տրվում ֆորումներում և շատ պատասխաններ չեն ստանում:
Ռոբ Շելդոնպատասխանում է այս հարցերին, որոնք մասնագիտական շրջանակներում խառնաշփոթ են առաջացնում ինդեքսների վերաբերյալ SQL ServerՆրանցից ոմանց մենք ուղղակի ամաչում ենք հարցնել, բայց մյուսներին հարցնելուց առաջ մենք նախ երկու անգամ կմտածենք:
Օգտագործված տերմինաբանություն.
| ցուցանիշը | ցուցանիշը |
| կույտ | մի փունջ |
| սեղան | սեղան |
| դիտել | կատարումը |
| Բ-ծառ | հավասարակշռված ծառ |
| կլաստերային ինդեքս | կլաստերային ինդեքս |
| ոչ կլաստերային ինդեքս | ոչ կլաստերային ինդեքս |
| կոմպոզիտային ինդեքս | կոմպոզիտային ինդեքս |
| ծածկույթի ինդեքս | ծածկույթի ինդեքս |
| առաջնային բանալիների սահմանափակում | առաջնային բանալիների սահմանափակում |
| եզակի սահմանափակում | արժեքների եզակիության սահմանափակում |
| հարցում | խնդրանք |
| հարցումների շարժիչ | հարցումների ենթահամակարգ |
| տվյալների բազա | տվյալների բազա |
| տվյալների բազայի շարժիչ | պահեստավորման ենթահամակարգ |
| լրացման գործակիցը | ինդեքսի լրացման գործակիցը |
| փոխարինող առաջնային բանալին | փոխարինող առաջնային բանալին |
| հարցումների օպտիմիզատոր | հարցումների օպտիմիզատոր |
| ինդեքսի ընտրողականություն | ինդեքսի ընտրողականություն |
| ֆիլտրացված ինդեքս | զտվող ինդեքս |
| կատարման պլան | կատարման պլան |
SQL Server-ում ինդեքսների հիմունքները.
Բարձր արտադրողականության հասնելու ամենակարևոր ուղիներից մեկը SQL Serverինդեքսների օգտագործումն է։ Ինդեքսն արագացնում է հարցումների գործընթացը՝ ապահովելով արագ մուտք դեպի աղյուսակի տվյալների տողեր, ճիշտ այնպես, ինչպես գրքի ինդեքսն օգնում է ձեզ արագ գտնել ձեզ անհրաժեշտ տեղեկատվությունը: Այս հոդվածում ես կտամ ինդեքսների համառոտ ակնարկ SQL Serverև բացատրել, թե ինչպես են դրանք կազմակերպված տվյալների բազայում և ինչպես են դրանք օգնում արագացնել տվյալների բազայի հարցումները:
Ցուցանիշները ստեղծվում են սեղանի և դիտման սյունակների վրա: Ինդեքսները հնարավորություն են տալիս արագ որոնել տվյալներ՝ հիմնված այդ սյունակներում առկա արժեքների վրա: Օրինակ, եթե դուք ինդեքս եք ստեղծում առաջնային բանալու վրա, այնուհետև որոնում եք տվյալների տող՝ օգտագործելով հիմնական բանալիների արժեքները, ապա SQL Serverնախ կգտնի ինդեքսի արժեքը, այնուհետև կօգտագործի ինդեքսը՝ տվյալների ամբողջ շարքը արագ գտնելու համար: Առանց ինդեքսի, աղյուսակի բոլոր տողերի վրա կկատարվի ամբողջական սկանավորում, ինչը կարող է էական ազդեցություն ունենալ կատարողականի վրա:
Դուք կարող եք ինդեքս ստեղծել աղյուսակի կամ տեսքի սյունակների մեծ մասի վրա: Բացառություն են հիմնականում խոշոր օբյեկտների պահպանման համար տվյալների տեսակներով սյունակները ( ԼՈԲ), ինչպիսիք են պատկեր, տեքստըկամ varchar (առավելագույնը). Դուք կարող եք նաև ինդեքսներ ստեղծել սյունակների վրա, որոնք նախատեսված են տվյալների ձևաչափով պահելու համար XML, բայց այս ցուցանիշները մի փոքր այլ կերպ են կառուցված, քան ստանդարտները, և դրանց քննարկումը դուրս է այս հոդվածի շրջանակներից: Բացի այդ, հոդվածը չի քննարկում սյունակատունցուցանիշները։ Փոխարենը, ես կենտրոնանում եմ այն ինդեքսների վրա, որոնք առավել հաճախ օգտագործվում են տվյալների բազաներում SQL Server.
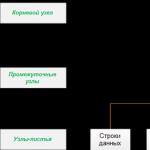
Ինդեքսը բաղկացած է մի շարք էջերից, ինդեքսային հանգույցներից, որոնք կազմակերպված են ծառի կառուցվածքով. հավասարակշռված ծառ. Այս կառուցվածքն իր բնույթով հիերարխիկ է և սկսվում է հիերարխիայի վերևում գտնվող արմատային հանգույցից և տերևային հանգույցներից, տերևներից, ներքևում, ինչպես ցույց է տրված նկարում.
Երբ հարցում եք անում ինդեքսավորված սյունակում, հարցման շարժիչը սկսվում է արմատային հանգույցի վերևից և իր ճանապարհն անցնում է միջանկյալ հանգույցների միջով, ընդ որում յուրաքանչյուր միջանկյալ շերտ պարունակում է ավելի մանրամասն տեղեկատվություն տվյալների մասին: Հարցման շարժիչը շարունակում է շարժվել ինդեքսային հանգույցներով, մինչև այն հասնի ինդեքսի տերևների ներքևի մակարդակին: Օրինակ, եթե դուք փնտրում եք 123 արժեքը ինդեքսավորված սյունակում, հարցման շարժիչը նախ կորոշի էջը առաջին միջանկյալ մակարդակում՝ արմատային մակարդակում: Այս դեպքում առաջին էջը մատնանշում է 1-ից մինչև 100 արժեք, իսկ երկրորդը՝ 101-ից մինչև 200, ուստի հարցումների շարժիչը կմտնի այս միջանկյալ մակարդակի երկրորդ էջը: Հաջորդը կտեսնեք, որ դուք պետք է դիմեք հաջորդ միջանկյալ մակարդակի երրորդ էջին: Այստեղից հարցման ենթահամակարգը ինքնին կկարդա ինդեքսի արժեքը ավելի ցածր մակարդակում: Ինդեքսի տերևները կարող են պարունակել կա՛մ աղյուսակի տվյալները, կա՛մ պարզապես ցուցիչ դեպի աղյուսակի տվյալներ ունեցող տողեր՝ կախված ինդեքսի տեսակից՝ կլաստերային կամ ոչ կլաստերային:
Կլաստերային ինդեքս
Կլաստերային ինդեքսը պահում է տվյալների իրական տողերը ինդեքսի տերևներում: Վերադառնալով նախորդ օրինակին, սա նշանակում է, որ 123-ի հիմնական արժեքի հետ կապված տվյալների շարքը կպահվի հենց ինդեքսում: Կլաստերային ինդեքսի կարևոր հատկանիշն այն է, որ բոլոր արժեքները դասավորված են որոշակի հերթականությամբ՝ աճման կամ նվազման: Հետևաբար, աղյուսակը կամ տեսքը կարող է ունենալ միայն մեկ կլաստերային ինդեքս: Բացի այդ, հարկ է նշել, որ աղյուսակի տվյալները պահվում են տեսակավորված ձևով միայն այն դեպքում, եթե այս աղյուսակում ստեղծվել է կլաստերային ինդեքս։
Աղյուսակը, որը չունի կլաստերային ինդեքս, կոչվում է կույտ:
Ոչ կլաստերային ինդեքս
Ի տարբերություն կլաստերային ինդեքսի, ոչ կլաստերային ինդեքսի տերևները պարունակում են միայն այդ սյունակները ( բանալի), որով որոշվում է այս ինդեքսը, ինչպես նաև պարունակում է ցուցիչ դեպի աղյուսակի իրական տվյալներ ունեցող տողեր։ Սա նշանակում է, որ ենթհարցման համակարգը պահանջում է լրացուցիչ գործողություն՝ անհրաժեշտ տվյալները գտնելու և առբերելու համար: Տվյալների ցուցիչի բովանդակությունը կախված է նրանից, թե ինչպես են տվյալները պահվում՝ կլաստերային աղյուսակ կամ կույտ: Եթե ցուցիչը ցույց է տալիս կլաստերացված աղյուսակը, այն ցույց է տալիս կլաստերային ինդեքս, որը կարող է օգտագործվել իրական տվյալները գտնելու համար: Եթե ցուցիչը վերաբերում է կույտին, ապա այն մատնանշում է կոնկրետ տվյալների տողի նույնացուցիչ: Ոչ կլաստերային ինդեքսները չեն կարող դասավորվել ինչպես կլաստերային ինդեքսները, բայց դուք կարող եք ստեղծել մեկից ավելի ոչ կլաստերային ինդեքս աղյուսակի կամ դիտման վրա՝ մինչև 999: Սա չի նշանակում, որ դուք պետք է հնարավորինս շատ ինդեքսներ ստեղծեք: Ինդեքսները կարող են կա՛մ բարելավել, կա՛մ վատթարացնել համակարգի աշխատանքը: Բացի այն, որ կարող եք ստեղծել բազմաթիվ ոչ կլաստերային ինդեքսներ, դուք կարող եք նաև ներառել լրացուցիչ սյունակներ ( ներառված սյունակ) իր ինդեքսում. ինդեքսի տերևները կպահեն ոչ միայն ինդեքսավորված սյունակների արժեքը, այլև այդ չինդեքսավորված լրացուցիչ սյունակների արժեքները: Այս մոտեցումը թույլ կտա շրջանցել ինդեքսի վրա դրված որոշ սահմանափակումներ։ Օրինակ, դուք կարող եք ներառել ոչ ինդեքսավորվող սյունակ կամ շրջանցել ինդեքսի երկարության սահմանը (շատ դեպքերում 900 բայթ):
Ինդեքսների տեսակները
Բացի կլաստերային կամ ոչ կլաստերային ինդեքս լինելուց, այն կարող է հետագայում կազմաձևվել որպես կոմպոզիտային ինդեքս, եզակի ինդեքս կամ ծածկող ինդեքս:
Կոմպոզիտային ինդեքս
Նման ցուցանիշը կարող է պարունակել մեկից ավելի սյունակ: Դուք կարող եք ներառել մինչև 16 սյունակ ինդեքսի մեջ, սակայն դրանց ընդհանուր երկարությունը սահմանափակվում է 900 բայթով: Ե՛վ կլաստերային, և՛ ոչ կլաստերային ինդեքսները կարող են լինել կոմպոզիտային:
Եզակի ցուցանիշ
Այս ցուցանիշը ապահովում է, որ ինդեքսավորված սյունակում յուրաքանչյուր արժեք եզակի է: Եթե ինդեքսը կոմպոզիտային է, ապա եզակիությունը վերաբերում է ինդեքսի բոլոր սյունակներին, բայց ոչ յուրաքանչյուր առանձին սյունակի: Օրինակ, եթե դուք ստեղծեք եզակի ինդեքս սյունակների վրա ԱՆՈՒՆԵվ ԱԶԳԱՆՈՒՆ, ապա լրիվ անունը պետք է լինի եզակի, բայց հնարավոր են կրկնօրինակներ անվան կամ ազգանվան մեջ։
Եզակի ինդեքսը ավտոմատ կերպով ստեղծվում է, երբ դուք սահմանում եք սյունակի սահմանափակում՝ առաջնային բանալի կամ եզակի արժեքի սահմանափակում.
- Առաջնային բանալին
Երբ դուք սահմանում եք հիմնական բանալի սահմանափակում մեկ կամ մի քանի սյունակների վրա, ապա SQL Serverինքնաբերաբար ստեղծում է եզակի կլաստերային ինդեքս, եթե նախկինում խմբավորված ինդեքս չի ստեղծվել (այս դեպքում առաջնային բանալին ստեղծվում է եզակի ոչ կլաստերային ինդեքս) - Արժեքների յուրահատկություն
Երբ դուք սահմանափակում եք սահմանում արժեքների եզակիության վրա, ապա SQL Serverավտոմատ կերպով ստեղծում է եզակի ոչ կլաստերային ինդեքս: Դուք կարող եք նշել, որ ստեղծվի եզակի կլաստերային ինդեքս, եթե աղյուսակում դեռևս խմբավորված ինդեքս չի ստեղծվել:
Ծածկույթի ինդեքս
Նման ինդեքսը թույլ է տալիս կոնկրետ հարցումին անմիջապես ստանալ բոլոր անհրաժեշտ տվյալները ինդեքսի տերևներից՝ առանց աղյուսակի գրառումների լրացուցիչ մուտքի։
Ինդեքսների նախագծում
Որքան էլ ինդեքսները կարող են օգտակար լինել, դրանք պետք է զգույշ մշակվեն: Քանի որ ինդեքսները կարող են զգալի սկավառակի տարածություն գրավել, դուք չեք ցանկանում ստեղծել ավելի շատ ինդեքսներ, քան անհրաժեշտ է: Բացի այդ, ինդեքսները ինքնաբերաբար թարմացվում են, երբ ինքնին տվյալների շարքը թարմացվում է, ինչը կարող է հանգեցնել լրացուցիչ ռեսուրսների վերին ծախսերի և կատարողականի վատթարացման: Ինդեքսները նախագծելիս պետք է հաշվի առնել մի քանի նկատառումներ՝ կապված տվյալների բազայի և դրա դեմ ուղղված հարցումների հետ:
Տվյալների բազա
Ինչպես նշվեց ավելի վաղ, ինդեքսները կարող են բարելավել համակարգի աշխատանքը, քանի որ նրանք հարցումների շարժիչին ապահովում են տվյալներ գտնելու արագ եղանակով: Այնուամենայնիվ, դուք պետք է նաև հաշվի առնեք, թե որքան հաճախ եք մտադրվում տեղադրել, թարմացնել կամ ջնջել տվյալները: Երբ դուք փոխում եք տվյալները, ինդեքսները նույնպես պետք է փոխվեն, որպեսզի արտացոլեն տվյալների վրա համապատասխան գործողությունները, ինչը կարող է զգալիորեն նվազեցնել համակարգի աշխատանքը: Ձեր ինդեքսավորման ռազմավարությունը պլանավորելիս հաշվի առեք հետևյալ ուղեցույցները.
- Հաճախակի թարմացվող աղյուսակների համար օգտագործեք որքան հնարավոր է քիչ ինդեքսներ:
- Եթե աղյուսակը պարունակում է մեծ քանակությամբ տվյալներ, բայց փոփոխությունները աննշան են, ապա օգտագործեք այնքան ինդեքս, որքան անհրաժեշտ է ձեր հարցումների կատարումը բարելավելու համար: Այնուամենայնիվ, փոքր սեղանների վրա ինդեքսներ օգտագործելուց առաջ լավ մտածեք, քանի որ... Հնարավոր է, որ ինդեքսի որոնման օգտագործումը կարող է ավելի երկար տևել, քան պարզապես սկանավորել բոլոր տողերը:
- Կլաստերային ինդեքսների համար փորձեք դաշտերը հնարավորինս կարճ պահել: Լավագույն մոտեցումը կլաստերային ինդեքս օգտագործելն է սյունակների վրա, որոնք ունեն եզակի արժեքներ և թույլ չեն տալիս NULL: Ահա թե ինչու առաջնային բանալին հաճախ օգտագործվում է որպես կլաստերային ինդեքս:
- Սյունակի արժեքների եզակիությունը ազդում է ինդեքսի կատարողականի վրա: Ընդհանուր առմամբ, որքան ավելի շատ կրկնօրինակներ ունեք սյունակում, այնքան վատ է ցուցանիշը կատարում: Մյուս կողմից, որքան շատ եզակի արժեքներ լինեն, այնքան ավելի լավ կլինի ցուցանիշի կատարումը: Հնարավորության դեպքում օգտագործեք եզակի ինդեքս:
- Կոմպոզիտային ինդեքսի համար հաշվի առեք ինդեքսի սյունակների հերթականությունը: Սյունակներ, որոնք օգտագործվում են արտահայտություններում ՈՐՏԵՂ(Օրինակ, WHERE FirstName = «Չարլի») պետք է լինի առաջինը ինդեքսում: Հետագա սյունակները պետք է թվարկվեն՝ ելնելով դրանց արժեքների եզակիությունից (առաջին տեղում են ամենաշատ եզակի արժեքներով սյունակները):
- Դուք կարող եք նաև նշել ինդեքսը հաշվարկված սյունակների վրա, եթե դրանք համապատասխանում են որոշակի պահանջներին: Օրինակ, սյունակի արժեքը ստանալու համար օգտագործվող արտահայտությունները պետք է լինեն դետերմինիստական (միշտ վերադարձնել նույն արդյունքը տվյալ մուտքային պարամետրերի համար):
Տվյալների բազայի հարցումներ
Մեկ այլ նկատառում ինդեքսների նախագծման ժամանակ այն է, թե ինչ հարցումներ են կատարվում տվյալների բազայի վրա: Ինչպես նշվեց ավելի վաղ, դուք պետք է հաշվի առնեք, թե որքան հաճախ են փոխվում տվյալները: Բացի այդ, պետք է օգտագործվեն հետևյալ սկզբունքները.
- Փորձեք տեղադրել կամ փոփոխել որքան հնարավոր է շատ տողեր մեկ հարցման մեջ, այլ ոչ թե դա անել մի քանի առանձին հարցումներում:
- Ստեղծեք ոչ կլաստերային ինդեքս սյունակների վրա, որոնք հաճախ օգտագործվում են որպես որոնման տերմիններ ձեր հարցումներում: ՈՐՏԵՂև միացումներ ՄԻԱՑԵՔ.
- Հաշվի առեք ինդեքսավորման սյունակները, որոնք օգտագործվում են տողերի որոնման հարցումներում ճշգրիտ արժեքների համընկնումների համար:
Ինչու՞ աղյուսակը չի կարող ունենալ երկու կլաստերային ինդեքս:
Ցանկանու՞մ եք կարճ պատասխան: Կլաստերային ինդեքսը աղյուսակ է: Երբ աղյուսակի վրա ստեղծում եք կլաստերային ինդեքս, պահեստավորման շարժիչը դասավորում է աղյուսակի բոլոր տողերը աճման կամ նվազման կարգով՝ ըստ ինդեքսի սահմանման: Կլաստերային ինդեքսը առանձին միավոր չէ, ինչպես մյուս ինդեքսները, այլ աղյուսակում տվյալները տեսակավորելու և տվյալների տողերի արագ մուտքը հեշտացնելու մեխանիզմ:
Պատկերացնենք, որ դուք ունեք վաճառքի գործարքների պատմություն պարունակող աղյուսակ։ Վաճառքի աղյուսակը ներառում է այնպիսի տեղեկություններ, ինչպիսիք են պատվերի ID-ն, ապրանքի դիրքը պատվերի մեջ, ապրանքի համարը, ապրանքի քանակը, պատվերի համարը և ամսաթիվը և այլն: Դուք ստեղծում եք կլաստերային ինդեքս սյունակների վրա Պատվերի IDԵվ LineID, դասավորված է աճման կարգով, ինչպես ցույց է տրված ստորև T-SQLկոդը:
Երբ գործարկում եք այս սկրիպտը, աղյուսակի բոլոր տողերը ֆիզիկապես կդասակարգվեն սկզբում OrderID սյունակով, այնուհետև՝ ըստ LineID-ի, բայց տվյալներն ինքնին կմնան մեկ տրամաբանական բլոկում՝ աղյուսակում: Այս պատճառով դուք չեք կարող ստեղծել երկու կլաստերային ինդեքս: Կարող է լինել միայն մեկ աղյուսակ մեկ տվյալների հետ, և այդ աղյուսակը կարող է տեսակավորվել միայն մեկ անգամ՝ որոշակի հերթականությամբ:
Եթե կլաստերային աղյուսակը տալիս է բազմաթիվ առավելություններ, ապա ինչո՞ւ օգտագործել կույտ:
Դու ճիշտ ես. Կլաստերային աղյուսակները հիանալի են, և ձեր հարցումների մեծ մասը ավելի լավ կաշխատի այն աղյուսակներում, որոնք ունեն կլաստերային ինդեքս: Բայց որոշ դեպքերում դուք կարող եք ցանկանալ թողնել սեղանները իրենց բնական, անաղարտ վիճակում, այսինքն. կույտի տեսքով և ստեղծեք միայն ոչ կլաստերային ինդեքսներ՝ ձեր հարցումները շարունակելու համար:
Կույտը, ինչպես հիշում եք, պահում է տվյալները պատահական կարգով: Սովորաբար պահեստավորման ենթահամակարգը տվյալներ է ավելացնում աղյուսակին այն հաջորդականությամբ, որով դրանք տեղադրվում են, բայց պահեստային ենթահամակարգը նույնպես սիրում է տողեր տեղափոխել ավելի արդյունավետ պահպանման համար: Արդյունքում, դուք հնարավորություն չունեք կանխատեսելու, թե ինչ հերթականությամբ կպահվեն տվյալները։
Եթե հարցումների շարժիչը պետք է տվյալներ գտնի առանց ոչ կլաստերային ինդեքսի, ապա այն կկատարի աղյուսակի ամբողջական սկանավորում՝ իրեն անհրաժեշտ տողերը գտնելու համար: Շատ փոքր սեղանների վրա դա սովորաբար խնդիր չէ, բայց քանի որ կույտը մեծանում է չափի մեջ, արդյունավետությունը արագ նվազում է: Իհարկե, ոչ կլաստերային ինդեքսը կարող է օգնել՝ օգտագործելով ցուցիչը դեպի ֆայլը, էջը և տողը, որտեղ պահվում են պահանջվող տվյալները. սա սովորաբար շատ ավելի լավ այլընտրանք է աղյուսակի սկանավորմանը: Չնայած դրան, դժվար է համեմատել կլաստերային ինդեքսի առավելությունները՝ դիտարկելիս հարցումների կատարումը:
Այնուամենայնիվ, կույտը կարող է օգնել բարելավել աշխատանքը որոշակի իրավիճակներում: Դիտարկենք աղյուսակը, որտեղ կան բազմաթիվ ներդիրներ, բայց քիչ թարմացումներ կամ ջնջումներ: Օրինակ, տեղեկամատյան պահող աղյուսակը հիմնականում օգտագործվում է արժեքներ տեղադրելու համար, մինչև այն արխիվացվի: Կույտում դուք չեք տեսնի էջավորումը և տվյալների մասնատումը, ինչպես կտեսնեիք կլաստերային ինդեքսի դեպքում, քանի որ տողերը պարզապես ավելացվում են կույտի վերջում: Էջերի չափից շատ բաժանումը կարող է էական ազդեցություն ունենալ կատարողականի վրա, և ոչ լավ իմաստով: Ընդհանրապես, կույտը թույլ է տալիս համեմատաբար ցավ չպատճառել տվյալները, և դուք ստիպված չեք լինի զբաղվել պահեստավորման և սպասարկման ծախսերի հետ, ինչպես կլաստերային ինդեքսով:
Սակայն տվյալների թարմացման և ջնջման բացակայությունը պետք չէ միակ պատճառը համարել։ Կարևոր գործոն է նաև տվյալների նմուշառման ձևը: Օրինակ, դուք չպետք է օգտագործեք կույտ, եթե դուք հաճախակի հարցումներ եք կատարում տվյալների տիրույթներում, կամ ձեր հարցումների տվյալները հաճախ պետք է տեսակավորվեն կամ խմբավորվեն:
Այս ամենը նշանակում է, որ դուք պետք է հաշվի առնեք կույտի օգտագործումը միայն այն ժամանակ, երբ աշխատում եք շատ փոքր աղյուսակների հետ, կամ աղյուսակի հետ ձեր ամբողջ փոխազդեցությունը սահմանափակվում է տվյալների տեղադրմամբ, և ձեր հարցումները չափազանց պարզ են (և դուք օգտագործում եք ոչ կլաստերային ինդեքսներ: ամեն դեպքում): Հակառակ դեպքում, պահպանեք լավ մշակված կլաստերային ինդեքսը, ինչպիսին է պարզ աճող առանցքային դաշտում սահմանվածը, ինչպես լայնորեն օգտագործվող սյունակը ԻՆՔՆՈՒԹՅՈՒՆ.
Ինչպե՞ս կարող եմ փոխել լռելյայն ինդեքսի լրացման գործակիցը:
Նախնական ինդեքսի լրացման գործակիցը փոխելը մի բան է: Հասկանալը, թե ինչպես է աշխատում լռելյայն հարաբերակցությունը, այլ խնդիր է: Բայց նախ մի քանի քայլ հետ արա: Ինդեքսի լրացման գործակիցը որոշում է էջի վրա տարածության քանակը՝ ինդեքսը ներքևի մակարդակում (տերևի մակարդակ) պահելու համար՝ նախքան նոր էջ լրացնելը: Օրինակ, եթե գործակիցը դրված է 90, ապա երբ ինդեքսը մեծանա, այն կզբաղեցնի էջի 90%-ը, այնուհետև կտեղափոխվի հաջորդ էջ։
Լռելյայնորեն, ինդեքսի լրացման գործոնի արժեքը նշված է SQL Server 0-ն է, որը նույնն է, ինչ 100-ը: Արդյունքում, բոլոր նոր ինդեքսներն ավտոմատ կերպով ժառանգում են այս պարամետրը, եթե դուք հատուկ չնշեք ձեր կոդի արժեք, որը տարբերվում է համակարգի ստանդարտ արժեքից կամ չփոխեք լռելյայն վարքագիծը: Դուք կարող եք օգտագործել SQL Server Management Studioլռելյայն արժեքը կարգավորելու կամ համակարգում պահվող ընթացակարգը գործարկելու համար sp_configure. Օրինակ, հետեւյալ հավաքածուն T-SQLհրամանները գործակցի արժեքը սահմանում են 90 (նախ պետք է անցնեք առաջադեմ կարգավորումների ռեժիմին).
EXEC sp_configure "ցուցադրել առաջադեմ ընտրանքները ", 1; GO RECONFIGURE; GO EXEC sp_configure "լրացման գործակից», 90; GO RECONFIGURE; GO
Ինդեքսի լրացման գործոնի արժեքը փոխելուց հետո դուք պետք է վերագործարկեք ծառայությունը SQL Server. Այժմ կարող եք ստուգել սահմանված արժեքը՝ գործարկելով sp_configure առանց նշված երկրորդ արգումենտի.
EXEC sp_configure «fill factor» GO
Այս հրամանը պետք է վերադարձնի 90 արժեք: Արդյունքում, բոլոր նոր ստեղծված ինդեքսները կօգտագործեն այս արժեքը: Դուք կարող եք դա ստուգել՝ ստեղծելով ինդեքս և հարցում կատարելով լրացման գործոնի արժեքի համար.
ՕԳՏԱԳՈՐԾԵԼ AdventureWorks2012; -- Ձեր տվյալների բազան GO CREATE NONCLUSTERED INDEX ix_people_lastname ON Person.Person(LastName); GO SELECT fill_factor FROM sys .indexes WHERE object_id = object_id("Person.Person" ) AND name =="ix_people_lastname" ;Այս օրինակում մենք աղյուսակի վրա ստեղծեցինք ոչ կլաստերային ինդեքս Անձտվյալների բազայում AdventureWorks2012. Ինդեքսը ստեղծելուց հետո sys.indexes համակարգի աղյուսակներից կարող ենք ստանալ լրացման գործոնի արժեքը։ Հարցումը պետք է վերադարձնի 90:
Այնուամենայնիվ, եկեք պատկերացնենք, որ մենք ջնջել ենք ինդեքսը և նորից ստեղծել այն, բայց այժմ մենք նշել ենք լրացման գործոնի որոշակի արժեքը.
Այս անգամ մենք ավելացրել ենք հրահանգներ ՀԵՏև տարբերակ լրացնող գործոնինդեքսի ստեղծման մեր գործողության համար ՍՏԵՂԾԵԼ ԻԴԵՔՍեւ նշել է արժեքը 80. Օպերատոր ԸՆՏՐԵԼայժմ վերադարձնում է համապատասխան արժեքը:
Մինչ այժմ ամեն ինչ բավականին պարզ է եղել: Այնտեղ, որտեղ դուք իսկապես կարող եք այրվել այս ամբողջ գործընթացում, այն է, երբ դուք ստեղծում եք ինդեքս, որն օգտագործում է լռելյայն գործակցի արժեքը՝ ենթադրելով, որ դուք գիտեք այդ արժեքը: Օրինակ, ինչ-որ մեկը խոժոռում է սերվերի կարգավորումները և այնքան համառ է, որ ինդեքսի լրացման գործակիցը սահմանում է 20: Մինչդեռ դուք շարունակում եք ինդեքսներ ստեղծել՝ ենթադրելով, որ լռելյայն արժեքը 0 է: Ցավոք, դուք ճանապարհ չունեք պարզելու լրացումը: գործակցեք այնքան ժամանակ, քանի դեռ դուք չեք ստեղծում ինդեքս, ապա ստուգեք արժեքը, ինչպես մենք արեցինք մեր օրինակներում: Հակառակ դեպքում, դուք պետք է սպասեք այն պահին, երբ հարցումների կատարողականը այնքան կնվազի, որ դուք սկսեք ինչ-որ բան կասկածել:
Մեկ այլ խնդիր, որը դուք պետք է տեղյակ լինեք, ինդեքսների վերակառուցումն է: Ինչպես ինդեքս ստեղծելու դեպքում, դուք կարող եք նշել ինդեքսի լրացման գործոնի արժեքը, երբ այն վերակառուցեք: Այնուամենայնիվ, ի տարբերություն ստեղծելու ինդեքս հրամանի, վերակառուցումը չի օգտագործում սերվերի լռելյայն կարգավորումները, չնայած այն, ինչ կարող է թվալ: Նույնիսկ ավելին, եթե դուք հատուկ չեք նշում ինդեքսի լրացման գործոնի արժեքը, ապա SQL Serverկօգտագործի այն գործակցի արժեքը, որով այս ցուցանիշը գոյություն ուներ մինչ դրա վերակառուցումը։ Օրինակ, հետեւյալ գործողությունը ՓՈՓՈԽԵԼ ԻԴԵՔՍվերակառուցում է մեր նոր ստեղծած ինդեքսը.
Երբ մենք ստուգում ենք լրացման գործոնի արժեքը, մենք կստանանք 80 արժեք, քանի որ դա այն է, ինչ մենք նշել ենք վերջին անգամ ինդեքսը ստեղծելիս: Կանխադրված արժեքը անտեսվում է:
Ինչպես տեսնում եք, ինդեքսի լրացման գործոնի արժեքը փոխելն այնքան էլ դժվար չէ: Շատ ավելի դժվար է իմանալ ընթացիկ արժեքը և հասկանալ, թե երբ է այն կիրառվում: Եթե ինդեքսներ ստեղծելիս և վերակառուցելիս միշտ կոնկրետ նշում եք գործակիցը, ապա միշտ գիտեք կոնկրետ արդյունքը։ Եթե դուք ստիպված չեք լինի անհանգստանալ, որպեսզի համոզվեք, որ ինչ-որ մեկը նորից չի խեղաթյուրում սերվերի կարգավորումները, ինչի հետևանքով բոլոր ինդեքսները վերակառուցվում են ծիծաղելիորեն ցածր ինդեքսների լրացման գործակցով:
Հնարավո՞ր է արդյոք ստեղծել կլաստերային ինդեքս սյունակի վրա, որը պարունակում է կրկնօրինակներ:
Այո եւ ոչ. Այո, դուք կարող եք ստեղծել կլաստերային ինդեքս առանցքային սյունակի վրա, որը պարունակում է կրկնօրինակ արժեքներ: Ոչ, առանցքային սյունակի արժեքը չի կարող մնալ ոչ եզակի վիճակում: Թույլ տուր բացատրեմ. Եթե դուք ստեղծում եք ոչ եզակի կլաստերային ինդեքս սյունակի վրա, պահեստավորման շարժիչը կրկնօրինակ արժեքին միավորիչ է ավելացնում, որպեսզի ապահովի եզակիությունը և, հետևաբար, կարողանա նույնականացնել կլաստերային աղյուսակի յուրաքանչյուր տողը:
Օրինակ, դուք կարող եք որոշել ստեղծել կլաստերային ինդեքս հաճախորդների տվյալներ պարունակող սյունակի վրա Ազգանունպահպանելով ազգանունը. Սյունակը պարունակում է Ֆրանկլին, Հենքոք, Վաշինգտոն և Սմիթ արժեքները: Այնուհետև կրկին տեղադրում եք Ադամս, Հենքոք, Սմիթ և Սմիթ արժեքները: Բայց հիմնական սյունակի արժեքը պետք է եզակի լինի, ուստի պահեստավորման շարժիչը կփոխի կրկնօրինակների արժեքը, որպեսզի նրանք նման լինեն՝ Ադամս, Ֆրանկլին, Հենքոկ, Հանկոկ1234, Վաշինգտոն, Սմիթ, Սմիթ4567 և Սմիթ5678:
Առաջին հայացքից այս մոտեցումը լավ է թվում, բայց ամբողջ թիվը մեծացնում է բանալու չափը, ինչը կարող է խնդիր դառնալ, եթե կան մեծ թվով կրկնօրինակներ, և այդ արժեքները կդառնան ոչ կլաստերային ինդեքսի կամ օտարերկրյա ինդեքսի հիմքը: հիմնական հղում. Այս պատճառներով դուք միշտ պետք է փորձեք ստեղծել եզակի կլաստերային ինդեքսներ, երբ դա հնարավոր է: Եթե դա հնարավոր չէ, ապա գոնե փորձեք օգտագործել շատ բարձր եզակի արժեք ունեցող սյունակներ:
Ինչպե՞ս է աղյուսակը պահվում, եթե խմբավորված ինդեքս չի ստեղծվել:
SQL Serverաջակցում է երկու տեսակի աղյուսակներ՝ կլաստերային աղյուսակներ, որոնք ունեն կլաստերային ինդեքս և կույտային աղյուսակներ կամ պարզապես կույտեր: Ի տարբերություն կլաստերային աղյուսակների, կույտի տվյալները ոչ մի կերպ չեն դասավորված: Ըստ էության, սա տվյալների կույտ է (կույտ): Եթե դուք տող ավելացնեք նման աղյուսակում, ապա պահեստային շարժիչը պարզապես կավելացնի այն էջի վերջում: Երբ էջը լցվի տվյալներով, այն կավելացվի նոր էջ: Շատ դեպքերում, դուք կցանկանաք ստեղծել կլաստերային ինդեքս սեղանի վրա, որպեսզի օգտվեք տեսակավորման և հարցումների արագությունից (փորձեք պատկերացնել, որ հեռախոսահամարը փնտրեք չտեսակավորված հասցեագրքում): Այնուամենայնիվ, եթե որոշեք չստեղծել կլաստերային ինդեքս, դուք դեռ կարող եք ստեղծել ոչ կլաստերային ինդեքս կույտի վրա: Այս դեպքում յուրաքանչյուր ինդեքսային տող կունենա ցուցիչ դեպի կույտ տող: Ցուցանիշը ներառում է ֆայլի ID-ն, էջի համարը և տվյալների գծի համարը:
Ի՞նչ կապ կա արժեքի եզակիության սահմանափակումների և աղյուսակի ինդեքսների հետ առաջնային բանալիների միջև:
Առաջնային բանալին և եզակի սահմանափակումը ապահովում են, որ սյունակի արժեքները եզակի են: Աղյուսակի համար կարող եք ստեղծել միայն մեկ հիմնական բանալի, և այն չի կարող արժեքներ պարունակել ԴԱՏԱՐԿ. Դուք կարող եք ստեղծել մի քանի սահմանափակումներ աղյուսակի համար արժեքի եզակիության վերաբերյալ, և դրանցից յուրաքանչյուրը կարող է ունենալ մեկ գրառում ԴԱՏԱՐԿ.
Երբ դուք ստեղծում եք առաջնային բանալի, պահեստավորման շարժիչը նաև ստեղծում է եզակի կլաստերային ինդեքս, եթե խմբավորված ինդեքսն արդեն չի ստեղծվել: Այնուամենայնիվ, դուք կարող եք անտեսել լռելյայն վարքագիծը, և կստեղծվի ոչ կլաստերային ինդեքս: Եթե առաջնային բանալին ստեղծելիս գոյություն ունի կլաստերային ինդեքս, կստեղծվի եզակի ոչ կլաստերային ինդեքս:
Երբ դուք ստեղծում եք եզակի սահմանափակում, պահեստավորման շարժիչը ստեղծում է եզակի, ոչ կլաստերային ինդեքս: Այնուամենայնիվ, դուք կարող եք նշել եզակի կլաստերային ինդեքսի ստեղծումը, եթե նախկինում չի ստեղծվել:
Ընդհանրապես, եզակի արժեքի սահմանափակումը և եզակի ինդեքսը նույն բանն են:
Ինչու են կլաստերային և ոչ կլաստերային ինդեքսները SQL Server-ում կոչվում B-tree:
SQL Server-ի հիմնական ինդեքսները՝ կլաստերային կամ ոչ կլաստերային, բաշխվում են էջերի խմբերի վրա, որոնք կոչվում են ինդեքսային հանգույցներ: Այս էջերը կազմակերպված են որոշակի հիերարխիայում՝ ծառի կառուցվածքով, որը կոչվում է հավասարակշռված ծառ: Վերին մակարդակում արմատային հանգույցն է, ներքևում՝ տերևային հանգույցները, վերին և ստորին մակարդակների միջև միջանկյալ հանգույցներով, ինչպես ցույց է տրված նկարում.
Արմատային հանգույցը ապահովում է հիմնական մուտքի կետը հարցումների համար, որոնք փորձում են տվյալներ ստանալ ինդեքսի միջոցով: Այս հանգույցից սկսած հարցման շարժիչը սկսում է նավարկություն հիերարխիկ կառուցվածքով դեպի տվյալներ պարունակող համապատասխան տերևային հանգույց:
Օրինակ, պատկերացրեք, որ ստացվել է 82 հիմնական արժեք պարունակող տողեր ընտրելու հարցում: Հարցման ենթահամակարգը սկսում է աշխատել արմատային հանգույցից, որը վերաբերում է համապատասխան միջանկյալ հանգույցին, մեր դեպքում 1-100: 1-100 միջանկյալ հանգույցից անցում է կատարվում 51-100 հանգույցին, իսկ այնտեղից՝ վերջնական 76-100 հանգույցին։ Եթե սա կլաստերային ինդեքս է, ապա հանգույցի տերևը պարունակում է 82-ի բանալու հետ կապված տողի տվյալները: Եթե սա ոչ կլաստերացված ինդեքս է, ապա ցուցիչի թերթիկը պարունակում է ցուցիչ դեպի խմբավորված աղյուսակ կամ որոշակի տող: կույտը.
Ինչպե՞ս կարող է ինդեքսը նույնիսկ բարելավել հարցումների կատարումը, եթե դուք պետք է անցնեք այս բոլոր ինդեքսային հանգույցները:
Նախ, ինդեքսները միշտ չէ, որ բարելավում են կատարողականը: Չափից շատ սխալ ստեղծված ինդեքսները համակարգը վերածում են ճահճի և նվազեցնում հարցումների կատարողականը: Ավելի ճիշտ է ասել, որ եթե ինդեքսները ուշադիր կիրառվեն, դրանք կարող են ապահովել կատարողականի զգալի ձեռքբերումներ:
Մտածեք մի հսկայական գրքի մասին, որը նվիրված է կատարման թյունինգին SQL Server(թղթային տարբերակ, ոչ էլեկտրոնային տարբերակ): Պատկերացրեք, որ ցանկանում եք տեղեկատվություն գտնել Resource Governor-ի կազմաձևման մասին: Դուք կարող եք ձեր մատը էջ առ էջ քաշել ամբողջ գրքի միջով կամ բացել բովանդակության աղյուսակը և պարզել ճշգրիտ էջի համարը ձեր փնտրած տեղեկություններով (պայմանով, որ գիրքը ճիշտ ինդեքսավորված է, և բովանդակությունը ունի ճիշտ ինդեքսներ): Սա, անշուշտ, կխնայի ձեզ զգալի ժամանակ, թեև նախ պետք է մուտք գործեք բոլորովին այլ կառուցվածք (ինդեքս), որպեսզի ստանաք ձեզ անհրաժեշտ տեղեկատվությունը հիմնական կառուցվածքից (գրքից):
Գրքի ցուցիչի պես՝ ինդեքս SQL Serverթույլ է տալիս ճշգրիտ հարցումներ կատարել ձեզ անհրաժեշտ տվյալների վրա՝ աղյուսակում պարունակվող բոլոր տվյալները ամբողջությամբ սկանավորելու փոխարեն: Փոքր աղյուսակների դեպքում ամբողջական սկանավորումը սովորաբար խնդիր չէ, բայց մեծ աղյուսակները շատ էջեր են վերցնում տվյալների վրա, ինչը կարող է հանգեցնել հարցումների կատարման նշանակալի ժամանակի, եթե չկա ինդեքս, որը թույլ կտա հարցումների շարժիչին անմիջապես ստանալ տվյալների ճիշտ գտնվելու վայրը: Պատկերացրեք, թե ինչպես եք մոլորվում բազմաստիճան ճանապարհային հանգույցում՝ առանց քարտեզի խոշոր մետրոպոլիայի դիմաց, և դուք կհասկանաք գաղափարը:
Եթե ինդեքսներն այդքան մեծ են, ինչո՞ւ պարզապես չստեղծել մեկը յուրաքանչյուր սյունակում:
Ոչ մի լավ գործ չպետք է անպատիժ մնա. Գոնե ինդեքսների դեպքում այդպես է։ Իհարկե, ինդեքսները հիանալի են աշխատում, քանի դեռ դուք գործարկում եք օպերատորի բեռնման հարցումներ ԸՆՏՐԵԼ, բայց հենց որ սկսվեն հաճախակի զանգեր օպերատորներին ՆԵՐԴՐԵԼ, ԹԱՐՄԱՑՆԵԼԵվ ՋՆՋԵԼ, ուստի լանդշաֆտը շատ արագ փոխվում է։
Երբ օպերատորի կողմից տվյալների հարցում եք նախաձեռնում ԸՆՏՐԵԼ, հարցումների շարժիչը գտնում է ինդեքսը, շարժվում է իր ծառի կառուցվածքով և հայտնաբերում այն տվյալները, որոնք փնտրում են։ Ի՞նչ կարող է լինել ավելի պարզ: Բայց ամեն ինչ փոխվում է, եթե դուք նախաձեռնում եք փոփոխության նման հայտարարություն ԹԱՐՄԱՑՆԵԼ. Այո, հայտարարության առաջին մասի համար հարցումների շարժիչը կարող է կրկին օգտագործել ինդեքսը՝ փոփոխվող տողը գտնելու համար. դա լավ նորություն է: Եվ եթե անընդմեջ տվյալների մեջ պարզ փոփոխություն լինի, որը չի ազդի հիմնական սյունակների փոփոխությունների վրա, ապա փոփոխության գործընթացը լիովին ցավազուրկ կլինի: Բայց ի՞նչ, եթե փոփոխությունը պատճառ դառնա, որ տվյալներ պարունակող էջերը բաժանվեն, կամ առանցքային սյունակի արժեքը փոխվի՝ պատճառելով այն տեղափոխել մեկ այլ ինդեքսային հանգույց, դա կհանգեցնի նրան, որ ինդեքսը, հնարավոր է, կարիք կունենա վերակազմակերպման, որը կազդի բոլոր հարակից ինդեքսների և գործողությունների վրա: , ինչը հանգեցնում է արտադրողականության համատարած անկմանը։
Նմանատիպ գործընթացներ տեղի են ունենում օպերատորին զանգահարելիս ՋՆՋԵԼ. Ինդեքսը կարող է օգնել գտնել ջնջվող տվյալները, սակայն տվյալների ջնջումն ինքնին կարող է հանգեցնել էջի վերափոխման: Օպերատորի վերաբերյալ ՆԵՐԴՐԵԼ, բոլոր ինդեքսների գլխավոր թշնամին. սկսում ես մեծ քանակությամբ տվյալներ ավելացնել, ինչը հանգեցնում է ինդեքսների փոփոխության և դրանց վերակազմավորման և տուժում են բոլորը։
Այսպիսով, հաշվի առեք ձեր տվյալների բազայի հարցումների տեսակները, երբ մտածում եք, թե ինչ տեսակի ինդեքսներ և քանիսը ստեղծել: Ավելի շատ չի նշանակում ավելի լավ: Նախքան աղյուսակում նոր ինդեքս ավելացնելը, հաշվի առեք ոչ միայն հիմնական հարցումների արժեքը, այլև սպառված սկավառակի տարածքը, ֆունկցիոնալության պահպանման արժեքը և ինդեքսները, որոնք կարող են հանգեցնել դոմինոյի էֆեկտի այլ գործողությունների վրա: Ձեր ինդեքսի նախագծման ռազմավարությունը ձեր իրականացման ամենակարևոր ասպեկտներից մեկն է և պետք է ներառի բազմաթիվ նկատառումներ՝ սկսած ինդեքսի չափից, եզակի արժեքների քանակից մինչև ինդեքսի կողմից աջակցվող հարցումների տեսակը:
Արդյո՞ք անհրաժեշտ է առաջնային բանալիով սյունակի վրա ստեղծել կլաստերային ինդեքս:
Դուք կարող եք ստեղծել կլաստերային ինդեքս ցանկացած սյունակի վրա, որը համապատասխանում է պահանջվող պայմաններին: Ճիշտ է, որ կլաստերային ինդեքսը և հիմնական բանալի սահմանափակումը ստեղծված են միմյանց համար և համընկնում են դրախտում, այնպես որ հասկացեք այն փաստը, որ երբ դուք ստեղծում եք հիմնական բանալի, ապա կլաստերային ինդեքսը ավտոմատ կերպով կստեղծվի, եթե այդպիսին չի եղել: ստեղծված նախկինում։ Այնուամենայնիվ, դուք կարող եք որոշել, որ կլաստերային ինդեքսը այլ տեղ ավելի լավ կաշխատի, և հաճախ ձեր որոշումը արդարացված կլինի:
Կլաստերային ինդեքսի հիմնական նպատակն է դասավորել ձեր աղյուսակի բոլոր տողերը՝ հիմնվելով ինդեքսը սահմանելիս նշված հիմնական սյունակի վրա: Սա ապահովում է արագ որոնում և հեշտ մուտք դեպի աղյուսակի տվյալները:
Աղյուսակի առաջնային բանալին կարող է լավ ընտրություն լինել, քանի որ այն եզակի կերպով նույնացնում է աղյուսակների յուրաքանչյուր տող՝ առանց լրացուցիչ տվյալներ ավելացնելու: Որոշ դեպքերում լավագույն ընտրությունը կլինի փոխարինող առաջնային բանալին, որը ոչ միայն եզակի է, այլև փոքր չափսերով, և որի արժեքները հաջորդաբար աճում են՝ ավելի արդյունավետ դարձնելով այս արժեքի վրա հիմնված ոչ կլաստերային ինդեքսները: Հարցման օպտիմիզատորին դուր է գալիս նաև կլաստերացված ինդեքսի և առաջնային բանալու այս համադրությունը, քանի որ աղյուսակների միացումն ավելի արագ է, քան այլ եղանակով միանալը, որը չի օգտագործում հիմնական բանալի և դրա հետ կապված կլաստերային ինդեքսը: Ինչպես ասացի, դա դրախտում ստեղծված խաղ է:
Վերջապես, այնուամենայնիվ, հարկ է նշել, որ կլաստերային ինդեքս ստեղծելիս պետք է հաշվի առնել մի քանի ասպեկտ՝ քանի ոչ կլաստերային ինդեքսներ կհիմնվեն դրա վրա, որքան հաճախ կփոխվի հիմնական ինդեքսի սյունակի արժեքը և որքան մեծ: Երբ կլաստերային ինդեքսի սյունակներում արժեքները փոխվում են կամ ինդեքսը չի գործում այնպես, ինչպես սպասվում էր, ապա սեղանի մյուս բոլոր ինդեքսները կարող են ազդել: Կլաստերային ինդեքսը պետք է հիմնված լինի ամենակայուն սյունակի վրա, որի արժեքներն աճում են որոշակի կարգով, բայց պատահական չեն փոխվում: Ցուցանիշը պետք է աջակցի աղյուսակի ամենահաճախ հասանելի տվյալներին համապատասխան հարցումներին, այնպես որ հարցումները լիովին օգտվում են այն փաստից, որ տվյալները դասավորված են և հասանելի են արմատային հանգույցներում՝ ինդեքսի տերևներում: Եթե առաջնային բանալին համապատասխանում է այս սցենարին, ապա օգտագործեք այն: Եթե ոչ, ապա ընտրեք սյունակների այլ հավաքածու:
Իսկ եթե դուք ինդեքսավորեք դիտումը, դա դեռ դիտո՞ւմ է:
View-ը վիրտուալ աղյուսակ է, որը տվյալներ է ստեղծում մեկ կամ մի քանի աղյուսակներից: Ըստ էության, դա անվանված հարցում է, որը տվյալներ է առբերում հիմքում ընկած աղյուսակներից, երբ հարցում եք անում այդ տեսակետին: Դուք կարող եք բարելավել հարցումների կատարումը՝ ստեղծելով կլաստերային ինդեքս և ոչ կլաստերային ինդեքսներ այս տեսքի վրա, ինչպես աղյուսակի վրա ինդեքսներ եք ստեղծում, բայց հիմնական նախազգուշացումն այն է, որ նախ ստեղծեք կլաստերային ինդեքս, այնուհետև կարող եք ստեղծել ոչ կլաստերային:
Երբ ստեղծվում է ինդեքսավորված տեսք (նյութականացված տեսք), ապա դիտման սահմանումն ինքնին մնում է առանձին կազմություն։ Սա, ի վերջո, պարզապես կոշտ կոդավորված օպերատոր է ԸՆՏՐԵԼ, պահվում է տվյալների բազայում։ Բայց ցուցանիշը բոլորովին այլ պատմություն է։ Երբ մատակարարի վրա ստեղծում եք կլաստերային կամ ոչ կլաստերային ինդեքս, տվյալները ֆիզիկապես պահվում են սկավառակի վրա, ինչպես սովորական ինդեքսը: Բացի այդ, երբ տվյալների հիմքում ընկած աղյուսակներում փոխվում են, դիտումների ինդեքսն ինքնաբերաբար փոխվում է (սա նշանակում է, որ դուք կարող եք խուսափել հաճախակի փոփոխվող աղյուսակների դիտումների ինդեքսավորումից): Ամեն դեպքում, դիտումը մնում է դիտում՝ հայացք աղյուսակներին, բայց այս պահին կատարված՝ դրան համապատասխան ինդեքսներով։
Նախքան դիտման վրա ինդեքս ստեղծելը, այն պետք է համապատասխանի մի քանի սահմանափակումների: Օրինակ, դիտումը կարող է հղում կատարել միայն բազային աղյուսակներին, բայց ոչ այլ դիտումների, և այդ աղյուսակները պետք է լինեն նույն տվյալների բազայում: Իրականում կան բազմաթիվ այլ սահմանափակումներ, այնպես որ համոզվեք, որ ստուգեք փաստաթղթերը SQL Serverբոլոր կեղտոտ մանրամասների համար:
Ինչու՞ օգտագործել ծածկույթի ինդեքսը կոմպոզիտային ինդեքսի փոխարեն:
Նախ, եկեք համոզվենք, որ մենք հասկանում ենք երկուսի միջև եղած տարբերությունը: Բաղադրյալ ինդեքսը պարզապես կանոնավոր ինդեքս է, որը պարունակում է մեկից ավելի սյունակ: Բանալինների բազմաթիվ սյունակներ կարող են օգտագործվել՝ համոզվելու համար, որ աղյուսակի յուրաքանչյուր տողը եզակի է, կամ դուք կարող եք ունենալ մի քանի սյունակ՝ համոզվելու համար, որ հիմնական բանալին եզակի է, կամ կարող եք փորձել օպտիմալացնել հաճախակի կանչվող հարցումների կատարումը բազմաթիվ սյունակներում: Ընդհանուր առմամբ, այնուամենայնիվ, որքան շատ հիմնական սյունակներ պարունակի ինդեքսը, այնքան ավելի քիչ արդյունավետ կլինի ինդեքսը, ինչը նշանակում է, որ կոմպոզիտային ինդեքսները պետք է խելամիտ օգտագործվեն:
Ինչպես նշվեց, հարցումը կարող է մեծապես օգուտ քաղել, եթե բոլոր պահանջվող տվյալները անմիջապես տեղակայվեն ինդեքսի թերթերում, ինչպես ինքնին ինդեքսը: Դա խնդիր չէ կլաստերային ինդեքսի համար, քանի որ բոլոր տվյալները արդեն կան (այդ իսկ պատճառով շատ կարևոր է ուշադիր մտածել կլաստերային ինդեքս ստեղծելիս): Բայց տերևների վրա ոչ կլաստերային ինդեքսը պարունակում է միայն հիմնական սյունակներ: Բոլոր մյուս տվյալներին մուտք գործելու համար հարցումների օպտիմիզատորը պահանջում է լրացուցիչ քայլեր, որոնք կարող են զգալի ծախսեր ավելացնել ձեր հարցումների կատարմանը:
Այստեղ է, որ օգնության է հասնում ծածկույթի ինդեքսը: Երբ դուք սահմանում եք ոչ կլաստերային ինդեքս, կարող եք նշել լրացուցիչ սյունակներ ձեր հիմնական սյունակների համար: Օրինակ, ենթադրենք, որ ձեր հավելվածը հաճախ է հարցումներ անում սյունակի տվյալների վրա Պատվերի IDԵվ Պատվերի ամսաթիվըաղյուսակում Վաճառք:
Դուք կարող եք ստեղծել բարդ ոչ կլաստերային ինդեքս երկու սյունակներում, սակայն OrderDate սյունակը կավելացնի միայն ինդեքսի պահպանման ծախսերը՝ առանց ծառայելու որպես հատկապես օգտակար հիմնական սյունակ: Լավագույն լուծումը կլինի առանցքային սյունակի վրա ծածկող ինդեքս ստեղծելը Պատվերի IDև լրացուցիչ ներառված սյունակ Պատվերի ամսաթիվը:
CREATE NONCLUSTERED INDEX ix_orderid ON dbo.Sales(OrderID) INCLUDE (OrderDate);Սա խուսափում է ավելորդ սյունակների ինդեքսավորման թերություններից՝ միևնույն ժամանակ պահպանելով հարցումները գործարկելիս տերևներում տվյալների պահպանման առավելությունները: Ներառված սյունակը բանալու մաս չէ, բայց տվյալները պահվում են տերևի հանգույցում՝ ինդեքսի թերթիկում։ Սա կարող է բարելավել հարցումների կատարումը առանց լրացուցիչ ծախսերի: Բացի այդ, ծածկույթի ինդեքսում ներառված սյունակները ենթակա են ավելի քիչ սահմանափակումների, քան ինդեքսի հիմնական սյունակները:
Արդյո՞ք կարևոր է հիմնական սյունակում կրկնօրինակների քանակը:
Երբ դուք ստեղծում եք ինդեքս, դուք պետք է փորձեք նվազեցնել կրկնօրինակների թիվը ձեր հիմնական սյունակներում: Ավելի ճիշտ՝ փորձեք հնարավորինս ցածր պահել կրկնությունների մակարդակը:
Եթե դուք աշխատում եք կոմպոզիտային ինդեքսով, ապա կրկնօրինակումը վերաբերում է բոլոր հիմնական սյունակներին որպես ամբողջություն: Մեկ սյունակը կարող է պարունակել բազմաթիվ կրկնօրինակ արժեքներ, բայց բոլոր ինդեքսի սյունակների միջև պետք է լինի նվազագույն կրկնություն: Օրինակ, դուք ստեղծում եք բարդ ոչ կլաստերային ինդեքս սյունակների վրա ԱնունԵվ Ազգանուն, դուք կարող եք ունենալ շատ John Doe արժեքներ և շատ Doe արժեքներ, բայց ցանկանում եք ունենալ որքան հնարավոր է քիչ John Doe արժեքներ, կամ գերադասելի է ընդամենը մեկ John Doe արժեք:
Հիմնական սյունակի արժեքների եզակիության հարաբերակցությունը կոչվում է ինդեքսի ընտրողականություն: Որքան շատ են եզակի արժեքները, այնքան բարձր է ընտրողականությունը. եզակի ինդեքսն ունի առավելագույն հնարավոր ընտրողականություն: Հարցման շարժիչը իսկապես սիրում է բարձր ընտրողականության արժեքներով սյունակներ, հատկապես, եթե այդ սյունակները ներառված են ձեր ամենահաճախ կատարվող հարցումների WHERE կետերում: Որքան ընտրովի է ինդեքսը, այնքան ավելի արագ է հարցումների շարժիչը կարող նվազեցնել ստացված տվյալների հավաքածուի չափը: Բացասական կողմն, իհարկե, այն է, որ համեմատաբար քիչ եզակի արժեքներով սյունակները հազվադեպ են ինդեքսավորման լավ թեկնածուներ լինելու:
Հնարավո՞ր է ոչ կլաստերային ինդեքս ստեղծել հիմնական սյունակի տվյալների միայն որոշակի ենթաբազմության վրա:
Լռելյայնորեն, ոչ կլաստերային ինդեքսը պարունակում է մեկ տող աղյուսակի յուրաքանչյուր տողի համար: Իհարկե, նույն բանը կարող եք ասել կլաստերային ինդեքսի մասին՝ ենթադրելով, որ նման ցուցանիշը աղյուսակ է։ Բայց երբ խոսքը վերաբերում է ոչ կլաստերային ինդեքսին, մեկ առ մեկ հարաբերությունը կարևոր հասկացություն է, քանի որ, սկսած տարբերակից. SQL Server 2008 թ, դուք հնարավորություն ունեք ստեղծելու զտվող ինդեքս, որը սահմանափակում է դրանում ներառված տողերը։ Զտված ինդեքսը կարող է բարելավել հարցումների կատարումը, քանի որ... այն չափսերով ավելի փոքր է և պարունակում է զտված, ավելի ճշգրիտ վիճակագրություն, քան բոլոր աղյուսակայինները, ինչը հանգեցնում է կատարման բարելավված պլանների ստեղծմանը: Զտված ինդեքսը նաև պահանջում է ավելի քիչ պահեստային տարածք և պահպանման ավելի ցածր ծախսեր: Ցուցանիշը թարմացվում է միայն այն ժամանակ, երբ փոխվում են ֆիլտրին համապատասխանող տվյալները:
Բացի այդ, ֆիլտրվող ինդեքսը հեշտ է ստեղծել: Օպերատորում ՍՏԵՂԾԵԼ ԻԴԵՔՍդուք պարզապես պետք է նշեք ՈՐՏԵՂֆիլտրի վիճակը. Օրինակ, դուք կարող եք զտել NULL պարունակող բոլոր տողերը ինդեքսից, ինչպես ցույց է տրված կոդում.
Մենք, փաստորեն, կարող ենք զտել ցանկացած տվյալ, որը կարևոր չէ կարևոր հարցումներում: Բայց զգույշ եղեք, քանի որ... SQL Serverմի քանի սահմանափակումներ է դնում զտվող ինդեքսների վրա, օրինակ՝ դիտման վրա զտվող ինդեքս ստեղծելու անկարողությունը, այնպես որ ուշադիր կարդացեք փաստաթղթերը:
Հնարավոր է նաև, որ դուք կարող եք նմանատիպ արդյունքների հասնել՝ ստեղծելով ինդեքսավորված տեսք: Այնուամենայնիվ, զտված ինդեքսն ունի մի քանի առավելություններ, ինչպիսիք են սպասարկման ծախսերը նվազեցնելու և ձեր կատարողական ծրագրերի որակը բարելավելու ունակությունը: Զտված ինդեքսները կարող են նաև վերակառուցվել առցանց: Փորձեք սա ինդեքսավորված տեսքով:
6. Ցուցանիշներ և կատարողականի օպտիմալացում
Ցուցանիշները տվյալների բազաներում. նպատակը, ազդեցությունը կատարողականի վրա, ինդեքսների ստեղծման սկզբունքները
6.1 Ինչի՞ համար են ինդեքսները:
Ինդեքսները տվյալների բազաներում հատուկ կառուցվածքներ են, որոնք թույլ են տալիս արագացնել որոնումը և տեսակավորումն ըստ որոշակի դաշտի կամ աղյուսակի դաշտերի շարքի, ինչպես նաև օգտագործվում են տվյալների եզակիությունը ապահովելու համար: Ցուցանիշները համեմատելու ամենահեշտ ձևը գրքերի ինդեքսների հետ է: Եթե ինդեքս չկա, ապա մենք պետք է նայենք ամբողջ գիրքը՝ ճիշտ տեղը գտնելու համար, բայց ինդեքսով նույն գործողությունը կարելի է շատ ավելի արագ կատարել։
Սովորաբար, որքան շատ ինդեքսներ լինեն, այնքան ավելի լավ կլինի տվյալների բազայի հարցումների կատարումը: Այնուամենայնիվ, եթե ինդեքսների թիվը չափազանց մեծանում է, տվյալների փոփոխման գործողությունների կատարումը (տեղադրում/փոխում/ջնջում) նվազում է, և տվյալների բազայի չափը մեծանում է, ուստի ինդեքսների ավելացմանը պետք է զգուշությամբ վերաբերվել:
Ինդեքսների ստեղծման հետ կապված որոշ ընդհանուր սկզբունքներ.
· ինդեքսները պետք է ստեղծվեն միացումներում օգտագործվող սյունակների համար, որոնք հաճախ օգտագործվում են որոնման և տեսակավորման գործողությունների համար: Խնդրում ենք նկատի ունենալ, որ ինդեքսները միշտ ավտոմատ կերպով ստեղծվում են այն սյունակների համար, որոնք ենթակա են հիմնական բանալիների սահմանափակումների: Ամենից հաճախ դրանք ստեղծվում են օտար բանալիով սյունակների համար (Access-ում՝ ավտոմատ կերպով);
· Ինդեքսը պետք է ավտոմատ կերպով ստեղծվի սյունակների համար, որոնք ենթակա են եզակիության սահմանափակումների.
· Լավագույնն այն է, որ ինդեքսներ ստեղծվեն այն դաշտերի համար, որոնցում կա կրկնվող արժեքների նվազագույն քանակ և տվյալները հավասարաչափ բաշխված են: Oracle-ն ունի հատուկ բիթային ինդեքսներ մեծ թվով կրկնօրինակ արժեքներով սյունակների համար, և Access-ը չեն տրամադրում այս տեսակի ինդեքսը.
· եթե որոնումը մշտապես իրականացվում է սյունակների որոշակի հավաքածուի վրա (միաժամանակ), ապա այս դեպքում կարող է իմաստ ունենալ ստեղծել կոմպոզիտային ինդեքս (միայն SQL Server-ում)՝ մեկ ինդեքս սյունակների խմբի համար.
· Երբ աղյուսակներում փոփոխություններ են կատարվում, այս աղյուսակի վրա դրված ինդեքսներն ինքնաբերաբար փոխվում են: Արդյունքում, ինդեքսը կարող է խիստ մասնատված լինել, ինչը ազդում է կատարողականի վրա: Դուք պետք է պարբերաբար ստուգեք ինդեքսի մասնատման աստիճանը և դրանք վերափոխեք: Մեծ քանակությամբ տվյալներ բեռնելիս երբեմն իմաստ ունի նախ ջնջել բոլոր ինդեքսները և նորից ստեղծել դրանք գործողությունն ավարտելուց հետո.
· ինդեքսները կարող են ստեղծվել ոչ միայն աղյուսակների, այլ նաև դիտումների համար (միայն SQL Server-ում): Առավելությունները - դաշտերը հաշվարկելու հնարավորությունը ոչ թե հարցման պահին, այլ այն պահին, երբ աղյուսակներում հայտնվում են նոր արժեքներ:
Այս հոդվածում քննարկվում են ինդեքսները և դրանց դերը հարցումների կատարման ժամանակի օպտիմալացման գործում: Հոդվածի առաջին մասում քննարկվում են ինդեքսների տարբեր ձևերը և դրանց պահպանման եղանակները: Հաջորդը, մենք ուսումնասիրում ենք երեք հիմնական Transact-SQL հայտարարությունները, որոնք օգտագործվում են ինդեքսների հետ աշխատելու համար՝ CREATE INDEX, ALTER INDEX և DROP INDEX: Այնուհետև դիտարկվում է համակարգի աշխատանքի վրա դրա ազդեցության ինդեքսների մասնատումը: Այնուհետև այն տրամադրում է որոշ ընդհանուր ուղեցույցներ ինդեքսների ստեղծման համար և նկարագրում է ինդեքսների մի քանի հատուկ տեսակներ:
Ընդհանուր տեղեկություն
Տվյալների բազայի համակարգերը սովորաբար օգտագործում են ինդեքսներ՝ հարաբերական տվյալներին արագ մուտք ապահովելու համար: Ինդեքսը տվյալների առանձին ֆիզիկական կառուցվածք է, որը թույլ է տալիս արագ մուտք գործել տվյալների մեկ կամ մի քանի տող: Այսպիսով, ինդեքսների ճիշտ կարգավորումը հարցումների կատարողականի բարելավման հիմնական ասպեկտն է:
Տվյալների բազայի ինդեքսը շատ առումներով նման է գրքի ինդեքսին (այբբենական ինդեքս): Երբ մեզ անհրաժեշտ է արագ թեմա գտնել գրքում, սկզբում նայում ենք ինդեքսում, թե գրքի որ էջերում է քննարկվում այս թեման, ապա անմիջապես բացում ենք ցանկալի էջը։ Նմանապես, աղյուսակում որոշակի տող որոնելիս Database Engine-ը մուտք է գործում ինդեքս՝ գտնելու դրա ֆիզիկական գտնվելու վայրը:
Բայց գրքի ինդեքսի և տվյալների բազայի ինդեքսի միջև կա երկու էական տարբերություն.
Գրքի ընթերցողը հնարավորություն ունի ինքնուրույն որոշել՝ օգտագործե՞լ ցուցիչը յուրաքանչյուր կոնկրետ դեպքում, թե՞ ոչ։ Տվյալների բազայի օգտատերը չունի այս հնարավորությունը, և նրա համար այս որոշումը կայացվում է համակարգային բաղադրիչի միջոցով, որը կոչվում է հարցումների օպտիմիզատոր. (Օգտագործողը կարող է շահարկել ինդեքսների օգտագործումը ինդեքսի ակնարկների միջոցով, սակայն այս ակնարկները խորհուրդ են տրվում օգտագործել միայն սահմանափակ թվով հատուկ դեպքերում):
Աշխատանքային գրքի հետ մեկտեղ ստեղծվում է կոնկրետ աշխատանքային գրքի ինդեքսը, որից հետո այն այլևս չի փոփոխվում: Սա նշանակում է, որ կոնկրետ թեմայի ինդեքսը միշտ ցույց կտա նույն էջի համարը: Ի հակադրություն, տվյալների բազայի ինդեքսը կարող է փոխվել, երբ համապատասխան տվյալները փոխվեն:
Եթե աղյուսակը չունի համապատասխան ինդեքս, համակարգը օգտագործում է աղյուսակի սկանավորման մեթոդ՝ տողերը առբերելու համար: Արտահայտություն սեղանի սկանավորումնշանակում է, որ համակարգը հաջորդաբար առբերում և ուսումնասիրում է աղյուսակի յուրաքանչյուր տող (առաջինից մինչև վերջին), և տողը տեղադրում է արդյունքների հավաքածուում, եթե WHERE կետի որոնման պայմանը բավարարված է դրա համար: Այսպիսով, բոլոր տողերը վերցվում են հիշողության մեջ իրենց ֆիզիկական դիրքի համաձայն: Այս մեթոդը ավելի քիչ արդյունավետ է, քան ինդեքսների միջոցով հասանելիությունը, ինչպես բացատրվում է ստորև:
Ինդեքսները պահվում են տվյալների բազայի լրացուցիչ կառուցվածքներում, որոնք կոչվում են ինդեքսային էջեր. Յուրաքանչյուր ինդեքսավորված տողի համար կա ինդեքսի մուտքագրում, որը պահվում է ինդեքսի էջում։ Ինդեքսի յուրաքանչյուր տարր բաղկացած է ինդեքսային բանալիից և ինդեքսից: Ահա թե ինչու ինդեքսի տարրը զգալիորեն ավելի կարճ է, քան այն աղյուսակի տողը, որին նա ցույց է տալիս: Այս պատճառով, յուրաքանչյուր ինդեքսային էջում ինդեքսային տարրերի թիվը շատ ավելի մեծ է, քան տվյալների էջի տողերի թիվը:
Ինդեքսների այս հատկությունը շատ կարևոր է, քանի որ ինդեքսի էջերը անցնելու համար պահանջվող I/O գործառնությունների թիվը զգալիորեն պակաս է, քան համապատասխան տվյալների էջերը անցնելու համար պահանջվող I/O գործողությունների քանակը: Այլ կերպ ասած, աղյուսակի սկանավորումը հավանաբար կպահանջի շատ ավելի շատ I/O գործողություններ, քան աղյուսակի ինդեքսը սկանավորելը:
Տվյալների բազայի շարժիչի ինդեքսները ստեղծվում են B+ ծառի տվյալների կառուցվածքի միջոցով: B+ ծառն ունի ծառի կառուցվածք, որտեղ բոլոր ամենաներքևի հանգույցները նույն թվով մակարդակներով հեռու են ծառի վերևից (արմատային հանգույցից): Այս հատկությունը պահպանվում է նույնիսկ այն ժամանակ, երբ տվյալները ավելացվում կամ հեռացվում են ինդեքսավորված սյունակից:
Ստորև բերված նկարը ցույց է տալիս B+ ծառի կառուցվածքը Employee աղյուսակի համար և ուղղակի մուտք դեպի այդ աղյուսակի 25348 արժեքով Id սյունակի համար նախատեսված տողը: (Մենք ենթադրում ենք, որ Employee աղյուսակը ինդեքսավորվում է Id սյունակով:) Այս նկարում կարող եք նաև տեսնել, որ B+ ծառը բաղկացած է արմատային հանգույցից, ծառի հանգույցներից և զրո կամ ավելի միջանկյալ հանգույցներից.
Դուք կարող եք որոնել այս ծառի համար 25348 արժեքը հետևյալ կերպ. Ծառի արմատից սկսած՝ այն փնտրում է պահանջվող արժեքից մեծ կամ հավասար ամենափոքր բանալի արժեքը: Այսպիսով, արմատային հանգույցում այս արժեքը կլինի 29346, ուստի անցում է կատարվում այս արժեքի հետ կապված միջանկյալ հանգույցին։ Այս հանգույցում 28559 արժեքը համապատասխանում է նշված պահանջներին, ինչի արդյունքում անցում է կատարվում այս արժեքի հետ կապված ծառի հանգույցին։ Այս հանգույցը պարունակում է 25348 ցանկալի արժեքը: Որոշելով անհրաժեշտ ինդեքսը, մենք կարող ենք դրա տողը հանել տվյալների աղյուսակից՝ օգտագործելով համապատասխան ցուցիչներ: (Այլընտրանքային համարժեք մոտեցումը կլինի ինդեքսից փոքր կամ հավասար արժեքի որոնումը:)
Ինդեքսավորված որոնումը սովորաբար նախընտրելի մեթոդ է մեծ թվով տողերով աղյուսակների որոնման համար՝ իր ակնհայտ առավելությունների պատճառով: Օգտագործելով ինդեքսավորված որոնումը, մենք կարող ենք շատ կարճ ժամանակում գտնել աղյուսակի ցանկացած տող՝ օգտագործելով միայն մի քանի I/O գործողություններ: Իսկ հաջորդական որոնումը (այսինքն՝ աղյուսակի սկանավորումն առաջին շարքից մինչև վերջինը) ավելի շատ ժամանակ է պահանջում, որքան հեռու է պահանջվող տողը:
Հետևյալ բաժիններում մենք կդիտարկենք երկու գոյություն ունեցող ինդեքսների՝ կլաստերային և ոչ կլաստերային, և կսովորենք, թե ինչպես ստեղծել ինդեքսներ:
Կլաստերային ինդեքսներ
Կլաստերային ինդեքսորոշում է աղյուսակի տվյալների ֆիզիկական կարգը. Տվյալների բազայի շարժիչը թույլ է տալիս աղյուսակի համար ստեղծել միայն մեկ կլաստերային ինդեքս, քանի որ Սեղանի տողերը ֆիզիկապես չեն կարող դասավորվել մեկից ավելի եղանակներով: Կլաստերային ինդեքսի օգտագործմամբ որոնումն իրականացվում է B+ ծառի արմատային հանգույցից դեպի ծառի այն հանգույցները, որոնք միմյանց հետ կապված են կրկնակի կապված ցանկում, որը կոչվում է. էջերի շղթա.
Կլաստերային ինդեքսի կարևոր հատկությունն այն է, որ նրա ծառի հանգույցները պարունակում են տվյալների էջեր: (Կլաստերավորված ինդեքսային հանգույցների բոլոր մյուս մակարդակները պարունակում են ինդեքսային էջեր:) Աղյուսակը, որն ունի կլաստերային ինդեքս սահմանված (բացի կամ անուղղակիորեն), կոչվում է կլաստերացված աղյուսակ: Կլաստերային ինդեքսի B+ ծառի կառուցվածքը ներկայացված է ստորև բերված նկարում.

Յուրաքանչյուր աղյուսակի վրա լռելյայնորեն ստեղծվում է կլաստերային ինդեքս, որն ունի հիմնական բանալի, որը սահմանվում է հիմնական բանալի սահմանափակմամբ: Բացի այդ, յուրաքանչյուր կլաստերային ինդեքս լռելյայն եզակի է, այսինքն. Սյունակում, որն ունի կլաստերային ինդեքս սահմանված, յուրաքանչյուր տվյալների արժեք կարող է հայտնվել միայն մեկ անգամ: Եթե կրկնօրինակ արժեքներ պարունակող սյունակի վրա ստեղծվում է կլաստերային ինդեքս, տվյալների բազայի համակարգը կիրառում է միանշանակություն՝ չորս բայթանոց նույնացուցիչ ավելացնելով կրկնօրինակ արժեքներ պարունակող տողերին:
Կլաստերային ինդեքսներն ապահովում են տվյալների շատ արագ հասանելիություն, երբ հարցումը որոնում է արժեքների շարք:
Ոչ կլաստերային ինդեքսներ
Ոչ կլաստերային ինդեքսի կառուցվածքը ճիշտ նույնն է, ինչ կլաստերային ինդեքսը, բայց երկու կարևոր տարբերություններով.
ոչ կլաստերային ինդեքսը չի փոխում աղյուսակի տողերի ֆիզիկական դասավորությունը.
Ոչ կլաստերային ինդեքսային հանգույցի էջերը բաղկացած են ինդեքսային ստեղներից և էջանիշներից:
Եթե աղյուսակի վրա սահմանեք մեկ կամ մի քանի ոչ կլաստերային ինդեքսներ, աղյուսակի տողերի ֆիզիկական կարգը չի փոխվի: Յուրաքանչյուր ոչ կլաստերային ինդեքսի համար Database Engine-ը ստեղծում է լրացուցիչ ինդեքսային կառուցվածք, որը պահվում է ինդեքսային էջերում: Ոչ կլաստերային ինդեքսի B+ ծառի կառուցվածքը ներկայացված է ստորև բերված նկարում.

Ոչ կլաստերային ինդեքսում էջանիշը ցույց է տալիս, թե որտեղ է գտնվում ինդեքսի ստեղնին համապատասխանող տողը: Ինդեքսի բանալի էջանիշի բաղադրիչը կարող է լինել երկու տեսակի՝ կախված նրանից՝ աղյուսակը կլաստերային աղյուսակ է, թե կույտ: (SQL Server տերմինաբանության մեջ կույտը աղյուսակ է առանց կլաստերային ինդեքսի:) Եթե գոյություն ունի կլաստերային ինդեքս, ապա ոչ կլաստերային ինդեքսի ներդիրը ցույց է տալիս աղյուսակի կլաստերացված ինդեքսի B+ ծառը: Եթե աղյուսակը չունի կլաստերային ինդեքս, ապա էջանիշը նույնական է տողի նույնացուցիչ (RID - Տողի նույնացուցիչ), որը բաղկացած է երեք մասից՝ ֆայլի հասցեն, որում պահվում է աղյուսակը, ֆիզիկական բլոկի (էջի) հասցեն, որտեղ պահվում է տողը, և էջի տողի օֆսեթը։
Ինչպես նշվեց ավելի վաղ, ոչ կլաստերային ինդեքսով տվյալների որոնումը կարող է իրականացվել երկու տարբեր եղանակներով՝ կախված աղյուսակի տեսակից.
heap - անցնել ոչ կլաստերային ինդեքսի որոնման կառուցվածքը, որից հետո տողը վերցվում է տողի նույնացուցիչի միջոցով.
կլաստերացված աղյուսակ - ոչ կլաստերային ինդեքսային կառուցվածքի որոնման անցում, որին հաջորդում է համապատասխան կլաստերային ինդեքսի անցում:
Երկու դեպքում էլ I/O գործողությունների քանակը բավականին մեծ է, այնպես որ դուք պետք է զգուշությամբ նախագծեք ոչ կլաստերային ինդեքս և օգտագործեք այն միայն այն դեպքում, եթե վստահ եք, որ դրա օգտագործումը զգալիորեն կբարելավի կատարումը:
Transact-SQL լեզուն և ինդեքսները
Այժմ, երբ մենք ծանոթ ենք ինդեքսների ֆիզիկական կառուցվածքին, այս բաժնում մենք կանդրադառնանք, թե ինչպես ստեղծել, փոփոխել և ջնջել ինդեքսները, ինչպես նաև ինչպես ստանալ ինդեքսների մասնատման տեղեկատվություն և խմբագրել ինդեքսի տեղեկատվությունը: Այս ամենը մեզ կնախապատրաստի համակարգի գործունեության բարելավման համար ինդեքսների օգտագործման հետագա քննարկմանը:
Ինդեքսների ստեղծում
Սեղանի վրա ինդեքսը ստեղծվում է հայտարարության միջոցով ՍՏԵՂԾԵԼ ԻԴԵՔՍ. Այս հրահանգն ունի հետևյալ շարահյուսությունը.
CREATE INDEX index_name ON table_name (column1 ,...) [ INNCLUDE (column_name [,... ]) ] [[, ] PAD_INDEX = (ON | OFF)] [[, ] DROP_EXISTING = (ON | OFF)] [[ , ] SORT_IN_TEMPDB = (ՄԻԱՑՎԱԾ | ԱՆՋԱՏՎԱԾ)] [[, ] IGNORE_DUP_KEY = (ՄԻԱՑՎԱԾ Է STATISTICS_NORECOMPUTE = (ՄԻԱՑՎԱԾ Է
index_name պարամետրը նշում է ստեղծվելիք ինդեքսի անվանումը: Ցուցանիշը կարող է ստեղծվել մեկ կամ մի քանի սյունակների վրա, որոնք նույնականացվում են table_name պարամետրով: Սյունակը, որի վրա ստեղծվում է ինդեքսը, նշվում է սյունակ1 պարամետրով: Այս պարամետրի թվային վերջածանցը ցույց է տալիս, որ ինդեքսը կարող է ստեղծվել աղյուսակի մի քանի սյունակների վրա: Տվյալների բազայի շարժիչը նաև աջակցում է դիտումների վրա ինդեքսների ստեղծմանը:
Դուք կարող եք ինդեքսավորել ցանկացած աղյուսակի սյունակ: Սա նշանակում է, որ VARBINARY(max), BIGINT և SQL_VARIANT տվյալների տիպի արժեքներ պարունակող սյունակները նույնպես կարող են ինդեքսավորվել:
Ցուցանիշը կարող է լինել պարզ կամ բաղադրյալ: Պարզ ինդեքսը ստեղծվում է մեկ սյունակի վրա, մինչդեռ բարդ ինդեքսը ստեղծվում է մի քանի սյունակների վրա: Բաղադրյալ ինդեքսն ունի որոշակի սահմանափակումներ՝ կապված իր չափի և սյունակների քանակի հետ: Ցուցանիշը կարող է ունենալ առավելագույնը 900 բայթ և առավելագույնը 16 սյունակ:
ՅՈՒՐԱՔԱՆԱԿԱՆ պարամետրնշում է, որ ինդեքսավորված սյունակը կարող է պարունակել միայն միարժեք (այսինքն՝ չկրկնվող) արժեքներ։ Մեկ արժեք ունեցող կոմպոզիտային ինդեքսում եզակիը պետք է լինի յուրաքանչյուր տողի բոլոր սյունակների արժեքների համադրությունը: Եթե UNIQUE հիմնաբառը նշված չէ, ապա ինդեքսավորված սյունակ(ներ)ում թույլատրվում են կրկնօրինակ արժեքներ:
CLUSTERED պարամետրսահմանում է կլաստերային ինդեքս, և NONCLUSTERED պարամետր(լռելյայն) նշում է, որ ինդեքսը չի փոխում աղյուսակի տողերի հերթականությունը: Տվյալների բազայի շարժիչը թույլ է տալիս աղյուսակի վրա առավելագույնը 249 ոչ կլաստերային ինդեքս:
Տվյալների բազայի շարժիչը բարելավվել է սյունակների արժեքների նվազման կարգով ինդեքսներին աջակցելու համար: Սյունակի անունից հետո ASC պարամետրը նշում է, որ ինդեքսը ստեղծվում է սյունակի արժեքների աճման կարգով, իսկ DESC պարամետրը նշում է ինդեքսի սյունակի արժեքների նվազման կարգը: Սա ավելի մեծ ճկունություն է ապահովում ինդեքսի օգտագործման մեջ: Նվազման կարգով դուք պետք է ստեղծեք կոմպոզիտային ինդեքսներ սյուների վրա, որոնց արժեքները դասավորված են հակառակ ուղղություններով:
Ներառում է պարամետրըԹույլ է տալիս նշել ոչ առանցքային սյունակներ, որոնք ավելացվում են ոչ կլաստերային ինդեքսի հանգույցների էջերին: Սյունակների անունները INCLUDE ցանկում չպետք է կրկնվեն, և սյունակը չի կարող օգտագործվել և՛ որպես բանալի, և՛ առանց բանալի սյունակ:
INCLUDE պարամետրի օգտակարությունը իսկապես հասկանալու համար դուք պետք է հասկանաք, թե ինչ է դա ծածկույթի ինդեքս. Եթե հարցման բոլոր սյունակները ներառված են ինդեքսում, կարող եք զգալի կատարողական բարելավումներ ստանալ, քանի որ Հարցման օպտիմիզատորը կարող է տեղորոշել սյունակների բոլոր արժեքները ինդեքսի էջերում՝ առանց աղյուսակի տվյալներին մուտք գործելու: Այս հնարավորությունը կոչվում է ծածկող ինդեքս կամ ծածկող հարցում: Հետևաբար, ոչ կլաստերային ինդեքսային հանգույցների էջերում լրացուցիչ ոչ առանցքային սյունակներ ներառելը թույլ կտա ձեզ ավելի շատ ծածկույթի հարցումներ ստանալ և զգալիորեն բարելավել դրանց կատարումը:
FILLFACTOR պարամետրնշում է յուրաքանչյուր ինդեքսային էջի տոկոսը, որը պետք է լրացվի ինդեքսի ստեղծման պահին: FILLFACTOR պարամետրի արժեքը կարող է սահմանվել 1-ից 100 միջակայքում: n=100 արժեքով յուրաքանչյուր ինդեքսային էջ լրացվում է մինչև 100%, այսինքն. գոյություն ունեցող հանգույցի էջը, ինչպես նաև ոչ հանգույց էջը ազատ տեղ չի ունենա նոր տողեր տեղադրելու համար: Հետեւաբար, խորհուրդ է տրվում օգտագործել այս արժեքը միայն ստատիկ աղյուսակների համար: (Լռակյաց արժեքը, n=0, նշանակում է, որ ինդեքսային հանգույցի էջերը լի են, և միջանկյալ էջերից յուրաքանչյուրը պարունակում է ազատ տարածք մեկ մուտքի համար:)
Եթե FILLFACTOR պարամետրը դրված է 1-ից 99-ի արժեքների վրա, ստեղծվող ինդեքսային կառուցվածքի հանգույցի էջերը կպարունակեն ազատ տարածություն: Որքան մեծ է n-ի արժեքը, այնքան քիչ ազատ տարածք կա ինդեքսային հանգույցի էջերում։ Օրինակ, n=60 դեպքում յուրաքանչյուր ինդեքսային հանգույցի էջ կունենա 40% ազատ տարածք ապագա ինդեքսի տողերի տեղադրման համար: (Ինդեքսի տողերը տեղադրվում են INSERT կամ UPDATE դրույթների միջոցով:) Այսպիսով, n=60 արժեքը ողջամիտ կլինի այն աղյուսակների համար, որոնց տվյալները բավականին հաճախ են փոխվում: 1-ից 99-ի FILLFACTOR արժեքների համար միջանկյալ ինդեքսային էջերը պարունակում են ազատ տարածք յուրաքանչյուր մեկ մուտքի համար:
Երբ ինդեքսը ստեղծվի, FILLFACTOR արժեքը չի ապահովվում օգտագործման ընթացքում: Այլ կերպ ասած, այն ցույց է տալիս միայն առկա տվյալների հետ վերապահված տարածքի քանակը ազատ տարածության տոկոսը սահմանելիս: FILLFACTOR պարամետրն իր սկզբնական արժեքին վերականգնելու համար օգտագործեք ALTER INDEX հայտարարությունը:
PAD_INDEX պարամետրսերտորեն կապված է FILLFACTOR պարամետրի հետ: FILLFACTOR պարամետրը հիմնականում սահմանում է ազատ տարածության քանակը՝ որպես ինդեքսային հանգույցների էջի ընդհանուր չափի տոկոս: Իսկ PAD_INDEX պարամետրը նշում է, որ FILLFACTOR պարամետրի արժեքը վերաբերում է ինչպես ինդեքսային էջերին, այնպես էլ ինդեքսում գտնվող տվյալների էջերին:
DROP_EXISTING պարամետրԹույլ է տալիս բարելավել կատարումը, երբ վերարտադրում եք կլաստերային ինդեքս սեղանի վրա, որն ունի նաև ոչ կլաստերային ինդեքս: Լրացուցիչ տեղեկությունների համար տե՛ս ստորև բերված «Ինդեքսի վերակառուցում» բաժինը:
SORT_IN_TEMPDB պարամետրօգտագործվում է միջանկյալ տեսակավորման գործողությունների տվյալները tempdb համակարգի տվյալների բազայում ինդեքսի ստեղծման ժամանակ օգտագործվող տվյալների տեղադրման համար: Սա կարող է բարելավել կատարումը, եթե tempdb-ը գտնվում է տվյալներից տարբեր սկավառակի վրա:
IGNORE_DUP_KEY պարամետրԹույլ է տալիս համակարգին անտեսել ինդեքսավորված սյունակներում կրկնօրինակ արժեքներ տեղադրելու փորձը: Այս տարբերակը պետք է օգտագործվի միայն երկարաժամկետ գործարքի ընդհատումից խուսափելու համար, երբ INSERT հայտարարությունը կրկնօրինակ տվյալներ է տեղադրում ինդեքսավորված սյունակում: Երբ այս տարբերակը միացված է, երբ INSERT հայտարարությունը փորձում է աղյուսակում տողեր մտցնել, որոնք խախտում են ինդեքսի եզակիությունը, տվյալների բազայի համակարգը պարզապես նախազգուշացում է տալիս՝ ամբողջ հայտարարությունը խափանելու փոխարեն: Այս դեպքում տվյալների բազայի շարժիչը չի տեղադրում կրկնօրինակ հիմնական արժեքներով տողեր, այլ պարզապես անտեսում է դրանք և ավելացնում է ճիշտ տողերը: Եթե այս պարամետրը սահմանված չէ, ապա ամբողջ հրահանգի կատարումը աննորմալ կերպով կավարտվի:
Երբ ALLOW_ROW_LOCKS պարամետրակտիվացված (միացված է), համակարգը կիրառում է տողերի կողպումը: Նմանապես, երբ ակտիվացված է ALLOW_PAGE_LOCKS պարամետր, համակարգը կիրառում է էջի կողպում միաժամանակյա մուտքի ժամանակ: STATISTICS_NORECOMPUTE պարամետրորոշում է վիճակագրության ավտոմատ վերահաշվարկի վիճակը նշված ցուցանիշի համար:
Ակտիվացված է ONLINE պարամետրթույլ է տալիս ստեղծել, վերստեղծել և ջնջել ինդեքսը երկխոսության ռեժիմում: Այս տարբերակը թույլ է տալիս միաժամանակ փոխել հիմնական աղյուսակի կամ կլաստերային ինդեքսի տվյալները և ցանկացած հարակից ինդեքս՝ ինդեքսը փոխելիս: Օրինակ, մինչ կլաստերային ինդեքսը վերստեղծվում է, դուք կարող եք շարունակել թարմացնել դրա տվյալները և հարցումներ կատարել այդ տվյալների վրա:
Պարամետրը միացված էստեղծում է նշված ինդեքսը կամ լռելյայն ֆայլի խմբի (կանխադրված արժեք) կամ նշված ֆայլի խմբի վրա (file_group արժեքը):
Ստորև բերված օրինակը ցույց է տալիս, թե ինչպես կարելի է ստեղծել ոչ կլաստերային ինդեքս Employee աղյուսակի Id սյունակում.
ՕԳՏԱԳՈՐԾԵԼ SampleDb; CREATE INDEX ix_empid ON Employee (Id);
Միարժեք կոմպոզիտային ինդեքսի ստեղծումը ներկայացված է ստորև բերված օրինակում.
ՕԳՏԱԳՈՐԾԵԼ SampleDb; ՍՏԵՂԾԵԼ ԵՆՔԻ ԻԴԵՔՍ ix_empid_prnu ON Works_on (EmpId, ProjectNumber) FILLFACTOR= 80;
Այս օրինակում յուրաքանչյուր սյունակի արժեքները պետք է լինեն միանիշ: Երբ ստեղծվում է ինդեքս, յուրաքանչյուր ինդեքսային հանգույցի էջի տարածքի 80%-ը լրացվում է:
Դուք չեք կարող ստեղծել եզակի ինդեքս սյունակի վրա, եթե սյունակը կրկնօրինակ արժեքներ է պարունակում: Նման ինդեքս կարող է ստեղծվել միայն այն դեպքում, եթե յուրաքանչյուր արժեք (ներառյալ NULL արժեքները) հայտնվի սյունակում ուղիղ մեկ անգամ: Բացի այդ, գոյություն ունեցող եզակի ինդեքսում ընդգրկված սյունակում առկա տվյալների արժեքը մտցնելու կամ փոփոխելու ցանկացած փորձ համակարգը կմերժվի, եթե արժեքը կրկնօրինակվի:
Ինդեքսների մասնատման մասին տեղեկություններ ստանալը
Ինդեքսի կյանքի ընթացքում այն կարող է մասնատվել՝ անարդյունավետ դարձնելով ինդեքսային էջերում տվյալների պահպանման գործընթացը։ Գոյություն ունի ինդեքսի մասնատման երկու տեսակ՝ ներքին մասնատում և արտաքին մասնատում։ Ներքին մասնատումը որոշում է յուրաքանչյուր էջում պահվող տվյալների քանակը, մինչդեռ արտաքին մասնատումը տեղի է ունենում, երբ էջերը տրամաբանական կարգից դուրս են:
Ներքին ինդեքսի մասնատման մասին տեղեկատվություն ստանալու համար DMV-ի դինամիկ կառավարման տեսքը կոչվում է sys.dm_db_index_physical_stats. Այս DMV-ն վերադարձնում է տեղեկատվություն նշված էջի տվյալների և ինդեքսների ծավալի և մասնատման մասին: Յուրաքանչյուր էջի համար մեկ տող է վերադարձվում B+ ծառի յուրաքանչյուր մակարդակի համար: Օգտագործելով այս DMV-ն՝ դուք կարող եք տեղեկատվություն ստանալ տվյալների էջերում տողերի մասնատման աստիճանի մասին, որոնց հիման վրա կարող եք որոշել՝ արդյոք վերակազմակերպել տվյալները։
sys.dm_db_index_physical_stats տեսքի օգտագործումը ներկայացված է ստորև բերված օրինակում: (Նախքան խմբաքանակի օրինակը գործարկելը, դուք պետք է գցեք բոլոր առկա ինդեքսները Works_on աղյուսակում: Ինդեքսները բաց թողնելու համար օգտագործեք DROP INDEX հայտարարությունը, որը ցուցադրվում է ավելի ուշ:)
ՕԳՏԱԳՈՐԾԵԼ SampleDb; ՀԱՅՏԱՐԱՐԵԼ @dbId INT; ՀԱՅՏԱՐԱՐԵԼ @tabId INT; ՀԱՅՏԱՐԱՐԵԼ @indId INT; SET @dbId = DB_ID ("SampleDb"); SET @tabId = OBJECT_ID («Աշխատակից»); SELECT avg_fragmentation_in_percent, avg_page_space_used_in_percent FROM sys.dm_db_index_physical_stats (@dbId, @tabId, NULL, NULL, NULL);
Ինչպես տեսնում եք օրինակից, sys.dm_db_index_physical_stats տեսքն ունի հինգ պարամետր: Առաջին երեք պարամետրերը համապատասխանաբար սահմանում են ընթացիկ տվյալների բազայի, աղյուսակի և ինդեքսի ID-ները: Չորրորդ պարամետրը նշում է բաժանման ID-ն, իսկ վերջին պարամետրը նշում է սկանավորման մակարդակը, որն օգտագործվում է վիճակագրական տեղեկատվություն ստանալու համար: (Որոշակի պարամետրի լռելյայն արժեքը կարող է սահմանվել NULL արժեքի միջոցով):
Այս տեսակետի սյունակներից ամենակարևորներն են՝ avg_fragmentation_in_percent և avg_page_space_used_in_percent սյունակները: Առաջինը ցույց է տալիս մասնատման միջին մակարդակը որպես տոկոս, իսկ երկրորդը որոշում է զբաղեցրած տարածքի չափը որպես տոկոս:
Ինդեքսային տեղեկատվության խմբագրում
Երբ ծանոթանաք ինդեքսի մասնատման տեղեկատվությանը, ինչպես քննարկվել է նախորդ բաժնում, կարող եք խմբագրել այս և այլ ինդեքսային տեղեկությունները՝ օգտագործելով հետևյալ համակարգի գործիքները.
գրացուցակի դիտումներ sys.indexes;
կատալոգի դիտումներ sys.index_columns;
համակարգի ընթացակարգը sp_helpindex;
օբյեկտի սեփականության գործառույթները;
SQL Server Management Studio կառավարման միջավայր;
DMV դինամիկ կառավարման դիտում sys.dm_db_index_usage_stats;
DMV դինամիկ կառավարման դիտում sys.dm_db_missing_index_details:
Կատալոգի տեսք sys.indexesպարունակում է տող յուրաքանչյուր ինդեքսի համար և տող յուրաքանչյուր աղյուսակի համար՝ առանց կլաստերային ինդեքսի: Այս կատալոգի դիտման ամենակարևոր սյունակներն են՝ object_id, name և index_id սյունակները: Object_id սյունակը պարունակում է տվյալների բազայի օբյեկտի անունը, որին պատկանում է ինդեքսը, իսկ անունը և index_id սյունակները համապատասխանաբար պարունակում են այդ ինդեքսի անվանումը և ID-ն:
Կատալոգի տեսք sys.index_columnsպարունակում է տող յուրաքանչյուր սյունակի համար, որը ինդեքսի կամ կույտի մաս է: Այս տեղեկատվությունը կարող է օգտագործվել sys.indexes կատալոգի դիտման միջոցով ստացված տեղեկատվության հետ համատեղ՝ նշված ինդեքսի հատկությունների մասին լրացուցիչ տեղեկություններ ստանալու համար:
Համակարգի ընթացակարգ sp_helpindexվերադարձնում է տեղեկատվություն աղյուսակի ինդեքսների մասին, ինչպես նաև վիճակագրական տեղեկատվություն սյունակների համար: Այս ընթացակարգն ունի հետևյալ շարահյուսությունը.
sp_helpindex [@db_object = ] «անուն»
Այստեղ @db_object փոփոխականը ներկայացնում է աղյուսակի անունը։
Ինդեքսի հետ կապված՝ օբյեկտի սեփականության ֆունկցիաունի երկու հատկություն՝ IsIndexed և IsIndexable: Առաջին հատկությունը տեղեկատվություն է տալիս այն մասին, թե արդյոք աղյուսակը կամ տեսքը ունի ինդեքս, իսկ երկրորդ հատկությունը ցույց է տալիս, թե արդյոք աղյուսակը կամ տեսքը ինդեքսավորելի են:
SQL Server Management Studio-ի միջոցով գոյություն ունեցող ինդեքսային տեղեկատվությունը խմբագրելու համար տվյալների բազաների պանակում ընտրեք ցանկալի տվյալների բազան, ընդլայնեք Tables հանգույցը և այդ հանգույցում ընդլայնեք ցանկալի աղյուսակը և դրա Indexes պանակը: Աղյուսակի Indexes պանակը կցուցադրի այդ աղյուսակի բոլոր առկա ինդեքսների ցանկը: Կրկնակի սեղմելով ինդեքսի վրա, կբացվի Index Properties երկխոսության տուփը այդ ինդեքսի հատկություններով: (Դուք կարող եք նաև ստեղծել նոր ինդեքս կամ ջնջել գոյություն ունեցողը՝ օգտագործելով Management Studio):
Կատարում sys.dm_db_index_usage_statsվերադարձնում է ինդեքսային գործառնությունների տարբեր տեսակների հաշվարկ և վերջին անգամ, երբ կատարվել է յուրաքանչյուր տեսակի գործողություն: Յուրաքանչյուր առանձին որոնում, որոնում կամ թարմացում որոշակի ինդեքսի վրա մեկ հարցման մեջ համարվում է ինդեքսի օգտագործում և ավելացնում է համապատասխան հաշվիչը այդ DMV-ում մեկով: Այսպիսով, դուք կարող եք ընդհանուր տեղեկություններ ստանալ այն մասին, թե որքան հաճախ է օգտագործվում ինդեքսը, այնպես որ կարող եք օգտագործել այն՝ որոշելու համար, թե որ ինդեքսներն են ավելի շատ օգտագործվում, որոնք՝ ավելի քիչ:
Կատարում sys.dm_db_missing_index_detailsՎերադարձնում է մանրամասն տեղեկատվություն աղյուսակի սյունակների մասին, որոնց համար ինդեքսներ չկան: Այս DMV-ի ամենակարևոր սյունակներն են index_handle և object_id սյունակները: Առաջին սյունակի արժեքը նույնականացնում է կոնկրետ բացակայող ինդեքսը, իսկ երկրորդ սյունակի արժեքը նույնականացնում է աղյուսակը, որի վրա ինդեքսը բացակայում է:
Ցուցանիշների փոփոխություն
Տվյալների բազայի շարժիչը տվյալների բազայի մի քանի համակարգերից մեկն է, որն աջակցում է հայտարարությունը ՓՈՓՈԽԵԼ ԻԴԵՔՍ. Այս հայտարարությունը կարող է օգտագործվել ինդեքսի պահպանման գործողություններ կատարելու համար: ALTER INDEX հայտարարության շարահյուսությունը շատ նման է CREATE INDEX հայտարարության շարահյուսությանը: Այլ կերպ ասած, այս հայտարարությունը թույլ է տալիս փոխել ALLOW_ROW_LOCKS, ALLOW_PAGE_LOCKS, IGNORE_DUP_KEY և STATISTICS_NORECOMPUTE պարամետրերի արժեքները, որոնք ավելի վաղ նկարագրված էին CREATE INDEX հայտարարության մեջ:
Բացի վերը նշված տարբերակներից, ALTER INDEX հայտարարությունը աջակցում է երեք այլ տարբերակների.
REBUILD պարամետր, օգտագործվում է ինդեքսը վերստեղծելու համար;
Վերակազմակերպել պարամետրը, օգտագործվում է ինդեքսային հանգույցների էջերը վերակազմավորելու համար;
Անջատել պարամետրը, օգտագործվում է ինդեքսն անջատելու համար։ Այս երեք տարբերակները քննարկվում են հետևյալ ենթաբաժիններում:
Ցուցանիշի վերակառուցում
Տվյալների ցանկացած փոփոխություն՝ օգտագործելով INSERT, UPDATE կամ DELETE հայտարարությունները, կարող է հանգեցնել տվյալների մասնատման: Եթե այս տվյալները ինդեքսավորվեն, ապա հնարավոր է նաև ինդեքսի մասնատում, ինդեքսային տեղեկատվությունը ցրված տարբեր ֆիզիկական էջերում: Ինդեքսի տվյալների մասնատման արդյունքում տվյալների բազայի շարժիչը կարող է ստիպված լինել կատարել տվյալների ընթերցման լրացուցիչ գործողություններ, ինչը նվազեցնում է համակարգի ընդհանուր կատարումը: Այս դեպքում անհրաժեշտ է ՎԵՐԱԿԱՆԳՆԵԼ բոլոր մասնատված ինդեքսները:
Դա կարելի է անել երկու եղանակով.
ALTER INDEX հայտարարության REBUILD պարամետրի միջոցով;
CREATE INDEX հայտարարության DROP_EXISTING պարամետրի միջոցով:
REBUILD պարամետրն օգտագործվում է ինդեքսները վերակառուցելու համար: Եթե այս պարամետրի ինդեքսի անվան փոխարեն նշեք ԲՈԼՈՐԸ, աղյուսակի բոլոր ինդեքսները կվերստեղծվեն: (Թույլ տալով, որ ինդեքսները վերաստեղծվեն դինամիկ կերպով, դուք ստիպված չեք լինի դրանք թողնել և վերստեղծել):
CREATE INDEX հայտարարության DROP_EXISTING տարբերակը կարող է բարելավել աշխատանքը, երբ վերստեղծվում է կլաստերային ինդեքս սեղանի վրա, որն ունի նաև ոչ կլաստերային ինդեքսներ: Այն սահմանում է, որ գոյություն ունեցող կլաստերային կամ ոչ կլաստերային ինդեքսը պետք է հանվի, և նշված ինդեքսը պետք է վերստեղծվի: Ինչպես նշվեց ավելի վաղ, կլաստերացված աղյուսակի յուրաքանչյուր ոչ կլաստերային ինդեքս իր ծառի հանգույցներում պարունակում է աղյուսակի կլաստերային ինդեքսի համապատասխան արժեքները: Այդ պատճառով, երբ աղյուսակի վրա գցում եք կլաստերային ինդեքս, դուք պետք է վերստեղծեք դրա բոլոր ոչ կլաստերային ինդեքսները: DROP_EXISTING պարամետրի օգտագործումը թույլ չի տալիս նորից ստեղծել ոչ կլաստերային ինդեքսներ:
DROP_EXISTING տարբերակն ավելի հզոր է, քան REBUILD տարբերակը, քանի որ այն ավելի ճկուն է և ապահովում է մի քանի տարբերակներ, օրինակ՝ փոխել ինդեքսը կազմող սյունակները և փոխել ոչ կլաստերային ինդեքսը կլաստերայինի:
Ինդեքսային հանգույցների էջերի վերակազմավորում
ALTER INDEX հայտարարության REORGANIZE պարամետրը վերակազմավորում է հանգույցների էջերը նշված ինդեքսում այնպես, որ էջերի ֆիզիկական հերթականությունը համապատասխանի նրանց տրամաբանական կարգին՝ ձախից աջ: Սա հեռացնում է ինդեքսի մասնատման որոշակի քանակություն՝ բարելավելով ինդեքսի կատարումը:
Անջատել ինդեքսը
Անջատել տարբերակը անջատում է նշված ինդեքսը: Անջատված ինդեքսը հասանելի չէ օգտագործման համար, քանի դեռ այն նորից միացված չէ: Նկատի ունեցեք, որ անջատված ինդեքսը չի փոխվում, երբ փոխկապակցված տվյալների մեջ փոփոխություններ են կատարվում: Այդ իսկ պատճառով, անջատված ինդեքսը կրկին օգտագործելու համար այն պետք է ամբողջությամբ վերստեղծվի: Անջատված ինդեքսը միացնելու համար օգտագործեք ALTER TABLE հայտարարության REBUILD տարբերակը:
Երբ աղյուսակի վրա կլաստերային ինդեքսն անջատված է, աղյուսակի տվյալները հասանելի չեն լինի, քանի որ աղյուսակի բոլոր տվյալների էջերը կլաստերային ինդեքսով պահվում են նրա ծառի հանգույցներում:
Ինդեքսների հեռացում և վերանվանում
Ներկայիս տվյալների բազայում ինդեքսները հեռացնելու համար օգտագործեք DROP INDEX հրահանգը. Նկատի ունեցեք, որ աղյուսակի վրա կլաստերային ինդեքս թողնելը կարող է շատ ռեսուրսներ պահանջող գործողություն լինել, քանի որ Բոլոր ոչ կլաստերային ինդեքսները պետք է վերստեղծվեն: (Բոլոր ոչ կլաստերային ինդեքսներն օգտագործում են կլաստերացված ինդեքսի ինդեքսային ստեղնը որպես ցուցիչ իրենց հանգույցի էջերում):
ՕԳՏԱԳՈՐԾԵԼ SampleDb; DROP INDEX ix_empid ON Employee;
DROP INDEX հրահանգն ունի լրացուցիչ ՏԵՂԱՓՈԽԵԼ պարամետրին, որի իմաստը նույնն է, ինչ CREATE INDEX քաղվածքի ON պարամետրը։ Այլ կերպ ասած, դուք կարող եք օգտագործել այս պարամետրը, որպեսզի նշեք, թե որտեղ պետք է տեղափոխել տվյալների տողերը, որոնք գտնվում են կլաստերային ինդեքսային հանգույցների էջերում: Տվյալները տեղափոխվում են նոր վայր՝ որպես կույտ: Դուք կարող եք նշել կա՛մ լռելյայն ֆայլերի խումբ, կա՛մ անունով ֆայլերի խումբ տվյալների պահպանման նոր վայրի համար:
DROP INDEX հայտարարությունը չի կարող օգտագործվել ինդեքսները հանելու համար, որոնք անուղղակիորեն ստեղծված են համակարգի կողմից ամբողջականության սահմանափակումների համար, ինչպիսիք են PRIMARY KEY և UNIQUE ինդեքսները: Նման ինդեքսները հեռացնելու համար պետք է հեռացնել համապատասխան սահմանափակումը։
Ինդեքսները կարող են վերանվանվել՝ օգտագործելով sp_rename համակարգի ընթացակարգը:
Ինդեքսները կարող են նաև ստեղծվել, փոփոխվել և ջնջվել Management Studio-ում՝ օգտագործելով Database Diagrams կամ Object Explorer: Բայց ամենահեշտ ճանապարհը պահանջվող աղյուսակի Indexes թղթապանակն օգտագործելն է։ Management Studio-ում ինդեքսների կառավարումը նման է Management Studio-ի աղյուսակների կառավարմանը:
Թեև տվյալների բազայի շարժիչը գործնական սահմանափակում չի դնում ինդեքսների քանակի վրա, կան մի քանի պատճառ, թե ինչու պետք է սահմանափակեք թիվը: Նախ, յուրաքանչյուր ինդեքս վերցնում է որոշակի քանակությամբ սկավառակի տարածություն, ուստի հավանականություն կա, որ տվյալների բազայի ինդեքսային էջերի ընդհանուր թիվը կարող է գերազանցել տվյալների բազայի տվյալների էջերի քանակը: Երկրորդ, ի տարբերություն տվյալների առբերման համար ինդեքս օգտագործելու օգուտի, տվյալների տեղադրումն ու ջնջումը նման օգուտ չի տալիս՝ ինդեքսի պահպանման անհրաժեշտության պատճառով: Որքան շատ ինդեքսներ ունենա աղյուսակը, այնքան ավելի շատ աշխատանք է պահանջվում դրանք վերակազմավորելու համար: Որպես ընդհանուր կանոն, խելամիտ է ընտրել ինդեքսներ հաճախակի հարցումների համար, ապա գնահատել դրանց օգտագործումը:
Ինդեքսների ստեղծման և օգտագործման որոշ ուղեցույցներ տրված են այս բաժնում: Հետևյալ առաջարկությունները ընդամենը ընդհանուր կանոններ են: Ի վերջո, դրանց արդյունավետությունը կախված կլինի նրանից, թե ինչպես է տվյալների բազան օգտագործվում գործնականում և առավել հաճախ կատարվող հարցումների տեսակից: Սյունակի ինդեքսավորումը, որը երբեք չի օգտագործվի, ոչ մի օգուտ չի բերի:
Ցուցանիշները և WHERE կետի պայմանները
Եթե SELECT դրույթի WHERE դրույթը պարունակում է մեկ սյունակով որոնման պայման, ապա այդ սյունակի վրա պետք է ստեղծվի ինդեքս: Սա հատկապես խորհուրդ է տրվում բարձր ընտրողականության պայմաններում: Պայմանների ընտրողականություն ասելով մենք հասկանում ենք պայմանը բավարարող տողերի քանակի հարաբերակցությունը աղյուսակի տողերի ընդհանուր թվին: Բարձր ընտրողականությունը համապատասխանում է այս հարաբերակցության ավելի ցածր արժեքին: Ինդեքսավորված սյունակի օգտագործմամբ որոնման մշակումը առավել հաջող կլինի, երբ պայմանի ընտրողականությունը 5%-ից պակաս է:
Սյունակը չպետք է ինդեքսավորվի, եթե պայմանի ընտրողականության մակարդակը հաստատուն է 80% կամ ավելի: Այս դեպքում, ինդեքսային էջերը կպահանջեն լրացուցիչ I/O գործողություններ, որոնք կնվազեցնեն ինդեքսների օգտագործմամբ ձեռք բերված ցանկացած ժամանակի խնայողություն: Այս դեպքում ավելի արագ է որոնում կատարելը՝ սկանավորելով աղյուսակը, ինչը սովորաբար ընտրում է հարցումների օպտիմիզատորը՝ դարձնելով ինդեքսը անօգուտ:
Եթե հաճախ օգտագործվող հարցման որոնման պայմանը պարունակում է AND օպերատորներ, ապա ձեր լավագույն խաղը SELECT դրույթի WHERE կետում նշված աղյուսակի բոլոր սյունակների վրա բարդ ինդեքս ստեղծելն է: Նման կոմպոզիտային ինդեքսի ստեղծումը ներկայացված է ստորև բերված օրինակում.
Այս օրինակը ստեղծում է կոմպոզիտային ինդեքս WHERE կետի բոլոր սյունակների վրա: Այս հարցումում երկու պայման AND են միասին, այնպես որ դուք պետք է ստեղծեք բարդ ոչ կլաստերային ինդեքս երկու սյունակների վրա այս պայմաններում:
Ինդեքսները և միանալու օպերատորը
Միացման գործողության համար խորհուրդ է տրվում ստեղծել ինդեքս յուրաքանչյուր միացող սյունակի վրա: Սյունակները, որոնք միացված են, հաճախ ներկայացնում են մեկ աղյուսակի հիմնական բանալին և մեկ այլ աղյուսակի համապատասխան արտաքին բանալին: Եթե դուք համապատասխան միացման սյունակներում սահմանում եք PRIMARY KEY և FOREIGN KEY ամբողջականության սահմանափակումներ, ապա պետք է ստեղծեք միայն ոչ կլաստերային ինդեքս արտաքին բանալու սյունակում, քանի որ. համակարգը անուղղակիորեն կստեղծի կլաստերային ինդեքս առաջնային բանալին սյունակում:
Ստորև բերված օրինակը ցույց է տալիս, թե ինչպես ստեղծել ինդեքսներ, որոնք կօգտագործվեն, եթե հարցում ունենայիք միացման գործողությամբ և լրացուցիչ զտիչով.
Ծածկույթի ինդեքս
Ինչպես նշվեց ավելի վաղ, բոլոր հարցումների սյունակները ներառելով ինդեքսում, կարող են զգալիորեն բարելավել հարցումների կատարումը: Նման ցուցանիշի ստեղծումը, որը կոչվում է ծածկույթ, ներկայացված է ստորև բերված օրինակում.
ՕԳՏԱԳՈՐԾԵԼ AdventureWorks2012; GO DROP INDEX Person.Address.IX_Address_StateProvinceID; GO CREATE INDEX ix_address_zip ON Person.Address(PostCode) INCLUDE(City, StateProvinceID); GO SELECT City, StateProvinceID FROM Person.Address WHERE Postal Code = 84407;
Այս օրինակը սկզբում հեռացնում է IX_Address_StateProvinceID ինդեքսը Հասցեների աղյուսակից: Այնուհետև ստեղծվում է նոր ինդեքս, որը ներառում է երկու լրացուցիչ սյունակ, բացի փոստային ինդեքսից: Վերջապես, օրինակի վերջում SELECT հայտարարությունը ցույց է տալիս ինդեքսով ծածկված հարցումը: Այս հարցման համար համակարգը կարիք չունի տվյալների էջերում որոնել տվյալների համար, քանի որ հարցումների օպտիմիզատորը կարող է գտնել բոլոր սյունակների արժեքները ոչ կլաստերային ինդեքսային հանգույցի էջերում:
Ծածկելու ինդեքսները խորհուրդ են տրվում, քանի որ ինդեքսային էջերը սովորաբար պարունակում են շատ ավելի շատ գրառումներ, քան համապատասխան տվյալների էջերը: Բացի այդ, այս մեթոդն օգտագործելու համար զտվող սյունակները պետք է լինեն ինդեքսի առաջին հիմնական սյունակները:
Հաշվարկված սյունակների ինդեքսները
Տվյալների բազայի շարժիչը թույլ է տալիս ստեղծել հետևյալ հատուկ տեսակի ինդեքսները.
ինդեքսավորված դիտումներ;
զտվող ինդեքսներ;
ինդեքսներ հաշվարկված սյունակների վրա;
բաժանված ինդեքսներ;
սյունակի կայունության ինդեքսներ;
XML ինդեքսներ;
ամբողջական տեքստային ինդեքսներ.
Այս բաժինը քննարկում է հաշվարկված սյունակները և դրանց հետ կապված ինդեքսները:
Հաշվարկված սյունակաղյուսակի սյունակ է, որում պահվում են աղյուսակի տվյալների հաշվարկների արդյունքները: Նման սյունակը կարող է լինել վիրտուալ կամ մշտական: Այս երկու տեսակի սյունակները քննարկվում են հետևյալ ենթաբաժիններում:
Վիրտուալ հաշվարկված սյունակներ
Հաշվարկված սյունակը, որը չունի համապատասխան կլաստերային ինդեքս, տրամաբանական սյունակ է, այսինքն. այն ֆիզիկապես չի պահվում կոշտ սկավառակի վրա: Այսպիսով, այն գնահատվում է ամեն անգամ, երբ շարքը մուտք է գործում: Վիրտուալ հաշվարկված սյունակների օգտագործումը ներկայացված է ստորև բերված օրինակում.
ՕԳՏԱԳՈՐԾԵԼ SampleDb; CREATE TABLE Պատվերներ (OrderId INT NOT NULL, Price MONEY NOT NULL, Quantity INT NOT NULL, OrderDate DATETIME NOT NULL, Total AS Price * Քանակ, Առաքման ամսաթիվ AS DATEADD (ՕՐ, 7, պատվերի ամսաթիվ));
Այս օրինակի Պատվերների աղյուսակը ունի երկու վիրտուալ հաշվարկված սյունակ՝ ընդհանուր և առաքման ամսաթիվ: Ընդհանուր սյունակը հաշվարկվում է երկու այլ սյունակների՝ գնի և քանակի միջոցով, իսկ առաքման ամսաթվի սյունակը հաշվարկվում է DATEADD ֆունկցիայի և պատվերի ամսաթվի սյունակի միջոցով:
Մշտական հաշվարկված սյունակներ
Տվյալների բազայի շարժիչը թույլ է տալիս ստեղծել ինդեքսներ դետերմինիստական հաշվարկված սյունակների վրա, որտեղ հիմքում ընկած սյունակներն ունեն տվյալների ճշգրիտ տեսակներ: (Հաշվարկված սյունակը համարվում է որոշիչ, եթե այն միշտ վերադարձնում է նույն արժեքները նույն աղյուսակի տվյալների համար):
Ինդեքսավորված հաշվարկված սյունակ կարող է ստեղծվել միայն այն դեպքում, եթե SET հայտարարության հետևյալ պարամետրերը դրված են ON (այս պարամետրերը ապահովում են, որ սյունակը որոշիչ է).
QUOTED_IDENTIFIER
CONCAT_NULL_YIELDS_NULL
Բացի այդ, NUMERIC_ROUNDABORT պարամետրը պետք է անջատված լինի:
Եթե հաշվարկված սյունակի վրա ստեղծեք կլաստերային ինդեքս, սյունակի արժեքները ֆիզիկապես գոյություն կունենան համապատասխան աղյուսակի տողերում, քանի որ խմբավորված ինդեքսի հանգույցի էջերը պարունակում են տվյալների տողեր: Հետևյալ օրինակը ստեղծում է կլաստերային ինդեքս Պատվերների աղյուսակից հաշվարկված սյունակի ընդհանուրի վրա.
ՕԳՏԱԳՈՐԾԵԼ SampleDb; ՍՏԵՂԾԵԼ ԿԼԱՍՏԵՐ ԻԴԵՔՍ ix1 պատվերների վրա (ընդհանուր);
CREATE INDEX հայտարարությունը կատարելուց հետո հաշվարկված ընդհանուր սյունակը ֆիզիկապես ներկայացված կլինի աղյուսակում: Սա նշանակում է, որ հաշվարկված սյունակի հիմքում ընկած սյունակների բոլոր թարմացումները կհանգեցնեն դրա թարմացմանը:
Սյունակը կարելի է մշտական դարձնել մեկ այլ կերպ՝ օգտագործելով PERSISTED պարամետր. Այս տարբերակը թույլ է տալիս նշել հաշվարկված սյունակի ֆիզիկական ներկայությունը՝ նույնիսկ չստեղծելով համապատասխան կլաստերային ինդեքս: Այս հնարավորությունը պահանջվում է ֆիզիկական հաշվարկված սյունակներ ստեղծելու համար, որոնք ստեղծվում են տվյալների մոտավոր տեսակի (լողացող կամ իրական) սյունակների վրա: (Ինչպես նշվեց ավելի վաղ, ինդեքսը կարող է ստեղծվել միայն հաշվարկված սյունակի վրա, եթե դրա հիմքում ընկած սյունակները ճշգրիտ տվյալների տեսակից են):
Սկսնակների համար այս հոդվածում ես կանդրադառնամ, թե ինչպես կարելի է որոշել SQL հարցումների կատարման արագությունը բարձրացնելու համար անհրաժեշտ ինդեքսները:
Իրականում, կան բազմաթիվ նրբություններ, որոնք կապված են ինդեքսների հետ, որոնք կարող են էապես ազդել կատարման վրա և՛ մեկ ուղղությամբ, և՛ հակառակ ուղղությամբ: Այս մասին շատ հոդվածներ կարող եք գտնել ինտերնետում: Ծավալուն հոդվածներ, որոնք բացատրում են հասցեների, հիշողության պահպանման և շատ այլ բաների տարբերությունները:
Սրանք, իհարկե, իսկապես օգտակար բաներ են, բայց նրանք հաճախ բաց են թողնում մեկ փոքր նրբերանգ՝ տվյալների այն ծավալները, որոնց վրա այս բոլոր հատկանիշները իսկապես նկատելի ազդեցություն են ունենում: Եվ այս ցուցանիշը սովորաբար չափվում է հարյուր հազարավոր գրառումներով: Պարզ բառերով ասած, եթե ձեր աղյուսակներում ունեք մոտ 1-30 հազար գրառում, և մենք խոսում ենք կայքի (կամ նմանատիպ ռեսուրսի) մասին, այլ ոչ թե բեռնված համակարգերի համար տվյալների միջանկյալ պահպանման մասին, ապա ամենից հաճախ ավելի կարևոր է. պարզապես կառուցեք ճիշտ ինդեքսները: Այստեղ կարևոր է նշել, որ դուք պետք չէ տեխնիկապես շատ բանիմաց լինել: Շատ օգտակար ինդեքսներ կարելի է կառուցել՝ օգտագործելով պարզ տրամաբանությունը:
ՆշումՍա ենթադրում է, որ հարցումներն իրենք են կառուցված քիչ թե շատ օպտիմալ կերպով, օրինակ՝ ընտրվածում լրացուցիչ դաշտեր չկան և այլն։
Ինդեքս ամբողջ թվի նույնացուցիչ դաշտերի համար:
Եթե դուք ունեք դաշտ ամբողջ թվի նույնացուցիչով (կարևոր չէ՝ դա հենց աղյուսակի նույնացուցիչն է, թե մեկ այլ աղյուսակի տող մատնանշող նույնացուցիչ), ապա դրա համար կառուցեք առանձին ինդեքս։
Բանն այս է. Եթե դաշտը ինքնին աղյուսակի գրառումների նույնացուցիչն է, ապա մենք խոսում ենք առաջնային բանալիի մասին (դա նաև ինդեքս է): Նման ինդեքսից շատ առավելություններ կան, քանի որ կայքերն ամենից հաճախ գործում են նույնացուցիչներով։ Եթե սա տողի նույնացուցիչ է գրացուցակի աղյուսակից, ապա անհրաժեշտ է նաև ինդեքս: Քանի որ եթե ձեզ անհրաժեշտ են ֆիլտրացված տվյալներ, ապա առանց ինդեքսների այդ գրացուցակները մեծ օգուտ չեն տալիս (լավ, գուցե միայն տվյալների բազայի չափը):
Եթե առաջին դեպքում ամեն ինչ բավականին պարզ է և պարզ, ապա երկրորդ դեպքի համար (տեղեկատուով) պարզ օրինակ կբերեմ.
Ասենք երկու աղյուսակ կա՝ հոդվածներ (հոդված - id, անուն, տեքստ) և մեկնաբանություններ (մեկնաբանություն - id, article_id, տեքստ): Առաջին աղյուսակը պարունակում է 200 գրառում (հոդվածներ), երկրորդ աղյուսակը պարունակում է 2000 գրառում (10 մեկնաբանություն յուրաքանչյուր հոդվածի համար)։ Համապատասխանաբար, երբ յուրաքանչյուր օգտվող բացում է որևէ հոդված, կատարվում է հետևյալ հարցումը.
Եթե sql հարցումը կատարվում է առանց article_id դաշտի համար ինդեքսի, ապա մեկնաբանություններով ամբողջ աղյուսակը (բոլոր 2000 գրառումները) ամեն անգամ ամբողջությամբ կսկանավորվեն։ Եթե article_id դաշտի համար ավելացվի ինդեքս, ապա տվյալների բազան պետք է դիտարկի ոչ ավելի, քան 20 գրառում (ավելի ճիշտ՝ վատագույն դեպքում մոտ 18): Այստեղ հաշվարկը պարզ է. Ամենավատ դեպքում, ինդեքսի որոնումը տեղի է ունենում մոտավորապես նույն ինդեքսի դաշտի արժեքով երկուական լոգարիթմի արագությամբ: Այս դեպքում յուրաքանչյուր հոդված ունի 10 գրառում (դրանց արժեքները կրկնվում են) + log2 200-ից (քանի որ կա ընդամենը 200 հոդված = 2000 / 10) = 10 + 8 (կլորացված) = 18:
Իհարկե, յուրաքանչյուր նման ինդեքս, բացի սկավառակի տարածությունից, որը զբաղեցնում է, նաև ներկայացնում է տվյալների բազայի լրացուցիչ ծախսեր ներդիրների, թարմացումների և ջնջումների համար: Ի վերջո, բացի բուն աղյուսակի տվյալները փոխելուց, անհրաժեշտություն կա նաև վերակառուցել դրա ինդեքսները։ Բայց, ինչպես արդեն ասացի, սովորական կայքերի ծավալի համար սա մեծ խնդիր չէ: Եվ նույնիսկ եթե աղյուսակի վրա ինդեքս եք ստեղծում, որը չեք օգտագործում ձեր sql հարցումներում, դա որևէ նկատելի խնդիր չի առաջացնի: Բացի այդ, միշտ հնարավոր է, որ լրացուցիչ մոդուլ տեղադրելով կամ ինքներդ հարցումներ ավելացնելով, այս ցուցանիշը կարող է շատ օգտակար լինել:
ՆշումԱյնուամենայնիվ, հիշեք, որ սա վերաբերում է հատկապես ամբողջ թվերի ինդեքսներին, և ոչ թե «թույլ տվեք կազմել ինդեքսներ բոլոր հնարավոր դաշտերի համար» տարբերակին:
Պարզ և բարդ ինդեքսներ ամենատարածված հարցումների համար:
Շատ տվյալների բազաներ ունեն արդյունքների քեշ հարցումների համար: Փորձեք կատարել նույն հարցումը երկու անգամ անընդմեջ. առաջին դեպքում հարցումը երկար ժամանակ կպահանջի, երկրորդ անգամ՝ արագ: Առաջին անգամ տվյալները կհաշվարկվեն, երկրորդ անգամ տվյալները կտրամադրվեն քեշից: Այնուամենայնիվ, դա այնքան էլ չի օգնում այն դեպքերում, երբ քեշը չի կառուցվում հարցումների համար (օրինակ, երբ զտիչը պարունակում է հաշվարկված պայմաններ՝ օգտագործելով ներկառուցված տվյալների բազայի գործառույթները), այն դեպքերում, երբ հարցումները, թեև նույն տիպի են, օգտագործվում են տարբեր պարամետրեր, և այն դեպքերում, երբ կան բազմաթիվ հարցումներ, և, հետևաբար, տվյալները պահվում են քեշում շատ կարճ ժամանակահատվածում:
Հետևաբար, պարբերաբար կարող է իմաստ ունենալ հավելյալ ձևավորել կանոնավոր և բարդ ինդեքսներ հաճախակի կատարվող հարցումների համար: Դիտարկենք երկու օրինակ։
Պարզ ցուցանիշ.
Ենթադրենք, դուք ունեք աղյուսակ - ապրանքներ (ապրանք - id, կոդը, անունը, տեքստը): Եվ այնպես է պատահում, որ կայքի օգտատերերը հաճախ որոնում են ապրանքներ իրենց այբբենական կոդերով (հոդվածներ - կոդի դաշտ): Համապատասխանաբար, հարցումն ունի հետևյալ տեսքը.
Այս իրավիճակում իմաստ ունի ստեղծել առանձին ինդեքս «կոդ» դաշտի համար, քանի որ դրա հետ տվյալների բազան ստիպված չի լինի ամբողջությամբ սկանավորել աղյուսակի բոլոր գրառումները: Այնուամենայնիվ, խնդրում ենք նկատի ունենալ, որ տվյալների բազաները կարող են սահմանափակումներ ունենալ դաշտերի տեսակների և չափերի վերաբերյալ: Հետեւաբար, նախ պետք է ստուգեք, թե արդյոք հնարավոր է նման դաշտերի համար ինդեքս ստեղծել։
Կոմպոզիտային ինդեքս.
Նախքան կոմպոզիտային ինդեքսով օրինակ բերելը, կցանկանայի մի կարևոր կետ մի փոքր պարզաբանել՝ կարևոր է ինդեքսի դաշտերի հերթականությունը։ Քանի որ որոնումը նախ կատարվում է առաջին դաշտով, իսկ հետո հաջորդով (և այլն): Հետևաբար, եթե դուք գիտեք միայն վերջին դաշտի հատուկ արժեքը, ապա նման ցուցանիշը հարմար չի լինի, քանի որ առանց առաջին դաշտի հատուկ արժեքը իմանալու անհնար է որոշել, թե որ գրառումների շարքը պետք է ստուգվի, ինչը ինչու տվյալների բազան պետք է սկանավորի աղյուսակի բոլոր գրառումները: Պարզ բառերով, ինդեքսը (սյունակ_1, սյուն_2) հավասար չէ ինդեքսին (սյունակ_2, սյուն_1):
Հիմա ենթադրենք հետևյալ իրավիճակը. Կան երեք աղյուսակներ՝ օգտվող (user - id, name), կատեգորիա (cat - id, name) և հոդված (հոդված - id, cat_id, user_id, name, text): Իսկ դուք նման բան արեցիք կայքում՝ հոդվածի ներքևում ցուցադրվում է տվյալ կատեգորիայի նույն օգտատիրոջ հոդվածների ամբողջական ցանկը։ Միևնույն ժամանակ, օգտատերերն այնքան բեղմնավոր են ստացվել, որ գրում են բազմաթիվ հոդվածներ, թեև տարբեր կատեգորիաներով (օրինակ՝ փոքրիկ պատմություններ, կարճ նոտաներ և այլն)։ Այս դեպքում հարցումը կունենա հետևյալ տեսքը.
Եթե դուք ինդեքսներ եք կազմել նույնացուցիչ դաշտերի համար, ապա դա կօգնի ձեզ, բայց ոչ շատ: Նախ, կան երկու հավասարապես հավանական ինդեքսներ. Մեկը կատեգորիաների համար, իսկ երկրորդը օգտագործողների համար: Թե որն է ավելի լավը, ընդհանուր առմամբ անհայտ է: Բացի այդ, սա կարող է շատ չօգնել, քանի որ օգտվողները կարող են ունենալ 1000 հոդված, իսկ կատեգորիաները կարող են ունենալ 1000 հոդված: Երկրորդ, նույնիսկ որոշակի օգտագործողի (կամ կատեգորիայի) գրառումները նվազեցնելով, դրանք դեռ պետք է սկանավորվեն՝ օգտագործելով երկրորդ դաշտը, այսինքն՝ ամբողջական սկանավորումը (թեև գրառումների ավելի փոքր ծավալի համար): Օրինակ, եթե օգտատերերն ունեն 1000 գրառում, ապա դուք պետք է ստուգեք բոլոր 1000 գրառումները՝ արդյոք դրանք պատկանում են կատեգորիային, թե ոչ։
Մեծ թվով գրառումների և հաճախակի զանգերի համար սա շատ թանկ sql հարցում է: Հետևաբար, այս դեպքում արժե կազմել կոմպոզիտային ինդեքս, օրինակ, (user_id, cat_id): Այս դեպքում, ըստ օգտվողի որոնումից հետո, հետագա որոնումը ըստ կատեգորիայի ավելի արագ կլինի, քանի որ կլինի նաև ստացված ինդեքսը: գրառումներ. Ըստ այդմ, 1000 գրառումները ստուգելու փոխարեն զգալիորեն ավելի քիչ կստուգվեն (չեկերը հաշվարկվում են այնպես, ինչպես սովորական ինդեքսով՝ լոգարիթմ + գրառումների քանակ):
Ինչպե՞ս կարող եք որոշել դաշտերի հերթականությունը նման իրավիճակներում: Այստեղ ամեն ինչ բավականին պարզ է և նման է նրան, ինչ ես նկարագրել եմ զտման մասին հոդվածում (տե՛ս հղումը սկզբում): Հիշեցնեմ, որ բանն այն է, որ կիրառվող յուրաքանչյուր զտիչով գրառումների քանակը հնարավորինս փոքրանում է։ Հետևաբար, իմաստ ունի ստուգել աղյուսակի յուրաքանչյուր դաշտի արժեքի համար գրանցումների միջին քանակը: Եվ այս թվով պակաս դաշտը պետք է առաջինը գնա։ Օրինակ, տրված SQL հարցման համար արժե ստուգել հետևյալը.
Հաշվարկել ընտրված օգտատերերի գրառումների միջին թիվը -- Գրառումների միջին քանակը avg(data.count) որպես միջին -- Խմբավորել բոլոր գրառումները ըստ նույնացուցիչի (ընտրել count(*) որպես «հաշվարկ» հոդվածից -- Խմբավորել ըստ օգտվողների խմբի ըստ user_id) որպես տվյալ; -- Հաշվել գրառումների միջին թիվը ընտրված կատեգորիաների համար -- Գրառումների միջին քանակը avg(data.count) որպես միջին -- Խմբավորել բոլոր գրառումներն ըստ նույնացուցիչի (ընտրել count(*) որպես «հաշվարկ» հոդվածից -- Խումբ ըստ կատեգորիայի խումբ ըստ cat_id) որպես տվյալ;
Համապատասխանաբար, եթե օգտատերերի միջին թիվը փոքր է, ապա այս դաշտը պետք է լինի առաջինը, քանի որ առաջին որոնումից հետո ստուգելու համար քիչ գրառումներ կլինեն: Հակառակ դեպքում, կատեգորիայի ID-ն պետք է լինի առաջին տեղում:
Այնուամենայնիվ, արժե հասկանալ, որ նման իրավիճակում արժե նաև ստուգել, որ գրառումները քիչ թե շատ հավասարաչափ բաշխված են։ Ի վերջո, կարող է պարզվել, որ 1 օգտատեր գրել է 2000 հոդված, իսկ մնացածը` ընդամենը 100: Նման իրավիճակում նախընտրելի է զտիչն ըստ կատեգորիայի, քանի որ ընթերցողների մեծամասնությունը դիտելու է հենց այս օգտատիրոջ հոդվածները: Հետեւաբար, երբեմն արժե հաշվարկել միայն խմբավորումը նույնացուցիչներով (առանց միջին հաշվարկի) և արագ դիտել արդյունքները։
Եթե Ձեզ անհրաժեշտ է ստեղծել ինդեքս երեք կամ ավելի դաշտերի համար, ապա դուք պետք է անեք նույնը՝ ավելացնելով միայն այն դաշտերի թիվը, որոնց համար խմբավորումն իրականացվում է ըստ նույնացուցիչի: Պարզ խոսքերով, նախ ստուգեք առաջին դաշտը և որոշեք ամենափոքր թիվը, այնուհետև «խմբ ըստ սյունակ_1»-ի փոխարեն նշեք տարբեր տարբերակներ մնացած դաշտերով՝ «խմբ առ սյունակ_1, սյունակ_2», այնուհետև «խմբ առ սյունակ_1, սյունակ_3» տեսքով: եւ այլն։ Այս դեպքում բոլորն ընտրում են այն համակցությունները, որոնցում գրանցումների միջին թիվը գնալով փոքրանում է։
Եվ ինդեքսները, սա հատուկ որոնման աղյուսակներ, որը տվյալների բազայի որոնման համակարգը կարող է օգտագործել տվյալների որոնումն արագացնելու համար։ Պարզ ասած, ինդեքսը ցուցիչ է աղյուսակի տվյալներին: Տվյալների բազայում ցուցիչը շատ նման է գրքի հետևի ցուցիչին:
Օրինակ, եթե ցանկանում եք հղումներ տալ գրքի բոլոր էջերին որոշակի թեմայի վերաբերյալ, նախ դիմեք ինդեքսին, որը թվարկում է բոլոր թեմաները այբբենական կարգով, այնուհետև վերաբերում է մեկ կամ մի քանի կոնկրետ էջերի համարներին:
Ինդեքսն օգնում է արագացնել հարցումները և նախադասությունները, բայց դանդաղեցնում է տվյալների մուտքագրումը, հայտարարություններով ԹԱՐՄԱՑՆԵԼԵվ ՆԵՐԴՐԵԼ. Ինդեքսները կարող են ստեղծվել կամ ջնջվել՝ առանց տվյալների վրա ազդելու:
Ինդեքս ստեղծելը ներառում է հայտարարություն ՍՏԵՂԾԵԼ ԻԴԵՔՍ, որը թույլ է տալիս անվանել ինդեքս՝ նշելու համար աղյուսակը և որ սյունակը կամ սյունակները պետք է ինդեքսավորվեն, և նշվի՝ արդյոք ինդեքսը աճման կամ նվազման կարգով է։
Ինդեքսները կարող են լինել նաև եզակի՝ սահմանափակմամբ ՅՈՒՐԱՔԱՆԱԿԱՆ, այնպես որ ինդեքսը կանխում է կրկնօրինակ գրառումները սյունակում կամ սյունակների համակցությունում, որոնց վրա ինդեքս կա:
CREATE INDEX հրամանը
Հիմնական շարահյուսություն ՍՏԵՂԾԵԼ ԻԴԵՔՍԻնչպես նշված է հետեւյալում:
CREATE INDEX index_name ON table_name;
Մեկ սյունակային ինդեքսներ
Աղյուսակի միայն մեկ սյունակի վրա ստեղծվում է մեկ սյունակի ինդեքս: Հիմնական շարահյուսությունը հետևյալն է.
CREATE INDEX index_name ON table_name(column_name);
Եզակի ցուցանիշներ
Եզակի ինդեքսներն օգտագործվում են ոչ միայն շահագործման, այլև տվյալների ամբողջականությունն ապահովելու համար: Եզակի ինդեքսը թույլ չի տալիս կրկնօրինակ արժեքներ տեղադրել աղյուսակում: Հիմնական շարահյուսությունը հետևյալն է.
ՍՏԵՂԱՅԻ_անունի վրա (սյունակի_անուն) ստեղծելու եզակի ինդեքսային անուն;
Կոմպոզիտային ինդեքսներ
Բաղադրյալ ինդեքսը ցուցիչ է աղյուսակի երկու կամ ավելի սյունակների վրա: Դրա հիմնական շարահյուսությունը հետևյալն է.
CREATE INDEX index_name on table_name(column1, column2);
Անկախ նրանից՝ դուք ստեղծում եք ինդեքս մեկ սյունակի վրա, թե կոմպոզիտային, հաշվի առեք այն սյունակ(ներ)ը, որոնք դուք կարող եք շատ հաճախ օգտագործել WHERE հարցումում՝ որպես ֆիլտրի պայման:
Եթե օգտագործվում է միայն մեկ սյունակ, ապա մեկ սյունակի վրա պետք է ընտրվի ինդեքս: Եթե WHERE կետում կան երկու կամ ավելի սյունակներ, որոնք հաճախ օգտագործվում են որպես զտիչներ, ապա ավելի լավ ընտրություն կլինի կոմպոզիտային ինդեքսը:
Անուղղակի ինդեքսներ
Անուղղակի ինդեքսները ինդեքսներ են, որոնք ավտոմատ կերպով ստեղծվում են տվյալների բազայի սերվերում, երբ ստեղծվում է օբյեկտ: Ինդեքսները ինքնաբերաբար ստեղծվում են հիմնական բանալիով և եզակի սահմանափակումով:
DROP INDEX հրամանը
Ինդեքսը կարող է ջնջվել SQL հրամանի միջոցով ԱՆԿՈՒՄ. Դուք պետք է զգույշ լինեք ինդեքսը ջնջելիս, քանի որ կատարումը կարող է կամ ավելի դանդաղ կամ ավելի լավ լինել:
Հիմնական շարահյուսությունը հետևյալն է.
DROP INDEX index_name;
Դուք կարող եք դիտել INDEX սահմանափակման օրինակը՝ ինդեքսների վրա որոշ իրական օրինակներ տեսնելու համար:
Ե՞րբ պետք է խուսափել ինդեքսներից:
Չնայած ինդեքսները նախատեսված են տվյալների բազայի աշխատանքը բարելավելու համար, կան դեպքեր, երբ դրանք պետք է խուսափել:
Հետևյալ հրահանգները ցույց են տալիս, թե երբ պետք է վերանայվի ինդեքսի օգտագործումը:
- Ինդեքսները չպետք է օգտագործվեն փոքր սեղանների վրա:
- Սեղաններ, որոնք հաճախակի մեծ թարմացումներ կամ ներդիրներ ունեն:
- Ինդեքսները չպետք է օգտագործվեն այն սյունակների վրա, որոնք պարունակում են մեծ թվով զրոյական արժեքներ:
- Հաճախակի շահարկվող սյունակները չպետք է ինդեքսավորվեն: