Indeksi- tā ir pirmā lieta, kas jums labi jāsaprot savā darbā SQL serveris, bet dīvainā kārtā elementāri jautājumi forumos netiek uzdoti pārāk bieži un uz tiem nesaņem daudz atbildes.
Robs Šeldons atbild uz šiem jautājumiem, kas rada neskaidrības profesionālajās aprindās par indeksiem in SQL serveris: dažiem no tiem mums vienkārši ir neērti jautāt, bet pirms jautāt citiem, mēs vispirms pārdomāsim.
Izmantotā terminoloģija:
| rādītājs | rādītājs |
| kaudze | ķekars |
| tabula | tabula |
| skats | sniegumu |
| B-koks | līdzsvarots koks |
| klasterizēts indekss | klasterizēts indekss |
| negrupēts indekss | negrupēts indekss |
| salikts indekss | salikts indekss |
| aptverošais indekss | aptverošais indekss |
| primārās atslēgas ierobežojums | primārās atslēgas ierobežojums |
| unikāls ierobežojums | vērtību unikalitātes ierobežojums |
| vaicājums | pieprasījumu |
| vaicājuma dzinējs | vaicājumu apakšsistēma |
| datubāze | datubāze |
| datu bāzes dzinējs | uzglabāšanas apakšsistēma |
| aizpildījuma koeficients | indeksa aizpildīšanas koeficients |
| surogātiskā primārā atslēga | surogātiskā primārā atslēga |
| vaicājumu optimizētājs | vaicājumu optimizētājs |
| indeksa selektivitāte | indeksa selektivitāte |
| filtrēts indekss | filtrējams indekss |
| izpildes plāns | izpildes plāns |
Indeksu pamati SQL Server.
Viens no svarīgākajiem veidiem, kā sasniegt augstu produktivitāti SQL serveris ir indeksu izmantošana. Rādītājs paātrina vaicājuma procesu, nodrošinot ātru piekļuvi datu rindām tabulā, līdzīgi kā rādītājs grāmatā palīdz ātri atrast vajadzīgo informāciju. Šajā rakstā es sniegšu īsu pārskatu par indeksiem SQL serveris un paskaidrojiet, kā tie ir sakārtoti datu bāzē un kā tie palīdz paātrināt datu bāzes vaicājumus.
Indeksi tiek veidoti tabulas un skata kolonnās. Indeksi nodrošina veidu, kā ātri meklēt datus, pamatojoties uz vērtībām šajās kolonnās. Piemēram, ja izveidojat indeksu primārajai atslēgai un pēc tam meklējat datu rindu, izmantojot primārās atslēgas vērtības, SQL serveris vispirms atradīs indeksa vērtību un pēc tam izmantos indeksu, lai ātri atrastu visu datu rindu. Bez indeksa visās tabulas rindās tiks veikta pilna skenēšana, kas var būtiski ietekmēt veiktspēju.
Varat izveidot indeksu lielākajā daļā tabulas vai skata kolonnu. Izņēmums galvenokārt ir kolonnas ar datu tipiem lielu objektu glabāšanai ( LOB), piemēram, attēlu, tekstu vai varchar (maks.). Varat arī izveidot indeksus kolonnās, kas paredzētas datu glabāšanai formātā XML, taču šie indeksi ir strukturēti nedaudz savādāk nekā standarta indeksi, un to izskatīšana ir ārpus šī raksta darbības jomas. Arī rakstā nav runāts kolonnu veikals indeksi. Tā vietā es koncentrējos uz tiem indeksiem, kas visbiežāk tiek izmantoti datu bāzēs SQL serveris.
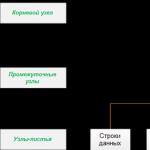
Indekss sastāv no lapu kopas, indeksa mezgliem, kas sakārtoti koka struktūrā - līdzsvarots koks. Šai struktūrai ir hierarhisks raksturs, un tā sākas ar saknes mezglu hierarhijas augšpusē un lapu mezgliem, lapām, apakšā, kā parādīts attēlā:
Kad veicat vaicājumu indeksētā kolonnā, vaicājuma programma sākas saknes mezgla augšdaļā un virzās uz leju caur starpmezgliem, un katrs starpslānis satur detalizētāku informāciju par datiem. Vaicājumu dzinējs turpina pārvietoties pa indeksa mezgliem, līdz tas sasniedz zemāko līmeni ar indeksa lapām. Piemēram, ja indeksētā kolonnā meklējat vērtību 123, vaicājumu programma vispirms noteiks lapu pirmajā vidējā līmenī saknes līmenī. Šajā gadījumā pirmā lapa norāda uz vērtību no 1 līdz 100, bet otrā no 101 līdz 200, tāpēc vaicājumu programma piekļūs šī vidējā līmeņa otrajai lapai. Tālāk jūs redzēsiet, ka jums vajadzētu atvērt nākamā vidējā līmeņa trešo lapu. No šejienes vaicājumu apakšsistēma nolasīs paša indeksa vērtību zemākā līmenī. Indeksa lapās var būt vai nu paši tabulas dati, vai vienkārši rādītājs uz rindām ar datiem tabulā atkarībā no indeksa veida: grupēts vai negrupēts.
Klasterizēts indekss
Klasterizēts indekss saglabā faktiskās datu rindas indeksa lapās. Atgriežoties pie iepriekšējā piemēra, tas nozīmē, ka datu rinda, kas saistīta ar atslēgas vērtību 123, tiks saglabāta pašā indeksā. Svarīga klasterizēta indeksa īpašība ir tā, ka visas vērtības tiek sakārtotas noteiktā secībā, augošā vai dilstošā secībā. Tāpēc tabulai vai skatam var būt tikai viens klasterizēts indekss. Turklāt jāņem vērā, ka dati tabulā tiek saglabāti sakārtotā veidā tikai tad, ja šajā tabulā ir izveidots klasterizēts indekss.
Tabulu, kurai nav grupēta indeksa, sauc par kaudzi.
Negrupēts indekss
Atšķirībā no kopu indeksa, negrupēta indeksa lapas satur tikai tās kolonnas ( taustiņu), pēc kura tiek noteikts šis indekss, un tajā ir arī rādītājs uz rindām ar reāliem datiem tabulā. Tas nozīmē, ka apakšvaicājumu sistēmai ir nepieciešama papildu darbība, lai atrastu un izgūtu nepieciešamos datus. Datu rādītāja saturs ir atkarīgs no tā, kā dati tiek glabāti: klasterizēta tabula vai kaudze. Ja rādītājs norāda uz grupētu tabulu, tas norāda uz grupētu indeksu, ko var izmantot faktisko datu atrašanai. Ja rādītājs norāda uz kaudzi, tas norāda uz konkrētu datu rindas identifikatoru. Negrupētus indeksus nevar kārtot kā grupētus indeksus, taču tabulā vai skatā varat izveidot vairāk nekā vienu negrupētu indeksu līdz 999. Tas nenozīmē, ka jums ir jāizveido pēc iespējas vairāk indeksu. Indeksi var uzlabot vai pasliktināt sistēmas veiktspēju. Papildus tam, ka varat izveidot vairākus negrupētus indeksus, varat iekļaut arī papildu kolonnas ( iekļauta kolonna) savā indeksā: indeksa lapās tiks saglabāta ne tikai pašu indeksēto kolonnu vērtība, bet arī šo neindeksēto papildu kolonnu vērtības. Šī pieeja ļaus jums apiet dažus indeksam noteiktos ierobežojumus. Piemēram, varat iekļaut neindeksējamu kolonnu vai apiet indeksa garuma ierobežojumu (vairumā gadījumu 900 baiti).
Indeksu veidi
Papildus tam, ka tas ir grupēts vai negrupēts indekss, to var tālāk konfigurēt kā saliktu indeksu, unikālu indeksu vai aptverošu indeksu.
Salikts indekss
Šādā rādītājā var būt vairāk nekā viena kolonna. Rādītājā varat iekļaut līdz 16 kolonnām, taču to kopējais garums ir ierobežots līdz 900 baitiem. Gan kopotie, gan negrupētie indeksi var būt salikti.
Unikāls rādītājs
Šis indekss nodrošina, ka katra vērtība indeksētajā kolonnā ir unikāla. Ja indekss ir salikts, unikalitāte attiecas uz visām indeksa kolonnām, bet ne uz katru atsevišķu kolonnu. Piemēram, ja kolonnās izveidojat unikālu indeksu VĀRDS Un UZVĀRDS, tad pilnam vārdam ir jābūt unikālam, taču ir iespējami vārda vai uzvārda dublikāti.
Unikāls indekss tiek automātiski izveidots, kad definējat kolonnas ierobežojumu: primāro atslēgu vai unikālo vērtību ierobežojumu:
- Primārā atslēga
Kad definējat primārās atslēgas ierobežojumu vienai vai vairākām kolonnām, tad SQL serveris automātiski izveido unikālu klasterizētu indeksu, ja iepriekš nav izveidots klasterizēts indekss (šajā gadījumā primārajā atslēgā tiek izveidots unikāls negrupēts indekss) - Vērtību unikalitāte
Kad jūs definējat vērtību unikalitātes ierobežojumu, tad SQL serveris automātiski izveido unikālu negrupētu indeksu. Varat norādīt, ka tiek izveidots unikāls klasterizēts indekss, ja tabulā vēl nav izveidots klasterizēts indekss
Pārklājuma indekss
Šāds indekss ļauj konkrētam vaicājumam nekavējoties iegūt visus nepieciešamos datus no indeksa lapām bez papildu piekļuves pašas tabulas ierakstiem.
Indeksu projektēšana
Lai cik noderīgi būtu indeksi, tie ir rūpīgi jāizstrādā. Tā kā indeksi var aizņemt ievērojamu vietu diskā, jūs nevēlaties izveidot vairāk indeksu nekā nepieciešams. Turklāt indeksi tiek automātiski atjaunināti, kad tiek atjaunināta pati datu rinda, kas var izraisīt papildu resursu izmaksas un veiktspējas pasliktināšanos. Veidojot indeksus, jāņem vērā vairāki apsvērumi attiecībā uz datu bāzi un vaicājumiem pret to.
Datu bāze
Kā minēts iepriekš, indeksi var uzlabot sistēmas veiktspēju, jo tie nodrošina vaicājumu programmu ar ātru datu atrašanas veidu. Tomēr jāņem vērā arī tas, cik bieži plānojat ievietot, atjaunināt vai dzēst datus. Mainot datus, ir jāmaina arī indeksi, lai atspoguļotu atbilstošās darbības ar datiem, kas var ievērojami samazināt sistēmas veiktspēju. Plānojot indeksēšanas stratēģiju, ņemiet vērā šādas vadlīnijas:
- Tabulām, kuras tiek bieži atjauninātas, izmantojiet pēc iespējas mazāk indeksu.
- Ja tabulā ir liels datu apjoms, bet izmaiņas ir nelielas, izmantojiet tik daudz indeksu, cik nepieciešams, lai uzlabotu savu vaicājumu veiktspēju. Tomēr rūpīgi pārdomājiet, pirms lietojat indeksus mazās tabulās, jo... Iespējams, ka indeksa meklēšanas izmantošana var aizņemt ilgāku laiku nekā visu rindu skenēšana.
- Klasterizētiem indeksiem mēģiniet saglabāt pēc iespējas īsākus laukus. Vislabākā pieeja ir izmantot kopu indeksu kolonnām, kurām ir unikālas vērtības un kuras nepieļauj NULL. Tāpēc primārā atslēga bieži tiek izmantota kā klasterizēts indekss.
- Kolonnas vērtību unikalitāte ietekmē indeksa veiktspēju. Kopumā, jo vairāk dublikātu jums ir kolonnā, jo sliktāka ir indeksa veiktspēja. No otras puses, jo vairāk unikālo vērtību ir, jo labāka ir indeksa veiktspēja. Kad vien iespējams, izmantojiet unikālu indeksu.
- Saliktam indeksam ņemiet vērā kolonnu secību rādītājā. Izteiksmēs izmantotās kolonnas KUR(Piemēram, WHERE FirstName = 'Čārlijs') ir jābūt pirmajam rādītājā. Nākamās kolonnas ir jāuzskaita, pamatojoties uz to vērtību unikalitāti (slejas ar lielāko unikālo vērtību skaitu ir pirmās).
- Varat arī norādīt indeksu aprēķinātajām kolonnām, ja tās atbilst noteiktām prasībām. Piemēram, izteiksmēm, ko izmanto, lai iegūtu kolonnas vērtību, jābūt deterministiskām (vienmēr atgriež vienu un to pašu rezultātu noteiktai ievades parametru kopai).
Datu bāzes vaicājumi
Vēl viens apsvērums, veidojot indeksus, ir tas, kādi vaicājumi tiek izpildīti datu bāzē. Kā minēts iepriekš, jums jāapsver, cik bieži dati mainās. Turklāt ir jāizmanto šādi principi:
- Mēģiniet ievietot vai modificēt pēc iespējas vairāk rindu vienā vaicājumā, nevis darīt to vairākos atsevišķos vaicājumos.
- Izveidojiet negrupētu indeksu kolonnās, kuras bieži tiek izmantotas kā meklēšanas vienumi jūsu vaicājumos. KUR un savienojumi iekšā PIEVIENOJIES.
- Apsveriet iespēju indeksēt kolonnas, kas tiek izmantotas rindu uzmeklēšanas vaicājumos, lai iegūtu precīzu vērtību atbilstību.
Kāpēc tabulā nevar būt divi grupēti indeksi?
Vai vēlaties īsu atbildi? Klasterizēts indekss ir tabula. Kad tabulā izveidojat grupētu indeksu, krātuves programma sakārto visas tabulas rindas augošā vai dilstošā secībā atbilstoši indeksa definīcijai. Klasterizēts indekss nav atsevišķa vienība kā citi indeksi, bet gan mehānisms datu kārtošanai tabulā un ātras piekļuves datu rindām atvieglošanai.
Iedomāsimies, ka jums ir tabula ar pārdošanas darījumu vēsturi. Pārdošanas tabulā ir iekļauta tāda informācija kā pasūtījuma ID, preces pozīcija pasūtījumā, preces numurs, preces daudzums, pasūtījuma numurs un datums utt. Kolonnās izveidojat grupētu indeksu Pasūtījuma ID Un LineID, sakārtoti augošā secībā, kā parādīts tālāk T-SQL kods:
Palaižot šo skriptu, visas tabulas rindas vispirms tiks fiziski sakārtotas pēc kolonnas OrderID un pēc tam pēc LineID, bet paši dati paliks vienā loģiskajā blokā — tabulā. Šī iemesla dēļ nevar izveidot divus grupētus indeksus. Var būt tikai viena tabula ar vieniem datiem, un šo tabulu var kārtot tikai vienu reizi noteiktā secībā.
Ja kopu tabula sniedz daudzas priekšrocības, tad kāpēc izmantot kaudzi?
Tev taisnība. Klasterizētas tabulas ir lieliskas, un lielākā daļa jūsu vaicājumu darbosies labāk tabulās, kurām ir grupēts indekss. Bet dažos gadījumos var vēlēties atstāt galdus to dabiskajā, neskartajā stāvoklī, t.i. kaudzes veidā un izveidojiet tikai negrupētus indeksus, lai jūsu vaicājumi darbotos.
Kā jūs atceraties, kaudze saglabā datus nejaušā secībā. Parasti krātuves apakšsistēma pievieno datus tabulai tādā secībā, kādā tie tiek ievietoti, taču krātuves apakšsistēmai arī patīk pārvietot rindas, lai nodrošinātu efektīvāku glabāšanu. Tā rezultātā jums nav iespēju paredzēt, kādā secībā dati tiks saglabāti.
Ja vaicājumu programmai ir jāatrod dati, neizmantojot negrupēta indeksa priekšrocības, tā veiks pilnu tabulas skenēšanu, lai atrastu tai vajadzīgās rindas. Uz ļoti maziem galdiem tā parasti nav problēma, taču, kaudzes izmēram augot, veiktspēja ātri samazinās. Protams, var palīdzēt negrupēts indekss, izmantojot rādītāju uz failu, lapu un rindu, kurā tiek glabāti nepieciešamie dati – tā parasti ir daudz labāka alternatīva tabulas skenēšanai. Pat ja tā ir, ir grūti salīdzināt kopu indeksa priekšrocības, ņemot vērā vaicājuma veiktspēju.
Tomēr kaudze var palīdzēt uzlabot veiktspēju noteiktās situācijās. Apsveriet tabulu, kurā ir daudz ieliktņu, bet maz atjauninājumu vai dzēšanas. Piemēram, tabula, kurā glabājas žurnāls, galvenokārt tiek izmantota, lai ievietotu vērtības, līdz tā tiek arhivēta. Kaudzē jūs neredzēsit peidžeru un datu sadrumstalotību, kā tas būtu ar kopu indeksu, jo rindas tiek vienkārši pievienotas kaudzes beigām. Pārāk liela lapu sadalīšana var būtiski ietekmēt veiktspēju, un tas nav labā nozīmē. Kopumā kaudze ļauj ievietot datus salīdzinoši nesāpīgi, un jums nebūs jārēķinās ar uzglabāšanas un uzturēšanas pieskaitāmajām izmaksām, kas būtu saistītas ar kopu indeksu.
Taču datu atjaunināšanas un dzēšanas trūkumu nevajadzētu uzskatīt par vienīgo iemeslu. Svarīgs faktors ir arī datu izlases veids. Piemēram, nevajadzētu izmantot kaudzi, ja bieži vaicājat datu diapazonus vai vaicātie dati bieži ir jākārto vai jāgrupē.
Tas viss nozīmē, ka apsveriet kaudzes izmantošanu tikai tad, ja strādājat ar ļoti mazām tabulām vai visa jūsu mijiedarbība ar tabulu aprobežojas ar datu ievietošanu, un jūsu vaicājumi ir ārkārtīgi vienkārši (un jūs izmantojat negrupētus indeksus jebkurā gadījumā). Pretējā gadījumā izmantojiet labi izstrādātu klasterizētu indeksu, piemēram, tādu, kas definēts vienkāršā augošā atslēgas laukā, piemēram, plaši izmantota kolonna ar IDENTITĀTE.
Kā mainīt noklusējuma indeksa aizpildīšanas koeficientu?
Viena lieta ir mainīt noklusējuma indeksa aizpildījuma koeficientu. Cits jautājums ir saprast, kā darbojas noklusējuma attiecība. Bet vispirms speriet dažus soļus atpakaļ. Indeksa aizpildīšanas faktors nosaka vietas daudzumu lapā, lai saglabātu indeksu apakšējā līmenī (lapas līmenī), pirms sākat aizpildīt jaunu lapu. Piemēram, ja koeficients ir iestatīts uz 90, tad indeksam pieaugot, tas aizņems 90% lapas un pēc tam pāries uz nākamo lapu.
Pēc noklusējuma indeksa aizpildījuma faktora vērtība ir norādīta SQL serveris ir 0, kas ir tāds pats kā 100. Rezultātā visi jaunie indeksi automātiski pārmanto šo iestatījumu, ja vien savā kodā īpaši nenorādīsiet vērtību, kas atšķiras no sistēmas standarta vērtības, vai maināt noklusējuma darbību. Tu vari izmantot SQL Server Management Studio lai pielāgotu noklusējuma vērtību vai palaistu sistēmā saglabātu procedūru sp_configure. Piemēram, šāds komplekts T-SQL komandas iestata koeficienta vērtību uz 90 (vispirms jāpārslēdzas uz papildu iestatījumu režīmu):
EXEC sp_configure "rādīt papildu opcijas ", 1; GO RECONFIGURE; GO EXEC sp_configure " aizpildījuma koeficients", 90; GO RECONFIGURE; GO
Pēc indeksa aizpildīšanas faktora vērtības maiņas pakalpojums ir jārestartē SQL serveris. Tagad varat pārbaudīt iestatīto vērtību, palaižot sp_configure bez norādītā otrā argumenta:
EXEC sp_configure "aizpildījuma koeficients" GO
Šai komandai ir jāatgriež vērtība 90. Rezultātā visi jaunizveidotie indeksi izmantos šo vērtību. Varat to pārbaudīt, izveidojot indeksu un vaicājot aizpildījuma faktora vērtību:
IZMANTOT AdventureWorks2012; - jūsu datu bāze UZ IZVEIDOT NONCLUSTERED INDEX ix_cilvēki_uzvārds ON Person.Person(Uzvārds); GO SELECT fill_factor FROM sys .indexes WHERE objekta_id = objekta_id("Persona.Person" ) UN nosaukums ="ix_cilvēki_uzvārds" ;Šajā piemērā mēs tabulā izveidojām neklasteru indeksu Persona datubāzē AdventureWorks2012. Pēc indeksa izveides mēs varam iegūt aizpildījuma faktora vērtību no sys.indexes sistēmas tabulām. Vaicājumam ir jāatgriež 90.
Tomēr iedomāsimies, ka indeksu izdzēsām un izveidojām vēlreiz, bet tagad norādījām konkrētu aizpildījuma faktora vērtību:
Šoreiz esam pievienojuši norādījumus AR un opcija aizpildīšanas faktors mūsu indeksa izveides darbībai IZVEIDOT INDEKSU un norādīja vērtību 80. Operator ATLASĪT tagad atgriež atbilstošo vērtību.
Līdz šim viss ir bijis diezgan vienkārši. Visā šajā procesā jūs patiešām varat sadedzināt, ja izveidojat indeksu, kurā tiek izmantota noklusējuma koeficienta vērtība, pieņemot, ka jūs zināt šo vērtību. Piemēram, kāds ķeras pie servera iestatījumiem un ir tik spītīgs, ka iestata indeksa aizpildīšanas koeficientu uz 20. Tikmēr jūs turpiniet veidot indeksus, pieņemot, ka noklusējuma vērtība ir 0. Diemžēl jūs nevarat uzzināt aizpildījumu. faktors, kamēr neizveidojat indeksu un pēc tam nepārbaudāt vērtību, kā to darījām savos piemēros. Pretējā gadījumā jums būs jāgaida brīdis, kad vaicājuma veiktspēja samazināsies tik daudz, ka jūs sākat kaut ko aizdomāties.
Vēl viena problēma, kas jums jāzina, ir indeksu atjaunošana. Tāpat kā veidojot indeksu, indeksa aizpildīšanas faktora vērtību varat norādīt, kad to atjaunojat. Tomēr atšķirībā no komandas izveidot indeksu, rebuild neizmanto servera noklusējuma iestatījumus, neskatoties uz to, kā tas varētu šķist. Vēl jo vairāk, ja īpaši nenorādīsiet indeksa aizpildījuma faktora vērtību, tad SQL serveris izmantos koeficienta vērtību, ar kādu šis indekss pastāvēja pirms tā pārstrukturēšanas. Piemēram, šāda darbība MAINĪT INDEKSU atjauno tikko izveidoto indeksu:
Pārbaudot aizpildījuma faktora vērtību, mēs iegūsim vērtību 80, jo to mēs norādījām, kad pēdējo reizi izveidojām indeksu. Noklusējuma vērtība tiek ignorēta.
Kā redzat, indeksa aizpildījuma faktora vērtības maiņa nav tik sarežģīta. Ir daudz grūtāk zināt pašreizējo vērtību un saprast, kad tā tiek piemērota. Ja, veidojot un pārbūvējot indeksus, vienmēr konkrēti norādāt koeficientu, tad vienmēr zināt konkrēto rezultātu. Ja vien jums nav jāuztraucas par to, vai kāds cits vēlreiz nesabojā servera iestatījumus, izraisot visu indeksu pārbūvi ar smieklīgi zemu indeksa aizpildīšanas koeficientu.
Vai ir iespējams izveidot grupētu indeksu kolonnai, kurā ir dublikāti?
Jā un nē. Jā, jūs varat izveidot grupētu indeksu atslēgas kolonnā, kurā ir dublētās vērtības. Nē, atslēgas kolonnas vērtība nevar palikt neunikālā stāvoklī. Ļauj man paskaidrot. Ja kolonnā izveidojat neunikālu klasterizētu indeksu, krātuves programma dublikātai vērtībai pievieno vienreizējo, lai nodrošinātu unikalitāti un tādējādi varētu identificēt katru klasterētās tabulas rindu.
Piemēram, varat izlemt izveidot klasterizētu indeksu kolonnā, kurā ir klienta dati Uzvārds uzvārda saglabāšana. Kolonnā ir vērtības Franklins, Henkoks, Vašingtona un Smits. Pēc tam vēlreiz ievietojat vērtības Adams, Hancock, Smith un Smith. Bet atslēgas kolonnas vērtībai ir jābūt unikālai, tāpēc uzglabāšanas dzinējs mainīs dublikātu vērtību, lai tie izskatītos apmēram šādi: Adams, Franklin, Hancock, Hancock1234, Washington, Smith, Smith4567 un Smith5678.
No pirmā acu uzmetiena šī pieeja šķiet laba, taču vesela skaitļa vērtība palielina atslēgas lielumu, kas var kļūt par problēmu, ja ir liels skaits dublikātu, un šīs vērtības kļūs par pamatu negrupētam indeksam vai svešam indeksam. galvenā atsauce. Šo iemeslu dēļ, kad vien iespējams, vienmēr jācenšas izveidot unikālus klasterizētus indeksus. Ja tas nav iespējams, tad vismaz mēģiniet izmantot kolonnas ar ļoti augstu unikālās vērtības saturu.
Kā tiek saglabāta tabula, ja nav izveidots klasterizēts indekss?
SQL serveris atbalsta divu veidu tabulas: grupētas tabulas, kurām ir grupēts indekss, un kaudzes tabulas vai tikai kaudzes. Atšķirībā no grupētajām tabulām, kaudzes dati netiek kārtoti nekādā veidā. Būtībā šī ir datu kaudze (kaudze). Ja pievienosiet rindu šādai tabulai, uzglabāšanas programma to vienkārši pievienos lapas beigās. Kad lapa ir aizpildīta ar datiem, tā tiks pievienota jaunai lapai. Vairumā gadījumu tabulā ir jāizveido klasterizēts indekss, lai izmantotu kārtojamības un vaicājuma ātruma priekšrocības (mēģiniet iedomāties tālruņa numura meklēšanu nešķirotā adrešu grāmatā). Tomēr, ja izvēlaties neveidot grupētu indeksu, jūs joprojām varat izveidot negrupētu indeksu kaudzē. Šajā gadījumā katrā indeksa rindā būs rādītājs uz kaudzes rindu. Rādītājs ietver faila ID, lapas numuru un datu rindas numuru.
Kāda ir saistība starp vērtību unikalitātes ierobežojumiem un primāro atslēgu ar tabulas indeksiem?
Primārā atslēga un unikāls ierobežojums nodrošina, ka kolonnas vērtības ir unikālas. Tabulai var izveidot tikai vienu primāro atslēgu, un tajā nedrīkst būt vērtības NULL. Varat izveidot vairākus tabulas vērtības unikalitātes ierobežojumus, un katram no tiem var būt viens ieraksts ar NULL.
Kad veidojat primāro atslēgu, krātuves programma izveido arī unikālu klasterizētu indeksu, ja kopu indekss vēl nav izveidots. Tomēr jūs varat ignorēt noklusējuma darbību, un tiks izveidots negrupēts indekss. Ja, veidojot primāro atslēgu, pastāv klasterizēts indekss, tiks izveidots unikāls negrupēts indekss.
Kad izveidojat unikālu ierobežojumu, krātuves programma izveido unikālu, negrupētu indeksu. Tomēr varat norādīt unikāla klasterizēta indeksa izveidi, ja tāds iepriekš nav izveidots.
Kopumā unikāls vērtības ierobežojums un unikāls indekss ir viens un tas pats.
Kāpēc grupētos un negrupētos indeksus SQL serverī sauc par B-koku?
SQL Server pamata indeksi, grupēti vai negrupēti, tiek sadalīti pa lapu kopām, ko sauc par indeksa mezgliem. Šīs lapas ir sakārtotas noteiktā hierarhijā ar koka struktūru, ko sauc par līdzsvarotu koku. Augšējā līmenī ir saknes mezgls, apakšā ir lapu mezgli ar starpmezgliem starp augšējo un apakšējo līmeni, kā parādīts attēlā:
Saknes mezgls nodrošina galveno ieejas punktu vaicājumiem, kas mēģina izgūt datus, izmantojot indeksu. Sākot no šī mezgla, vaicājumu programma sāk navigāciju lejup pa hierarhisko struktūru uz atbilstošo lapas mezglu, kurā ir dati.
Piemēram, iedomājieties, ka ir saņemts pieprasījums atlasīt rindas, kuru atslēgas vērtība ir 82. Vaicājuma apakšsistēma sāk darboties no saknes mezgla, kas attiecas uz piemērotu starpmezglu, mūsu gadījumā 1-100. No starpposma mezgla 1-100 notiek pāreja uz mezglu 51-100, un no tā uz gala mezglu 76-100. Ja tas ir klasterizēts indekss, tad mezgla lapā ir ar atslēgu saistītās rindas dati, kas ir vienādi ar 82. Ja tas ir negrupēts indekss, tad indeksa lapā ir rādītājs uz grupēto tabulu vai konkrētu rindu kaudze.
Kā indekss var pat uzlabot vaicājuma veiktspēju, ja jums ir jāšķērso visi šie indeksa mezgli?
Pirmkārt, indeksi ne vienmēr uzlabo veiktspēju. Pārāk daudz nepareizi izveidotu indeksu pārvērš sistēmu par purvu un pasliktina vaicājuma veiktspēju. Precīzāk ir teikt, ka, ja indeksi tiek rūpīgi piemēroti, tie var nodrošināt ievērojamu veiktspējas pieaugumu.
Padomājiet par milzīgu grāmatu, kas veltīta veiktspējas regulēšanai SQL serveris(papīra versija, nevis elektroniskā versija). Iedomājieties, ka vēlaties atrast informāciju par Resource Governor konfigurēšanu. Varat vilkt ar pirkstu pa lappusei cauri visai grāmatai vai atvērt satura rādītāju un uzzināt precīzu lapas numuru ar meklēto informāciju (ja grāmata ir pareizi indeksēta un saturam ir pareizi rādītāji). Tas noteikti ietaupīs jūsu laiku, lai gan vispirms ir jāpiekļūst pavisam citai struktūrai (indeksam), lai iegūtu nepieciešamo informāciju no primārās struktūras (grāmatas).
Kā grāmatu rādītājs, rādītājs iekšā SQL serverisļauj izpildīt precīzus vaicājumus par nepieciešamajiem datiem, nevis pilnībā skenēt visus tabulā ietvertos datus. Mazām tabulām pilna skenēšana parasti nav problēma, taču lielas tabulas aizņem daudzas datu lapas, kas var izraisīt ievērojamu vaicājuma izpildes laiku, ja vien nepastāv rādītājs, kas ļauj vaicājuma programmai nekavējoties iegūt pareizo datu atrašanās vietu. Iedomājieties, ka apmaldāties daudzlīmeņu ceļu krustojumā lielas metropoles priekšā bez kartes, un jūs sapratīsit.
Ja indeksi ir tik lieliski, kāpēc gan neizveidot to katrā kolonnā?
Neviens labs darbs nedrīkst palikt nesodīts. Vismaz tā ir ar indeksiem. Protams, indeksi darbojas lieliski, ja vien palaižat operatora ieneses vaicājumus ATLASĪT, bet tiklīdz sākas bieža zvanīšana operatoriem IEVIETOT, ATJAUNINĀT Un DZĒST, tāpēc ainava mainās ļoti ātri.
Kad iniciējat operatora datu pieprasījumu ATLASĪT, vaicājumu dzinējs atrod indeksu, pārvietojas pa koka struktūru un atklāj meklētos datus. Kas var būt vienkāršāks? Bet lietas mainās, ja uzsākat paziņojumu par izmaiņām, piemēram, ATJAUNINĀT. Jā, priekšraksta pirmajai daļai vaicājumu programma atkal var izmantot indeksu, lai atrastu modificējamo rindu — tās ir labas ziņas. Un, ja rindā ir veiktas vienkāršas datu izmaiņas, kas neietekmē izmaiņas galvenajās kolonnās, tad izmaiņu process būs pilnīgi nesāpīgs. Bet ko darīt, ja izmaiņu rezultātā tiek sadalītas lapas, kurās ir dati, vai tiek mainīta atslēgas kolonnas vērtība, izraisot tās pārvietošanu uz citu indeksa mezglu — tā rezultātā indeksam, iespējams, būs nepieciešama reorganizācija, kas ietekmēs visus saistītos indeksus un darbības. , kā rezultātā strauji samazinās produktivitāte.
Līdzīgi procesi notiek, zvanot operatoram DZĒST. Rādītājs var palīdzēt atrast dzēšamos datus, taču pašu datu dzēšana var izraisīt lapas pārkārtošanu. Attiecībā uz operatoru IEVIETOT, visu indeksu galvenais ienaidnieks: jūs sākat pievienot lielu datu apjomu, kas noved pie izmaiņām indeksos un to reorganizācijā, un visi cieš.
Tāpēc apsveriet datubāzes vaicājumu veidus, domājot par to, kāda veida indeksus un cik daudz izveidot. Vairāk nenozīmē labāk. Pirms jauna indeksa pievienošanas tabulai ņemiet vērā ne tikai pamatā esošo vaicājumu izmaksas, bet arī patērētās diska vietas apjomu, funkcionalitātes un indeksu uzturēšanas izmaksas, kas var izraisīt domino efektu citās darbībās. Jūsu indeksa izveides stratēģija ir viens no svarīgākajiem ieviešanas aspektiem, un tajā jāiekļauj daudzi apsvērumi, sākot no indeksa lieluma, unikālo vērtību skaita un beidzot ar vaicājumu veidiem, ko rādītājs atbalstīs.
Vai kolonnā ar primāro atslēgu ir jāizveido klasterizēts indekss?
Varat izveidot grupētu indeksu jebkurā kolonnā, kas atbilst nepieciešamajiem nosacījumiem. Tā ir taisnība, ka klasterizēts indekss un primārās atslēgas ierobežojums ir izveidoti viens otram un atbilst debesīm, tāpēc saprotiet faktu, ka, izveidojot primāro atslēgu, tad automātiski tiks izveidots klasterizēts indekss, ja tāds nav bijis. izveidota iepriekš. Tomēr jūs varat izlemt, ka grupētais indekss citur darbosies labāk, un bieži vien jūsu lēmums būs pamatots.
Klasterizētā indeksa galvenais mērķis ir kārtot visas tabulas rindas, pamatojoties uz atslēgas kolonnu, kas norādīta, definējot indeksu. Tas nodrošina ātru meklēšanu un vieglu piekļuvi tabulas datiem.
Tabulas primārā atslēga var būt laba izvēle, jo tā unikāli identificē katru tabulas rindu, nepievienojot papildu datus. Dažos gadījumos labākā izvēle būs primārā surogāt atslēga, kas ir ne tikai unikāla, bet arī maza izmēra un kuras vērtības palielinās secīgi, padarot efektīvākus uz šīs vērtības balstītos negrupētos indeksus. Vaicājumu optimizētājam patīk arī šī klasterizētā indeksa un primārās atslēgas kombinācija, jo tabulu savienošana ir ātrāka nekā savienošana citā veidā, kurā netiek izmantota primārā atslēga un ar to saistītais klasterizētais indekss. Kā jau teicu, tas ir debesīs radīts mačs.
Visbeidzot, tomēr ir vērts atzīmēt, ka, veidojot klasterizētu indeksu, ir jāņem vērā vairāki aspekti: cik daudz neklasterētu indeksu būs uz tā pamata, cik bieži mainīsies galvenā indeksa kolonnas vērtība un cik liela. Ja mainās vērtības grupētā indeksa kolonnās vai indekss nedarbojas, kā paredzēts, var tikt ietekmēti visi pārējie tabulas indeksi. Klasterizētajam indeksam jābūt balstītam uz visnoturīgāko kolonnu, kuras vērtības palielinās noteiktā secībā, bet nemainās nejauši. Indeksam ir jāatbalsta vaicājumi pret tabulas visbiežāk piekļūtajiem datiem, lai vaicājumi pilnībā izmantotu to, ka dati tiek sakārtoti un pieejami saknes mezglos, indeksa lapās. Ja primārā atslēga atbilst šim scenārijam, izmantojiet to. Ja nē, izvēlieties citu kolonnu kopu.
Ko darīt, ja indeksējat skatu, vai tas joprojām ir skats?
Skats ir virtuāla tabula, kas ģenerē datus no vienas vai vairākām tabulām. Būtībā tas ir nosaukts vaicājums, kas izgūst datus no pamatā esošajām tabulām, kad vaicājat šajā skatā. Varat uzlabot vaicājuma veiktspēju, šajā skatā izveidojot grupētu indeksu un negrupētus indeksus, līdzīgi tam, kā veidojat indeksus tabulā, taču galvenais brīdinājums ir tāds, ka vispirms ir jāizveido klasterizēts indekss un pēc tam varat izveidot negrupētu indeksu.
Kad tiek izveidots indeksēts skats (materializēts skats), pati skata definīcija paliek atsevišķa vienība. Galu galā tas ir tikai iekodēts operators ATLASĪT, glabājas datu bāzē. Bet indekss ir pavisam cits stāsts. Izveidojot klasteru vai neklasterētu indeksu nodrošinātājā, dati tiek fiziski saglabāti diskā, tāpat kā parastais indekss. Turklāt, mainoties datiem pamatā esošajās tabulās, skata rādītājs automātiski mainās (tas nozīmē, ka, iespējams, vēlēsities izvairīties no skatu indeksēšanas tabulās, kas bieži mainās). Jebkurā gadījumā skats paliek skats - skats uz tabulām, bet šobrīd izpildīts, ar tam atbilstošiem indeksiem.
Lai skatā varētu izveidot indeksu, tam ir jāatbilst vairākiem ierobežojumiem. Piemēram, skats var atsaukties tikai uz bāzes tabulām, bet ne uz citiem skatiem, un šīm tabulām ir jāatrodas tajā pašā datu bāzē. Patiesībā ir daudz citu ierobežojumu, tāpēc noteikti pārbaudiet dokumentāciju SQL serveris par visām netīrajām detaļām.
Kāpēc izmantot aptverošu indeksu, nevis saliktu indeksu?
Pirmkārt, pārliecināsimies, ka mēs saprotam atšķirību starp abiem. Saliktais indekss ir vienkārši parasts indekss, kas satur vairāk nekā vienu kolonnu. Var izmantot vairākas atslēgu kolonnas, lai nodrošinātu, ka katra tabulas rinda ir unikāla, vai arī jums var būt vairākas kolonnas, lai nodrošinātu, ka primārā atslēga ir unikāla, vai arī jūs mēģināt optimizēt bieži izsaukto vaicājumu izpildi vairākās kolonnās. Tomēr kopumā, jo vairāk galveno sleju indekss satur, jo mazāk efektīvs būs indekss, kas nozīmē, ka saliktie indeksi ir jāizmanto saprātīgi.
Kā minēts, vaicājums var gūt lielu labumu, ja visi nepieciešamie dati uzreiz atrodas indeksa lapās, tāpat kā pats rādītājs. Klasterizētam indeksam tā nav problēma, jo visi dati jau ir tur (tāpēc ir tik svarīgi rūpīgi pārdomāt, veidojot kopu indeksu). Bet lapu indeksā, kas nav grupēts, ir tikai galvenās kolonnas. Lai piekļūtu visiem citiem datiem, vaicājumu optimizētājam ir jāveic papildu darbības, kas var ievērojami palielināt vaicājumu izpildi.
Šeit palīgā nāk seguma indekss. Kad definējat negrupētu indeksu, galvenajām kolonnām varat norādīt papildu kolonnas. Piemēram, pieņemsim, ka jūsu lietojumprogramma bieži vaicā kolonnas datus Pasūtījuma ID Un Pasūtījuma datums tabulā Pārdošana:
Abās kolonnās varat izveidot saliktu, negrupētu indeksu, taču sleja OrderDate tikai pievienos indeksa uzturēšanas izmaksas, neizmantojot īpaši noderīgu atslēgu kolonnu. Labākais risinājums būtu atslēgas kolonnā izveidot aptverošu indeksu Pasūtījuma ID un papildus iekļauta kolonna Pasūtījuma datums:
IZVEIDOT NEKLUSTERĒTU INDEKSU ix_orderid UZ dbo.Pārdošana(Pasūtījuma ID) IEKĻAUJ (Pasūtījuma datums);Tādējādi tiek novērsti lieko kolonnu indeksēšanas trūkumi, vienlaikus saglabājot priekšrocības, ko sniedz datu glabāšana lapās, izpildot vaicājumus. Iekļautā kolonna nav atslēgas daļa, bet dati tiek glabāti lapas mezglā, indeksa lapā. Tas var uzlabot vaicājuma veiktspēju bez papildu pieskaitāmām izmaksām. Turklāt uz aptverošajā indeksā iekļautajām kolonnām attiecas mazāk ierobežojumu nekā uz indeksa galvenajām kolonnām.
Vai dublikātu skaitam atslēgas kolonnā ir nozīme?
Kad veidojat indeksu, jums ir jāmēģina samazināt dublikātu skaitu atslēgu kolonnās. Vai precīzāk: mēģiniet saglabāt pēc iespējas zemāku atkārtojumu skaitu.
Ja strādājat ar saliktu indeksu, dublēšana attiecas uz visām galvenajām kolonnām kopumā. Vienā kolonnā var būt daudz vērtību dublikātu, taču visās indeksa kolonnās jāatkārtojas minimāli. Piemēram, kolonnās izveidojat saliktu negrupētu indeksu Vārds Un Uzvārds, jums var būt daudz John Doe vērtību un daudzas Stirna vērtības, taču vēlaties, lai būtu pēc iespējas mazāk John Doe vērtību vai vēlams tikai vienu John Doe vērtību.
Galvenās kolonnas vērtību unikalitātes attiecību sauc par indeksa selektivitāti. Jo vairāk ir unikālu vērtību, jo augstāka ir selektivitāte: unikālajam indeksam ir vislielākā iespējamā selektivitāte. Vaicājumu programmai ļoti patīk kolonnas ar augstām selektivitātes vērtībām, it īpaši, ja šīs kolonnas ir iekļautas jūsu visbiežāk izpildīto vaicājumu WHERE klauzulās. Jo selektīvāks indekss, jo ātrāk vaicājumu programma var samazināt iegūtās datu kopas lielumu. Negatīvā puse, protams, ir tāda, ka kolonnas ar salīdzinoši nelielām unikālām vērtībām reti būs piemērotas indeksēšanai.
Vai ir iespējams izveidot negrupētu indeksu tikai noteiktai atslēgas kolonnas datu apakškopai?
Pēc noklusējuma negrupētajā indeksā ir viena rinda katrai tabulas rindai. Protams, to pašu var teikt par klasterizētu indeksu, pieņemot, ka šāds indekss ir tabula. Bet, kad runa ir par indeksu, kas nav grupēts, attiecības viens pret vienu ir svarīgs jēdziens, jo, sākot ar versiju SQL Server 2008, jums ir iespēja izveidot filtrējamu indeksu, kas ierobežo tajā iekļautās rindas. Filtrēts indekss var uzlabot vaicājuma veiktspēju, jo... tā ir mazāka izmēra un satur filtrētu, precīzāku statistiku nekā visas tabulas - tādējādi tiek izveidoti uzlaboti izpildes plāni. Filtrētam indeksam ir nepieciešams arī mazāk vietas uzglabāšanai un zemākas uzturēšanas izmaksas. Indekss tiek atjaunināts tikai tad, kad mainās dati, kas atbilst filtram.
Turklāt ir viegli izveidot filtrējamu indeksu. Operatorā IZVEIDOT INDEKSU jums tikai jānorāda KUR filtra stāvoklis. Piemēram, varat filtrēt no indeksa visas rindas, kurās ir NULL, kā parādīts kodā:
Mēs faktiski varam filtrēt visus datus, kas nav svarīgi kritiskos vaicājumos. Bet esiet uzmanīgi, jo... SQL serveris uzliek vairākus ierobežojumus filtrējamiem indeksiem, piemēram, nespēja izveidot skatā filtrējamu indeksu, tāpēc uzmanīgi izlasiet dokumentāciju.
Var arī būt, ka līdzīgus rezultātus varat sasniegt, izveidojot indeksētu skatu. Tomēr filtrētajam indeksam ir vairākas priekšrocības, piemēram, iespēja samazināt uzturēšanas izmaksas un uzlabot izpildes plānu kvalitāti. Filtrētos indeksus var arī atjaunot tiešsaistē. Izmēģiniet to ar indeksētu skatu.
6. Indeksi un veiktspējas optimizācija
Indeksi datu bāzēs: mērķis, ietekme uz veiktspēju, indeksu veidošanas principi
6.1. Kam paredzēti indeksi?
Indeksi ir īpašas struktūras datu bāzēs, kas ļauj paātrināt meklēšanu un kārtošanu pēc noteikta lauka vai lauku kopas tabulā, kā arī tiek izmantotas, lai nodrošinātu datu unikalitāti. Vienkāršākais veids, kā salīdzināt rādītājus, ir ar grāmatu rādītājiem. Ja indeksa nav, tad mums būs jāpārskata visa grāmata, lai atrastu īsto vietu, bet ar indeksu to pašu darbību var veikt daudz ātrāk.
Parasti, jo vairāk indeksu, jo labāka ir datu bāzes vaicājumu veiktspēja. Tomēr, ja indeksu skaits pārmērīgi palielinās, datu modifikācijas darbību (insert/change/delete) veiktspēja samazinās un datu bāzes apjoms palielinās, tāpēc pret indeksu pievienošanu jāizturas piesardzīgi.
Daži vispārīgi principi, kas saistīti ar indeksu izveidi:
· jāveido indeksi kolonnām, kuras tiek izmantotas savienojumos, kuras bieži izmanto meklēšanas un kārtošanas darbībām. Lūdzu, ņemiet vērā, ka indeksi vienmēr tiek automātiski izveidoti kolonnām, uz kurām attiecas primārās atslēgas ierobežojums. Visbiežāk tie tiek izveidoti kolonnām ar ārējo atslēgu (piekļuvē - automātiski);
· automātiski jāizveido indekss kolonnām, uz kurām attiecas unikalitātes ierobežojums;
· Vislabāk ir izveidot indeksus tiem laukiem, kuros ir minimāls atkārtoto vērtību skaits un dati ir vienmērīgi sadalīti. Oracle ir īpaši bitu indeksi kolonnām ar lielu dublikātu skaitu SQL Server un Access nenodrošina šāda veida indeksu;
· ja meklēšana tiek pastāvīgi veikta konkrētai kolonnu kopai (vienlaicīgi), tad šajā gadījumā var būt jēga izveidot saliktu indeksu (tikai SQL Server) – vienu indeksu kolonnu grupai;
· Veicot izmaiņas tabulās, šai tabulai uzliktie indeksi tiek automātiski mainīti. Rezultātā indekss var būt ļoti sadrumstalots, kas ietekmē veiktspēju. Periodiski jāpārbauda indeksa sadrumstalotības pakāpe un tās defragmentē. Ielādējot lielu datu apjomu, dažreiz ir jēga vispirms izdzēst visus indeksus un pēc darbības pabeigšanas tos izveidot vēlreiz;
· indeksus var izveidot ne tikai tabulām, bet arī skatiem (tikai SQL Server). Priekšrocības - iespēja aprēķināt laukus nevis pieprasījuma brīdī, bet gan šobrīd tabulās parādās jaunas vērtības.
Šajā rakstā ir apskatīti indeksi un to loma vaicājuma izpildes laika optimizēšanā. Raksta pirmajā daļā ir aplūkotas dažādas indeksu formas un to glabāšana. Tālāk mēs pārbaudām trīs galvenos Transact-SQL priekšrakstus, ko izmanto darbam ar indeksiem: CREATE INDEX, ALTER INDEX un DROP INDEX. Pēc tam tiek aplūkota indeksu sadrumstalotība tās ietekmei uz sistēmas veiktspēju. Pēc tam tajā ir sniegtas dažas vispārīgas vadlīnijas indeksu izveidei un aprakstīti vairāki īpaši indeksu veidi.
Galvenā informācija
Datu bāzes sistēmas parasti izmanto indeksus, lai nodrošinātu ātru piekļuvi relāciju datiem. Indekss ir atsevišķa fiziska datu struktūra, kas ļauj ātri piekļūt vienai vai vairākām datu rindām. Tādējādi pareiza indeksu regulēšana ir galvenais vaicājuma veiktspējas uzlabošanas aspekts.
Datu bāzes rādītājs daudzējādā ziņā ir līdzīgs grāmatas indeksam (alfabētiskajam rādītājam). Kad grāmatā ātri jāatrod tēma, vispirms skatāmies rādītājā, kurās grāmatas lappusēs šī tēma ir apspriesta, un tad uzreiz atveram vajadzīgo lapu. Līdzīgi, meklējot konkrētu rindu tabulā, datu bāzes programma piekļūst indeksam, lai atrastu tā fizisko atrašanās vietu.
Taču pastāv divas būtiskas atšķirības starp grāmatu indeksu un datu bāzes indeksu:
Grāmatas lasītājam ir iespēja pašam izlemt, vai katrā konkrētajā gadījumā izmantot rādītāju vai nē. Datu bāzes lietotājam šādas iespējas nav, un šo lēmumu viņa vietā pieņem sistēmas komponents, ko sauc vaicājumu optimizētājs. (Lietotājs var manipulēt ar indeksu izmantošanu, izmantojot indeksa ieteikumus, taču šos ieteikumus ieteicams izmantot tikai ierobežotā skaitā īpašos gadījumos.)
Konkrētas darbgrāmatas rādītājs tiek izveidots kopā ar darbgrāmatu, pēc kura tas vairs netiek mainīts. Tas nozīmē, ka konkrētas tēmas rādītājs vienmēr norādīs uz vienu un to pašu lapas numuru. Turpretim datu bāzes indekss var mainīties ikreiz, kad mainās attiecīgie dati.
Ja tabulai nav piemērota indeksa, sistēma rindu izgūšanai izmanto tabulas skenēšanas metodi. Izteiksme galda skenēšana nozīmē, ka sistēma secīgi izgūst un pārbauda katru tabulas rindu (no pirmās līdz pēdējai) un ievieto rindu rezultātu kopā, ja tai ir izpildīts meklēšanas nosacījums WHERE klauzulā. Tādējādi visas rindas tiek izgūtas atbilstoši to fiziskajai atrašanās vietai atmiņā. Šī metode ir mazāk efektīva nekā piekļuve, izmantojot indeksus, kā paskaidrots tālāk.
Indeksi tiek glabāti papildu datu bāzes struktūrās, ko sauc rādītāja lapas. Katrai indeksētajai rindai ir indeksa ieraksts, kas tiek saglabāts rādītāja lapā. Katrs indeksa elements sastāv no indeksa atslēgas un indeksa. Tāpēc indeksa elements ir ievērojami īsāks nekā tabulas rinda, uz kuru tas norāda. Šī iemesla dēļ rādītāja elementu skaits katrā rādītāja lapā ir daudz lielāks nekā rindu skaits datu lapā.
Šī indeksu īpašība ir ļoti svarīga, jo I/O operāciju skaits, kas nepieciešams, lai šķērsotu indeksa lapas, ir ievērojami mazāks nekā I/O darbību skaits, kas nepieciešams, lai šķērsotu atbilstošās datu lapas. Citiem vārdiem sakot, tabulas skenēšanai, iespējams, būs nepieciešams daudz vairāk I/O darbību nekā tabulas indeksa skenēšanai.
Datu bāzes dzinēja indeksi tiek izveidoti, izmantojot B+ koka datu struktūru. B+ kokam ir koka struktūra, kurā visi zemākie mezgli atrodas vienādu līmeņu attālumā no koka augšdaļas (saknes mezgla). Šis rekvizīts tiek saglabāts pat tad, ja dati tiek pievienoti indeksētajai kolonnai vai noņemti no tās.
Tālāk esošajā attēlā ir parādīta B+ koka struktūra tabulai Darbinieks un tieša piekļuve šīs tabulas rindai ar Id kolonnas vērtību 25348. (Mēs pieņemam, ka tabulu Darbinieks indeksē kolonna Id.) Šajā attēlā var arī redzēt, ka B+ koks sastāv no saknes mezgla, koka mezgliem un nulles vai vairākiem starpmezgliem:
Šajā kokā varat meklēt vērtību 25348 šādi. Sākot no koka saknes, tā meklē mazāko atslēgas vērtību, kas ir lielāka vai vienāda ar nepieciešamo vērtību. Tādējādi saknes mezglā šī vērtība būs 29346, tāpēc tiek veikta pāreja uz starpmezglu, kas saistīts ar šo vērtību. Šajā mezglā vērtība 28559 atbilst noteiktajām prasībām, kā rezultātā tiek veikta pāreja uz koka mezglu, kas saistīts ar šo vērtību. Šis mezgls satur vēlamo vērtību 25348. Nosakot vajadzīgo indeksu, mēs varam izvilkt tā rindu no datu tabulas, izmantojot atbilstošos rādītājus. (Alternatīva līdzvērtīga pieeja būtu meklēt vērtību, kas ir mazāka par indeksu vai vienāda ar to.)
Indeksētā meklēšana parasti ir vēlamā metode, lai meklētu tabulas ar lielu rindu skaitu, jo tai ir acīmredzamas priekšrocības. Izmantojot indeksēto meklēšanu, mēs varam atrast jebkuru tabulas rindu ļoti īsā laikā, izmantojot tikai dažas I/O darbības. Un secīgā meklēšana (t.i., tabulas skenēšana no pirmās rindas līdz pēdējai) aizņem vairāk laika, jo tālāk atrodas vajadzīgā rinda.
Nākamajās sadaļās mēs apskatīsim divus esošos indeksu veidus — grupētos un negrupētos — un uzzināsim, kā izveidot indeksus.
Klasterizēti indeksi
Klasterizēts indekss nosaka datu fizisko secību tabulā. Datu bāzes programma ļauj tabulai izveidot tikai vienu klasterizētu indeksu, jo Tabulas rindas nevar fiziski sakārtot vairāk nekā vienā veidā. Meklēšana, izmantojot klasterizētu indeksu, tiek veikta no B+ koka saknes mezgla uz koka mezgliem, kas ir saistīti kopā divkāršā sarakstā ar nosaukumu lapu ķēde.
Svarīgs klasterizēta indeksa īpašums ir tas, ka tā koka mezglos ir datu lapas. (Visos citos klasterizēto indeksa mezglu līmeņos ir indeksa lapas.) Tabulu, kurai ir definēts (tieši vai netieši) klasterizēts indekss, sauc par klasterētu tabulu. Klasterizēta indeksa B+ koka struktūra ir parādīta attēlā zemāk:

Klasterizēts indekss pēc noklusējuma tiek izveidots katrā tabulā, kurai ir primārā atslēga, ko nosaka primārās atslēgas ierobežojums. Turklāt katrs klasterizētais indekss pēc noklusējuma ir unikāls, t.i. Kolonnā, kurā ir definēts kopu indekss, katra datu vērtība var parādīties tikai vienu reizi. Ja kolonnā, kurā ir dublētas vērtības, tiek izveidots klasterizēts indekss, datu bāzes sistēma nodrošina nepārprotamību, pievienojot četru baitu identifikatoru rindām, kurās ir dublētas vērtības.
Klasterizētie indeksi nodrošina ļoti ātru piekļuvi datiem, kad vaicājums meklē vērtību diapazonu.
Negrupēti indeksi
Negrupēta indeksa struktūra ir tieši tāda pati kā klasterizēta indeksa struktūra, taču ar divām būtiskām atšķirībām:
negrupēts indekss nemaina tabulas rindu fizisko secību;
Negrupētas indeksa mezglu lapas sastāv no indeksa atslēgām un grāmatzīmēm.
Ja tabulā definējat vienu vai vairākus negrupētus indeksus, tabulas rindu fiziskā secība netiks mainīta. Katram negrupētam indeksam datu bāzes programma izveido papildu indeksa struktūru, kas tiek glabāta rādītāja lapās. Nesagrupēta indeksa B+ koka struktūra ir parādīta zemāk esošajā attēlā:

Grāmatzīme negrupētā rādītājā norāda, kur atrodas indeksa atslēgai atbilstošā rinda. Indeksa atslēgas grāmatzīmju komponents var būt divu veidu atkarībā no tā, vai tabula ir grupēta tabula vai kaudze. (SQL Server terminoloģijā kaudze ir tabula bez klasterizēta indeksa.) Ja pastāv klasterizēts indekss, cilnē negrupēts indekss tiek rādīts tabulas kopu indeksa B+ koks. Ja tabulai nav grupēta indeksa, grāmatzīme ir identiska rindas identifikators (RID — rindas identifikators), kas sastāv no trim daļām: faila adreses, kurā tiek glabāta tabula, fiziskā bloka (lapas), kurā tiek saglabāta rinda, adrese un rindas nobīde lapā.
Kā minēts iepriekš, datu meklēšanu, izmantojot negrupētu indeksu, var veikt divos dažādos veidos atkarībā no tabulas veida:
kaudze - šķērso neklasterēta indeksa meklēšanas struktūru, pēc kuras rinda tiek izgūta, izmantojot rindas identifikatoru;
klasterizēta tabula — neklasterēta indeksa struktūras meklēšana, kam seko atbilstošā klasterizētā indeksa šķērsošana.
Abos gadījumos ievades/izvades operāciju skaits ir diezgan liels, tāpēc jums vajadzētu izveidot negrupētu indeksu piesardzīgi un izmantot to tikai tad, ja esat pārliecināts, ka tā izmantošana ievērojami uzlabos veiktspēju.
Transact-SQL valoda un indeksi
Tagad, kad esam iepazinušies ar indeksu fizisko struktūru, šajā sadaļā apskatīsim, kā izveidot, modificēt un dzēst indeksus, kā arī iegūt informāciju par indeksu sadrumstalotību un rediģēt indeksa informāciju. Tas viss sagatavos mūs turpmākai diskusijai par indeksu izmantošanu sistēmas veiktspējas uzlabošanai.
Indeksu veidošana
Izmantojot priekšrakstu, tabulā tiek izveidots rādītājs IZVEIDOT INDEKSU. Šai instrukcijai ir šāda sintakse:
CREATE INDEX indeksa_nosaukums ON tabulas_nosaukums (kolonna1 ,...) [ IEKĻAUTI (kolonnas_nosaukums [ ,... ]) ] [[, ] PAD_INDEX = (IESL | IZSL.)] [[, ] DROP_EXISTING = (IESL | IZSL.)] [[ , ] SORT_IN_TEMPDB = (IESLĒGTS | IZSLĒGTS)] [[, ] IGNORE_DUP_KEY = (IESLĒGTS | IZSLĒGTS)] [[, ] ALLOW_ROW_LOCKS = (ON | OFF)] [[, ] ALLOW_PAGE_LOCKS = (IESL | IZSL.)] [[, ] STATISTICS_NORECOMPUTE = (IESL. | IZSL.)] [[, ] ONLINE = (IESL. | IZSL.)]] Sintakses konvencijas
Parametrs index_name norāda veidojamā indeksa nosaukumu. Indeksu var izveidot vienā vai vairākās vienas tabulas kolonnās, kuras identificē ar parametru table_name. Kolonnu, kurā tiek izveidots indekss, norāda kolonna1 parametrs. Šī parametra skaitliskais sufikss norāda, ka indeksu var izveidot vairākās tabulas kolonnās. Datu bāzes dzinējs atbalsta arī indeksu izveidi skatos.
Varat indeksēt jebkuru tabulas kolonnu. Tas nozīmē, ka var indeksēt arī kolonnas, kurās ir datu tipu vērtības VARBINARY(max), BIGINT un SQL_VARIANT.
Indekss var būt vienkāršs vai salikts. Vienkāršs indekss tiek izveidots vienā kolonnā, savukārt saliktais indekss tiek izveidots vairākās kolonnās. Saliktajam indeksam ir noteikti ierobežojumi, kas saistīti ar tā lielumu un kolonnu skaitu. Indeksam var būt ne vairāk kā 900 baiti un ne vairāk kā 16 kolonnas.
UNIKĀLS parametrs norāda, ka indeksētajā kolonnā var būt tikai vienas vērtības (tas ir, neatkārtojas) vērtības. Vienvērtīgā saliktā indeksā unikālajam ir jābūt katras rindas visu kolonnu vērtību kombinācijai. Ja nav norādīts UNIKĀLAIS atslēgvārds, indeksētajā kolonnā(-s) ir atļauts dublēt vērtības.
CLUSTERED parametrs norāda klasterizētu indeksu un NONCLUSTERED parametrs(noklusējums) norāda, ka indekss nemaina tabulas rindu secību. Datu bāzes dzinējs tabulā pieļauj ne vairāk kā 249 negrupētus indeksus.
Datu bāzes programma ir uzlabota, lai atbalstītu indeksus kolonnu vērtību dilstošā secībā. Parametrs ASC aiz kolonnas nosaukuma norāda, ka indekss tiek izveidots kolonnu vērtību augošā secībā, bet parametrs DESC norāda indeksa kolonnas vērtību dilstošā secībā. Tas nodrošina lielāku elastību indeksa izmantošanā. Dilstošā secībā jums ir jāizveido salikti indeksi kolonnās, kuru vērtības ir sakārtotas pretējos virzienos.
IEKĻAUTS parametrsĻauj norādīt neatslēgas kolonnas, kas tiek pievienotas negrupēta indeksa mezglu lapām. Kolonnu nosaukumi sarakstā IEKĻAUTI nedrīkst atkārtoties, un kolonnu nevar izmantot gan kā atslēgu, gan kā kolonnu bez atslēgas.
Lai patiesi saprastu parametra IEKĻAUTS lietderību, jums ir jāsaprot, kas tas ir aptverošais indekss. Ja rādītājā ir iekļautas visas vaicājumu kolonnas, varat iegūt ievērojamus veiktspējas uzlabojumus, jo Vaicājumu optimizētājs var atrast visas kolonnu vērtības indeksa lapās, nepiekļūstot tabulas datiem. Šo iespēju sauc par aptverošo indeksu vai aptverošo vaicājumu. Tāpēc papildu bezatslēgas kolonnu iekļaušana nesagrupēto indeksa mezglu lapās ļaus iegūt vairāk pārklājuma vaicājumu un ievērojami uzlabot to veiktspēju.
FILLFACTOR parametrs norāda katras indeksa lapas procentuālo daudzumu, kas jāaizpilda rādītāja izveides laikā. FILLFACTOR parametra vērtību var iestatīt diapazonā no 1 līdz 100. Ar vērtību n=100 katra rādītāja lapa tiek aizpildīta līdz 100%, t.i. esošajā mezgla lapā, kā arī lapā bez mezgla nebūs brīvas vietas jaunu rindu ievietošanai. Tāpēc šo vērtību ieteicams izmantot tikai statiskām tabulām. (Noklusējuma vērtība n=0 nozīmē, ka indeksa mezgla lapas ir pilnas un katrā starplapā ir brīva vieta vienam ierakstam.)
Ja parametram FILLFACTOR ir iestatītas vērtības no 1 līdz 99, izveidotās indeksa struktūras mezglu lapās būs brīva vieta. Jo lielāka ir n vērtība, jo mazāk brīvas vietas ir indeksa mezgla lapās. Piemēram, ja n=60, katrā indeksa mezgla lapā būs 40% brīvas vietas turpmākai indeksa rindu ievietošanai. (Indeksa rindas tiek ievietotas, izmantojot INSERT vai UPDATE priekšrakstu.) Tādējādi tabulām, kuru dati mainās diezgan bieži, būtu saprātīga vērtība n=60. FILLFACTOR vērtībām no 1 līdz 99 starpposma rādītāja lapās ir brīva vieta vienam ierakstam katrā.
Kad indekss ir izveidots, FILLFACTOR vērtība lietošanas laikā netiek atbalstīta. Citiem vārdiem sakot, iestatot brīvās vietas procentuālo daudzumu, tas norāda tikai ar pieejamajiem datiem rezervētās vietas apjomu. Lai atjaunotu parametra FILLFACTOR sākotnējo vērtību, izmantojiet priekšrakstu ALTER INDEX.
PAD_INDEX parametrs ir cieši saistīts ar parametru FILLFACTOR. Parametrs FILLFACTOR pamatā norāda brīvās vietas daudzumu procentos no indeksa mezglu kopējā lapas izmēra. Un parametrs PAD_INDEX norāda, ka parametra FILLFACTOR vērtība attiecas gan uz indeksa lapām, gan uz datu lapām rādītājā.
DROP_EXISTING parametrsĻauj uzlabot veiktspēju, reproducējot grupētu indeksu tabulā, kurā ir arī negrupēts indekss. Papildinformāciju skatiet tālāk esošajā sadaļā "Indeksa atjaunošana".
SORT_IN_TEMPDB parametrs izmanto, lai tempdb sistēmas datu bāzē ievietotu datus no starpposma šķirošanas darbībām, ko izmanto, veidojot indeksu. Tas var uzlabot veiktspēju, ja tempdb atrodas citā diskā, nevis dati.
IGNORE_DUP_KEY parametrsĻauj sistēmai ignorēt mēģinājumu ievietot dublētās vērtības indeksētās kolonnās. Šo opciju vajadzētu izmantot tikai, lai izvairītos no ilgstošas transakcijas pārtraukšanas, kad INSERT priekšraksts indeksētā kolonnā ievieto datu dublikātus. Kad šī opcija ir iespējota, kad INSERT priekšraksts mēģina tabulā ievietot rindas, kas pārkāpj indeksa unikalitāti, datu bāzes sistēma vienkārši izdod brīdinājumu, nevis avarē visu priekšrakstu. Šajā gadījumā datu bāzes programma neievieto rindas ar dublētām atslēgu vērtībām, bet vienkārši ignorē tās un pievieno pareizās rindas. Ja šis parametrs nav iestatīts, visas instrukcijas izpilde tiks pārtraukta neparasti.
Kad parametrs ALLOW_ROW_LOCKS aktivizēts (ieslēgts), sistēma piemēro rindu bloķēšanu. Tāpat, kad tas ir aktivizēts parametrs ALLOW_PAGE_LOCKS, sistēma piemēro lapu bloķēšanu vienlaicīgas piekļuves laikā. STATISTICS_NORECOMPUTE parametrs nosaka automātiskās statistikas pārrēķina stāvokli norādītajam indeksam.
Aktivizēts ONLINE parametrsļauj izveidot, atkārtoti izveidot un dzēst indeksu dialoga režīmā. Šī opcija ļauj vienlaikus mainīt galvenās tabulas vai kopu indeksa datus un visus saistītos indeksus, mainot indeksu. Piemēram, kamēr tiek atkārtoti izveidots klasterizēts indekss, varat turpināt atjaunināt tā datus un izpildīt vaicājumus par šiem datiem.
Parametrs IESLĒGTS izveido norādīto indeksu vai nu noklusējuma failu grupā (noklusējuma vērtība), vai norādītajā failu grupā (file_group vērtība).
Tālāk esošajā piemērā parādīts, kā tabulas Darbinieks kolonnā Id izveidot negrupētu indeksu.
IZMANTOT SampleDb; CREATE INDEX ix_empid ON Employee(ID);
Vienvērtīga saliktā indeksa izveide ir parādīta tālāk esošajā piemērā.
IZMANTOT SampleDb; IZVEIDOT UNIKĀLU INDEKSU ix_empid_prnu ON Works_on (EmpId, ProjectNumber) AR FILLFACTOR= 80;
Šajā piemērā vērtībām katrā kolonnā jābūt vienciparam. Kad indekss ir izveidots, tiek aizpildīti 80% no vietas katrā indeksa mezgla lapā.
Kolonnai nevar izveidot unikālu indeksu, ja kolonnā ir dublētas vērtības. Šādu indeksu var izveidot tikai tad, ja katra vērtība (ieskaitot NULL vērtības) kolonnā parādās tieši vienu reizi. Turklāt sistēma noraidīs jebkuru mēģinājumu ievietot vai mainīt esošu datu vērtību kolonnā, kas iekļauta esošajā unikālajā indeksā, ja vērtība tiek dublēta.
Informācijas iegūšana par indeksu sadrumstalotību
Indeksa darbības laikā tas var sadrumstalot, padarot datu glabāšanas procesu indeksa lapās neefektīvu. Ir divu veidu indeksu sadrumstalotība: iekšējā sadrumstalotība un ārējā sadrumstalotība. Iekšējā sadrumstalotība nosaka katrā lapā saglabāto datu apjomu, savukārt ārējā sadrumstalotība notiek, ja lapas nav loģiskās secībā.
Lai iegūtu informāciju par iekšējo indeksu sadrumstalotību, tiek izsaukts DMV dinamiskās pārvaldības skats sys.dm_db_index_physical_stats. Šis DMV atgriež informāciju par norādītās lapas datu un indeksu apjomu un sadrumstalotību. Katrai lapai tiek atgriezta viena rinda katram B+ koka līmenim. Izmantojot šo DMV, jūs varat iegūt informāciju par rindu sadrumstalotības pakāpi datu lapās, pamatojoties uz kuru jūs varat izlemt, vai datus reorganizēt.
Skata sys.dm_db_index_physical_stats izmantošana ir parādīta tālāk esošajā piemērā. (Pirms palaižat pakešu piemēru, jums ir jāatmet visi esošie indeksi tabulā Works_on. Lai atmestu indeksus, izmantojiet priekšrakstu DROP INDEX, kas tiks parādīts vēlāk.)
IZMANTOT SampleDb; DEKLARĒT @dbId INT; DEKLARĒT @tabId INT; DEKLARĒT @indId INT; SET @dbId = DB_ID("SampleDb"); SET @tabId = OBJECT_ID("Darbinieks"); SELECT avg_fragmentation_in_percent, avg_page_space_used_in_percent FROM sys.dm_db_index_physical_stats (@dbId, @tabId, NULL, NULL, NULL);
Kā redzams piemērā, skatam sys.dm_db_index_physical_stats ir pieci parametri. Pirmie trīs parametri definē attiecīgi pašreizējās datu bāzes, tabulas un indeksa ID. Ceturtais parametrs norāda nodalījuma ID, bet pēdējais parametrs norāda skenēšanas līmeni, kas tiek izmantots statistikas informācijas iegūšanai. (Noklusējuma vērtību konkrētam parametram var norādīt, izmantojot vērtību NULL.)
Svarīgākās no šī skata kolonnām ir kolonnas avg_fragmentation_in_percent un avg_page_space_used_in_percent. Pirmais norāda vidējo sadrumstalotības līmeni procentos, bet otrais nosaka aizņemtās telpas apjomu procentos.
Rediģēt rādītāja informāciju
Kad esat iepazinies ar indeksa fragmentācijas informāciju, kā aprakstīts iepriekšējā sadaļā, varat rediģēt šo un citu indeksa informāciju, izmantojot šādus sistēmas rīkus:
direktoriju skati sys.indexes;
kataloga skati sys.index_columns;
sistēmas procedūra sp_helpindex;
objekta īpašuma īpašuma funkcijas;
SQL Server Management Studio pārvaldības vide;
DMV dinamiskās pārvaldības skats sys.dm_db_index_usage_stats;
DMV dinamiskās pārvaldības skats sys.dm_db_missing_index_details.
Kataloga skats sys.indexes satur rindu katram indeksam un rindu katrai tabulai bez klasterizēta indeksa. Svarīgākās šī kataloga skata kolonnas ir slejas object_id, name un index_id. Slejā object_id ir ietverts tā datu bāzes objekta nosaukums, kuram pieder indekss, un kolonnas name un index_id satur attiecīgi šī indeksa nosaukumu un ID.
Kataloga skats sys.index_columns satur rindu katrai kolonnai, kas ir daļa no rādītāja vai kaudzes. Šo informāciju var izmantot kopā ar informāciju, kas iegūta, izmantojot sys.indexes kataloga skatu, lai iegūtu papildu informāciju par norādītā indeksa īpašībām.
Sistēmas procedūra sp_helpindex atgriež informāciju par tabulas indeksiem, kā arī statistisko informāciju kolonnām. Šai procedūrai ir šāda sintakse:
sp_helpindex [@db_object = ] "nosaukums"
Šeit mainīgais @db_object apzīmē tabulas nosaukumu.
Attiecībā uz indeksiem, objekta īpašuma funkcija ir divas īpašības: IsIndexed un IsIndexable. Pirmais rekvizīts sniedz informāciju par to, vai tabulai vai skatam ir indekss, bet otrais rekvizīts norāda, vai tabula vai skats ir indeksējams.
Lai rediģētu esošo indeksa informāciju, izmantojot SQL Server Management Studio, atlasiet vajadzīgo datu bāzi mapē Databases, izvērsiet mezglu Tabulas un šajā mezglā izvērsiet vajadzīgo tabulu un tās mapi Indeksi. Tabulas mapē Indeksi tiks parādīts visu šīs tabulas esošo indeksu saraksts. Veicot dubultklikšķi uz indeksa, tiks atvērts dialoglodziņš Index Properties ar šī indeksa rekvizītiem. (Varat arī izveidot jaunu indeksu vai dzēst esošu, izmantojot Management Studio.)
Performance sys.dm_db_index_usage_stats atgriež dažādu veidu indeksa darbību skaitu un pēdējo reizi, kad katra veida darbība tika veikta. Katra atsevišķa meklēšanas, uzmeklēšanas vai atjaunināšanas darbība noteiktā indeksā vienā vaicājumā tiek uzskatīta par indeksa izmantošanu un palielina attiecīgo skaitītāju šajā DMV par vienu. Tādā veidā jūs varat iegūt vispārīgu informāciju par to, cik bieži indekss tiek izmantots, lai jūs varētu to izmantot, lai noteiktu, kuri indeksi tiek izmantoti vairāk un kuri tiek izmantoti mazāk.
Performance sys.dm_db_missing_index_details Atgriež detalizētu informāciju par tabulas kolonnām, kurām nav indeksu. Svarīgākās šī DMV kolonnas ir kolonnas index_handle un object_id. Vērtība pirmajā kolonnā identificē konkrēto trūkstošo indeksu, un vērtība otrajā kolonnā norāda tabulu, kurā indeksa trūkst.
Mainot indeksus
Datu bāzes dzinējs ir viena no nedaudzajām datu bāzes sistēmām, kas atbalsta paziņojumu MAINĪT INDEKSU. Šo paziņojumu var izmantot, lai veiktu indeksa uzturēšanas darbības. Priekšraksta ALTER INDEX sintakse ir ļoti līdzīga priekšraksta CREATE INDEX sintaksei. Citiem vārdiem sakot, šis priekšraksts ļauj mainīt parametru ALLOW_ROW_LOCKS, ALLOW_PAGE_LOCKS, IGNORE_DUP_KEY un STATISTICS_NORECOMPUTE vērtības, kas tika aprakstītas iepriekš priekšrakstā CREATE INDEX.
Papildus iepriekš minētajām opcijām ALTER INDEX priekšraksts atbalsta trīs citas opcijas:
REBUILD parametrs, ko izmanto indeksa atjaunošanai;
REORGANIZE parametrs, ko izmanto indeksa mezglu lapu pārkārtošanai;
IZSLĒGT parametru, ko izmanto indeksa atspējošanai. Šīs trīs iespējas ir aplūkotas turpmākajās apakšnodaļās.
Indeksa atjaunošana
Jebkuras izmaiņas datos, izmantojot INSERT, UPDATE vai DELETE priekšrakstus, var izraisīt datu sadrumstalotību. Ja šie dati ir indeksēti, tad ir iespējama arī indeksa sadrumstalotība, indeksa informācijai izkliedējot dažādas fiziskās lapas. Indeksa datu sadrumstalotības rezultātā datu bāzes dzinējs var būt spiests veikt papildu datu nolasīšanas darbības, kas samazina kopējo sistēmas veiktspēju. Šajā gadījumā jums ir jāpārbūvē visi sadrumstalotie indeksi.
To var izdarīt divos veidos:
izmantojot priekšraksta ALTER INDEX parametru REBUILD;
izmantojot priekšraksta CREATE INDEX parametru DROP_EXISTING.
Parametrs REBUILD tiek izmantots indeksu atjaunošanai. Ja šim parametram norādīsiet ALL, nevis indeksa nosaukumu, visi tabulā esošie indeksi tiks izveidoti no jauna. (Atļaujot indeksus dinamiski izveidot no jauna, jums tie nebūs jāatmet un jāizveido no jauna.)
CREATE INDEX priekšraksta opcija DROP_EXISTING var uzlabot veiktspēju, atkārtoti izveidojot grupētu indeksu tabulā, kurā ir arī negrupēti indeksi. Tajā ir norādīts, ka esošs klasterizēts vai negrupēts indekss ir jāatmet un norādītais indekss ir jāizveido no jauna. Kā minēts iepriekš, katrs klasterizētās tabulas negrupētais indekss savos koka mezglos satur atbilstošās tabulas grupētā indeksa vērtības. Šī iemesla dēļ, nometot klasterizētu indeksu tabulā, jums ir atkārtoti jāizveido visi tā negrupētie indeksi. Izmantojot parametru DROP_EXISTING, vairs nav atkārtoti jāveido negrupēti indeksi.
Opcija DROP_EXISTING ir jaudīgāka par opciju REBUILD, jo tā ir elastīgāka un nodrošina vairākas iespējas, piemēram, mainīt kolonnas, kas veido indeksu, un mainīt negrupētu indeksu uz grupētu indeksu.
Indeksa mezglu lapu pārkārtošana
Paziņojuma ALTER INDEX parametrs REORGANIZE pārkārto norādītā indeksa mezglu lapas tā, lai lapu fiziskā secība atbilstu to loģiskajai secībai no kreisās uz labo pusi. Tas novērš zināmu indeksa sadrumstalotību, uzlabojot indeksa veiktspēju.
Atspējot indeksu
Opcija DISABLE atspējo norādīto indeksu. Atspējots indekss nav pieejams lietošanai, kamēr tas nav atkal iespējots. Ņemiet vērā, ka atspējots rādītājs nemainās, ja tiek veiktas izmaiņas saistītajos datos. Šī iemesla dēļ, lai atkārtoti izmantotu atspējotu indeksu, tas ir pilnībā jāizveido no jauna. Lai iespējotu atspējotu indeksu, izmantojiet priekšraksta ALTER TABLE opciju REBUILD.
Ja tabulā ir atspējots klasterizēts indekss, tabulas dati nebūs pieejami, jo visas tabulas datu lapas ar grupēto indeksu tiek glabātas tās koka mezglos.
Indeksu noņemšana un pārdēvēšana
Lai noņemtu indeksus pašreizējā datu bāzē, izmantojiet DROP INDEX instrukcija. Ņemiet vērā, ka klasterizēta indeksa nomešana tabulā var būt ļoti resursietilpīga darbība, jo Visi negrupētie indeksi būs jāizveido no jauna. (Visi negrupētie indeksi izmanto grupētā indeksa indeksa atslēgu kā rādītāju to mezglu lapās.) Priekšraksta DROP INDEX izmantošana indeksa nomešanai ir parādīta tālāk esošajā piemērā:
IZMANTOT SampleDb; DROP INDEX ix_empid ON Darbinieks;
DROP INDEX instrukcijai ir papildu MOVE UZ parametru, kura nozīme ir tāda pati kā priekšraksta CREATE INDEX parametram ON. Citiem vārdiem sakot, varat izmantot šo parametru, lai norādītu, kur pārvietot datu rindas, kas atrodas sagrupēto indeksa mezglu lapās. Dati tiek pārvietoti uz jaunu vietu kā kaudze. Jaunajai datu glabāšanas vietai varat norādīt noklusējuma failu grupu vai failu grupu ar nosaukumu.
Paziņojumu DROP INDEX nevar izmantot, lai atmestu indeksus, ko sistēma ir izveidojusi netieši integritātes ierobežojumiem, piemēram, PRIMARY KEY un UNIQUE indeksus. Lai noņemtu šādus indeksus, ir jānoņem attiecīgais ierobežojums.
Indeksus var pārdēvēt, izmantojot sistēmas sp_rename procedūru.
Indeksus var izveidot, modificēt un dzēst arī programmā Management Studio, izmantojot datu bāzes diagrammas vai objektu pārlūku. Bet vienkāršākais veids ir izmantot vajadzīgās tabulas mapi Indeksi. Indeksu pārvaldība programmā Management Studio ir līdzīga tabulu pārvaldībai programmā Management Studio.
Lai gan datu bāzes programma nenosaka praktiskus ierobežojumus indeksu skaitam, ir daži iemesli, kāpēc jums vajadzētu to ierobežot. Pirmkārt, katrs rādītājs aizņem noteiktu vietu diskā, tāpēc pastāv iespēja, ka kopējais datu bāzes indeksa lapu skaits var pārsniegt datu lapu skaitu datu bāzē. Otrkārt, atšķirībā no indeksa izmantošanas datu izgūšanai, datu ievietošana un dzēšana nesniedz šādu labumu, jo indekss ir jāuztur. Jo vairāk indeksu ir tabulā, jo vairāk darba ir nepieciešams, lai tos reorganizētu. Parasti ir saprātīgi atlasīt indeksus biežiem vaicājumiem un pēc tam novērtēt to lietojumu.
Šajā sadaļā ir sniegti daži norādījumi par indeksu izveidi un lietošanu. Tālāk sniegtie ieteikumi ir tikai vispārīgi noteikumi. Galu galā to efektivitāte būs atkarīga no tā, kā datubāze tiek izmantota praksē un no visbiežāk izpildīto vaicājumu veida. Kolonnas, kas nekad netiks izmantota, indeksēšana nedos nekādu labumu.
Indeksi un WHERE klauzulas nosacījumi
Ja SELECT priekšraksta WHERE klauzula satur meklēšanas nosacījumu ar vienu kolonnu, tad šajā kolonnā ir jāizveido indekss. Tas ir īpaši ieteicams augstas selektivitātes apstākļos. Ar nosacījuma selektivitāti mēs saprotam to rindu skaita attiecību, kuras atbilst nosacījumam, pret kopējo rindu skaitu tabulā. Augsta selektivitāte atbilst zemākai šīs attiecības vērtībai. Meklēšanas apstrāde, izmantojot indeksētu kolonnu, būs visveiksmīgākā, ja nosacījuma selektivitāte ir mazāka par 5%.
Kolonnu nevajadzētu indeksēt, ja nosacījuma selektivitātes līmenis ir nemainīgs 80% vai vairāk. Šajā gadījumā indeksa lapām būs nepieciešamas papildu I/O darbības, kas samazinās laika ietaupījumu, kas panākts, izmantojot indeksus. Šajā gadījumā meklēšanu ir ātrāk veikt, skenējot tabulu, ko parasti izvēlas vaicājumu optimizētājs, padarot indeksu nederīgu.
Ja bieži izmantotā vaicājuma meklēšanas nosacījums satur operatorus UN, vislabāk ir izveidot saliktu indeksu visās tabulas kolonnās, kas norādītas priekšraksta SELECT WHERE klauzulā. Šāda saliktā indeksa izveide ir parādīta zemāk esošajā piemērā:
Šajā piemērā tiek izveidots salikts indekss visās WHERE klauzulas kolonnās. Šajā vaicājumā divi nosacījumi ir apvienoti UN, tāpēc šajos apstākļos abās kolonnās ir jāizveido salikts negrupēts indekss.
Indeksi un pievienošanās operators
Savienojuma darbībai ir ieteicams izveidot indeksu katrai kolonnai, kas tiek savienota. Savienotās kolonnas bieži attēlo vienas tabulas primāro atslēgu un citas tabulas atbilstošo ārējo atslēgu. Ja attiecīgajās savienošanas kolonnās norādāt PRIMARY KEY un FOREIGN KEY integritātes ierobežojumus, ārējās atslēgas kolonnā ir jāizveido tikai negrupēts indekss, jo sistēma netieši izveidos grupētu indeksu primārās atslēgas kolonnā.
Tālāk esošajā piemērā ir parādīts, kā izveidot indeksus, kas tiktu izmantoti, ja jums būtu vaicājums ar savienošanas darbību un papildu filtru:
Pārklājuma indekss
Kā minēts iepriekš, visu vaicājumu kolonnu iekļaušana rādītājā var ievērojami uzlabot vaicājuma veiktspēju. Šāda indeksa, ko sauc par pārklājumu, izveide ir parādīta zemāk esošajā piemērā:
IZMANTOT AdventureWorks2012; GO DROP INDEX Person.Address.IX_Address_StateProvinceID; GO CREATE INDEX ix_address_zip ON Person.Address(pasta indekss) IEKĻAUJ(pilsēta, štata provinces ID); GO SELECT City, StateProvinceID FROM Person.Address WHERE PostalCode = 84407;
Šajā piemērā vispirms no adreses tabulas tiek noņemts indekss IX_Address_StateProvinceID. Pēc tam tiek izveidots jauns rādītājs, kurā papildus pasta indeksa kolonnai ir iekļautas divas papildu kolonnas. Visbeidzot, priekšraksts SELECT piemēra beigās parāda vaicājumu, uz kuru attiecas indekss. Šim vaicājumam sistēmai nav jāmeklē dati datu lapās, jo vaicājuma optimizētājs var atrast visas kolonnu vērtības negrupēto indeksa mezglu lapās.
Ieteicams segt rādītājus, jo rādītāja lapās parasti ir daudz vairāk ierakstu nekā attiecīgajās datu lapās. Turklāt, lai izmantotu šo metodi, filtrējamajām kolonnām jābūt pirmajām rādītāja galvenajām kolonnām.
Indeksi aprēķinātajās kolonnās
Datu bāzes programma ļauj izveidot šādus īpašus indeksu veidus:
indeksēti skati;
filtrējami indeksi;
indeksi uz aprēķinātajām kolonnām;
sadalīti indeksi;
kolonnu noturības indeksi;
XML indeksi;
pilna teksta indeksi.
Šajā sadaļā ir apskatītas aprēķinātās kolonnas un ar tām saistītie indeksi.
Aprēķinātā kolonna ir tabulas kolonna, kurā tiek glabāti tabulas datu aprēķinu rezultāti. Šāda kolonna var būt virtuāla vai pastāvīga. Šie divi kolonnu veidi ir apskatīti turpmākajās apakšsadaļās.
Virtuālās aprēķinātās kolonnas
Aprēķināta kolonna, kurai nav atbilstoša klasterizēta indeksa, ir loģiskā kolonna, t.i. tas nav fiziski saglabāts cietajā diskā. Tādējādi tas tiek novērtēts katru reizi, kad tiek piekļūts rindai. Virtuālo aprēķināto kolonnu izmantošana ir parādīta zemāk esošajā piemērā:
IZMANTOT SampleDb; CREATE TABLE Pasūtījumi (OrderId INT NOT NULL, Price MONEY NOT NULL, Daudzums INT NOT NULL, OrderDate DATETIME NOT NULL, Total AS Price * Daudzums, ShippedDate AS DATEADD (DAY, 7, orderdate));
Tabulā Pasūtījumi šajā piemērā ir divas virtuālās aprēķinātās kolonnas: total un shippeddate. Kopējā kolonna tiek aprēķināta, izmantojot divas citas kolonnas — cena un daudzums, un kolonna shippeddate tiek aprēķināta, izmantojot funkciju DATEADD un kolonnu orderdate.
Pastāvīgi aprēķinātas kolonnas
Datu bāzes programma ļauj izveidot indeksus deterministiski aprēķinātām kolonnām, kur pamatā esošajām kolonnām ir precīzi datu tipi. (Aprēķinātā kolonna tiek uzskatīta par deterministisku, ja tā vienmēr atgriež vienas un tās pašas vērtības tiem pašiem tabulas datiem.)
Indeksētu aprēķināto kolonnu var izveidot tikai tad, ja šādi SET priekšraksta parametri ir iestatīti uz ON (šie parametri nodrošina, ka kolonna ir deterministiska):
QUOTED_IDENTIFIER
CONCAT_NULL_YIELDS_NULL
Turklāt parametram NUMERIC_ROUNDABORT jābūt izslēgtam.
Ja aprēķinātajā kolonnā izveidojat grupētu indeksu, kolonnas vērtības fiziski pastāvēs attiecīgajās tabulas rindās, jo grupētā indeksa mezglu lapās ir datu rindas. Tālāk sniegtajā piemērā tiek izveidots klasterizēts indekss aprēķinātajai kolonnu kopsummai no tabulas Pasūtījumi:
IZMANTOT SampleDb; IZVEIDOT KLASTERĒTU INDEKSU ix1 ON Pasūtījumi (kopā);
Pēc priekšraksta CREATE INDEX izpildes aprēķinātā kopējā kolonna fiziski būs redzama tabulā. Tas nozīmē, ka visi aprēķinātās kolonnas pamatā esošo kolonnu atjauninājumi izraisīs tās atjaunināšanu.
Kolonnu var padarīt nemainīgu citā veidā, izmantojot PERSISTED parametrs. Šī opcija ļauj norādīt aprēķinātās kolonnas fizisko klātbūtni, pat neveidojot atbilstošu kopu indeksu. Šī iespēja ir nepieciešama, lai izveidotu fiziskas aprēķinātas kolonnas, kuras tiek izveidotas kolonnās ar aptuvenu datu tipu (peldošs vai reāls). (Kā minēts iepriekš, indeksu var izveidot aprēķinātajā kolonnā tikai tad, ja tā pamatā esošās kolonnas ir ar precīzu datu tipu.)
Šajā iesācējiem paredzētajā rakstā apskatīšu, kā noteikt nepieciešamos indeksus, lai palielinātu SQL vaicājumu izpildes ātrumu.
Faktiski ar indeksiem ir saistītas daudzas smalkumus, kas var būtiski ietekmēt veiktspēju gan vienā virzienā, gan pretējā virzienā. Internetā par to var atrast daudz rakstu. Apjomīgi raksti, kas izskaidro atšķirības adresēšanā, atmiņas glabāšanā un daudzās citās lietās.
Tās, protams, ir patiešām noderīgas lietas, taču tajās bieži vien pietrūkst viena maza nianse – datu apjomi, pie kuriem visām šīm funkcijām patiešām ir jūtama ietekme. Un šis skaitlis parasti tiek mērīts simtos tūkstošu ierakstu. Vienkāršiem vārdiem sakot, ja jūsu tabulās ir aptuveni 1-30 tūkstoši ierakstu un mēs runājam par vietni (vai līdzīgu resursu), nevis kaut kādu starpposma datu glabātuvi ielādētām sistēmām, tad visbiežāk ir svarīgāk vienkārši izveidojiet pareizos indeksus. Šeit ir svarīgi atzīmēt, ka jums nav jābūt ļoti tehniski gudram. Daudzus noderīgus indeksus var izveidot, izmantojot vienkāršu loģiku.
Piezīme: tiek pieņemts, ka paši vaicājumi ir izveidoti vairāk vai mazāk optimāli, piemēram, atlasē nav papildu lauku utt.
Indekss veselu skaitļu identifikatora laukiem.
Ja jums ir lauks ar vesela skaitļa identifikatoru (nav svarīgi, vai tas ir pašas tabulas identifikators vai identifikators, kas norāda uz rindu citā tabulā), izveidojiet tam atsevišķu indeksu.
Lieta ir tāda. Ja lauks ir pašas tabulas ierakstu identifikators, tad mēs runājam par primāro atslēgu (tas ir arī indekss). Šādam indeksam ir daudz priekšrocību, jo vietnes visbiežāk darbojas ar identifikatoriem. Ja tas ir rindas identifikators no direktoriju tabulas, tad ir nepieciešams arī indekss. Tā kā, ja vajag filtrētus datus, tad bez indeksiem šie direktoriji nav īpaši noderīgi (nu, varbūt tikai datu bāzes lielums).
Ja ar pirmo gadījumu viss ir pavisam vienkārši un skaidri, tad otrajam gadījumam (ar uzziņu grāmatu) sniegšu vienkāršu piemēru.
Pieņemsim, ka ir divas tabulas: raksti (raksta id, nosaukums, teksts) un komentāri (komentārs — id, raksta_id, teksts). Pirmajā tabulā ir 200 ieraksti (raksti), otrajā tabulā ir 2000 ieraksti (katram rakstam 10 komentāri). Attiecīgi, kad katrs lietotājs atver kādu rakstu, tiek izpildīts šāds vaicājums:
Ja sql vaicājums tiek izpildīts bez indeksa laukam article_id, tad katru reizi tiks pilnībā skenēta visa tabula ar komentāriem (visi 2000 ieraksti). Ja laukam article_id ir pievienots indekss, datu bāzei būs jāaplūko ne vairāk kā 20 ieraksti (precīzāk, sliktākajā gadījumā aptuveni 18). Šeit aprēķins ir vienkāršs. Sliktākajā gadījumā indeksa meklēšana notiek ar aptuveni ierakstu skaita binārā logaritma + ierakstu skaita ar vienādu indeksa lauka vērtību ātrumu. Šajā gadījumā katram rakstam ir 10 ieraksti (to vērtības tiek atkārtotas) + log2 no 200 (jo ir tikai 200 rakstu = 2000 / 10) = 10 + 8 (noapaļots uz augšu) = 18.
Protams, katrs šāds indekss papildus diska vietai, ko tas aizņem, arī ievieš papildu datu bāzes izmaksas ievietošanai, atjaunināšanai un dzēšanai. Galu galā, papildus pašas tabulas datu maiņai, ir arī jāpārveido tās indeksi. Bet, kā jau teicu, parasto vietņu apjomam tas nav nekas liels. Un pat tad, ja jūs izveidojat indeksu tabulā, kuru neizmantojat savos SQL vaicājumos, tas neradīs ievērojamas problēmas. Turklāt vienmēr ir iespējams, ka, uzstādot papildu moduli vai pašam pievienojot vaicājumus, šis rādītājs var ļoti noderēt.
Piezīme: Tomēr atcerieties, ka tas attiecas tieši uz veselu skaitļu indeksiem, nevis uz opciju “Ļaujiet man izveidot indeksus visiem iespējamajiem laukiem”.
Vienkārši un salikti indeksi visbiežāk sastopamajiem vaicājumiem.
Daudzām datu bāzēm ir vaicājumu rezultātu kešatmiņa. Mēģiniet izpildīt vienu un to pašu pieprasījumu divas reizes pēc kārtas - pirmajā gadījumā pieprasījuma izpilde prasīs ilgu laiku, otrajā - ātri. Pirmajā reizē dati tiks aprēķināti, otrajā reizē dati tiks sniegti no kešatmiņas. Tomēr tas nepalīdz gadījumos, kad vaicājumiem nav izveidota kešatmiņa (piemēram, ja filtrā ir aprēķināti nosacījumi, izmantojot iebūvētās datu bāzes funkcijas), gadījumos, kad vaicājumi, lai arī ir viena veida, tiek izmantoti ar dažādiem parametriem, un tajos gadījumos , kad pieprasījumu ir daudz un tāpēc dati kešatmiņā tiek glabāti ļoti īsu laiku.
Tāpēc periodiski var būt lietderīgi papildus veidot regulārus un saliktus indeksus bieži izpildītiem vaicājumiem. Apskatīsim divus piemērus.
Vienkāršs rādītājs.
Pieņemsim, ka jums ir tabula - produkti (produkts - id, kods, nosaukums, teksts). Un tā notiek, ka vietnes lietotāji bieži meklē preces pēc to burtciparu kodiem (raksti - koda lauks). Attiecīgi pieprasījums izskatās apmēram šādi:
Šādā situācijā ir lietderīgi izveidot atsevišķu indeksu laukam "kods", jo ar to datu bāzei nebūs pilnībā jāpārbauda visi tabulas ieraksti. Tomēr, lūdzu, ņemiet vērā, ka datu bāzēm var būt ierobežojumi lauku veidiem un izmēriem. Tāpēc vispirms ir jāpārbauda, vai šādiem laukiem ir iespējams izveidot indeksu.
Salikts indekss.
Pirms sniegt piemēru ar saliktu indeksu, es vēlos nedaudz precizēt vienu svarīgu punktu - lauku secība indeksā ir svarīga. Tā kā meklēšanu vispirms veic pirmais lauks un pēc tam nākamais lauks (un tā tālāk). Tāpēc, ja zināt tikai pēdējā lauka konkrēto vērtību, tad šāds indekss nebūs piemērots, jo, nezinot pirmā lauka konkrēto vērtību, nav iespējams noteikt, kura ierakstu kopa ir jāpārbauda, kas ir kāpēc datu bāzei būs jāskenē visi tabulas ieraksti. Vienkāršiem vārdiem sakot, indekss (kolonna_1, kolonna_2) nav vienāds ar indeksu (kolonna_2, kolonna_1).
Tagad pieņemsim šādu situāciju. Ir trīs tabulas: lietotājs (user - id, name), kategorija (cat - id, name) un raksts (raksts - id, cat_id, user_id, name, text). Un jūs to izdarījāt vietnē - raksta apakšā tiek parādīts pilns tā paša lietotāja rakstu saraksts no noteiktās kategorijas. Tajā pašā laikā lietotāji izrādījās tik ražīgi, ka raksta daudz rakstu, kaut arī dažādās kategorijās (piemēram, mazus stāstus, īsas piezīmes utt.). Šajā gadījumā pieprasījums izskatīsies šādi:
Ja esat izveidojis indeksus identifikatora laukiem, tas jums palīdzēs, bet ne daudz. Pirmkārt, ir divi vienādi iespējami indeksi. Viens kategorijām, bet otrs lietotājiem. Kurš no tiem būs labāks, parasti nav zināms. Tas var arī nepalīdzēt, jo lietotājiem var būt 1000 rakstu un kategorijām var būt 1000 rakstu. Otrkārt, pat samazinot ierakstus konkrētam lietotājam (vai kategorijai), tie joprojām būs jāskenē, izmantojot otro lauku, tas ir, pilnu skenēšanu (lai gan mazākam ierakstu apjomam). Piemēram, ja lietotājiem ir 1000 ierakstu, jums būs jāpārbauda visi 1000 ieraksti, vai tie pieder kategorijai vai nē.
Lielam skaitam ierakstu un biežiem zvaniem šis ir ļoti dārgs sql vaicājums. Tāpēc šajā gadījumā ir vērts izveidot, piemēram, saliktu indeksu (user_id, cat_id Šajā gadījumā pēc lietotāja meklēšanas turpmākā meklēšana pēc kategorijas būs ātrāka, jo iegūtajam būs arī indekss). ieraksti. Attiecīgi, tā vietā, lai pārbaudītu 1000 ierakstus, tiks pārbaudīts ievērojami mazāk (pārbaudes tiek aprēķinātas tāpat kā ar parasto indeksu - logaritms + ierakstu skaits).
Kā šādās situācijās var noteikt lauku secību? Šeit viss ir diezgan vienkārši un līdzīgi tam, ko es aprakstīju rakstā par filtrēšanu (skatiet saiti sākumā). Atgādināšu, ka būtība ir tāda, ka ar katru pielietoto filtru ierakstu skaits kļūst pēc iespējas mazāks. Tāpēc ir lietderīgi pārbaudīt vidējo ierakstu skaitu katrai tabulas lauka vērtībai. Un laukam ar šo skaitli mazāk jāiet pirmajam. Piemēram, konkrētam SQL vaicājumam ir vērts pārbaudīt sekojošo:
Aprēķināt vidējo ierakstu skaitu atlasītajiem lietotājiem -- Vidējais ierakstu skaits avg(data.count) kā vid. no -- Grupējiet visus ierakstus pēc identifikatora (atlasiet count(*) kā "skaits" no raksta -- Grupējiet pēc lietotāju grupas pēc user_id) kā dati ; -- Aprēķiniet vidējo ierakstu skaitu atlasītajām kategorijām -- Vidējais ierakstu skaits vid.(datu.skaits) kā vid. no -- Grupējiet visus ierakstus pēc identifikatora (izvēlieties skaitu(*) kā "skaits" no raksta -- Grupēšana pēc kategorijas) grupēt pēc cat_id ) kā datus ;
Attiecīgi, ja vidējais lietotāju skaits ir mazāks, šim laukam jābūt pirmajā vietā, jo pēc pirmās meklēšanas pārbaudāmo ierakstu būs maz. Pretējā gadījumā vispirms ir jābūt kategorijas ID.
Tomēr ir vērts saprast, ka šādā situācijā ir vērts arī pārbaudīt, vai ieraksti tiek sadalīti vairāk vai mazāk vienmērīgi. Galu galā var izrādīties, ka 1 lietotājs uzrakstīja 2000 rakstus, bet pārējie tikai 100. Šādā situācijā var būt vēlams filtrs pēc kategorijas, jo lielākā daļa lasītāju skatīs tieši šī lietotāja rakstus. Tāpēc dažreiz ir vērts aprēķināt tikai grupēšanu pēc identifikatoriem (neaprēķinot vidējo) un ātri apskatīt rezultātus.
Ja jums ir jāizveido indekss trim vai vairāk laukiem, jums jādara tas pats, tikai palielinot to lauku skaitu, kuriem tiek veikta grupēšana pēc identifikatora. Vienkāršiem vārdiem sakot, vispirms pārbaudiet pirmo lauku un nosakiet mazāko skaitli, pēc tam "grupēt pēc kolonnas_1" vietā norādiet dažādas opcijas ar atlikušajiem laukiem formā "grupēt pēc kolonnas_1, kolonnas_2", pēc tam "grupēt pēc kolonnas_1, kolonnas_3". un tā tālāk. Šajā gadījumā katrs izvēlas tās kombinācijas, kurās vidējais ierakstu skaits kļūst arvien mazāks.
Un indeksi, šis īpašas meklēšanas tabulas, ko datu bāzes meklētājprogramma var izmantot, lai paātrinātu datu izguvi. Vienkārši sakot, indekss ir rādītājs uz datiem tabulā. Indekss datubāzē ir ļoti līdzīgs rādītājam grāmatas aizmugurē.
Piemēram, ja vēlaties saites uz visām grāmatas lapām par konkrētu tēmu, vispirms skatiet rādītāju, kurā visas tēmas ir uzskaitītas alfabētiskā secībā un pēc tam ir atsauce uz vienu vai vairākiem konkrētiem lappušu numuriem.
Indekss palīdz paātrināt vaicājumus un teikumus, taču tas palēnina datu ievadi ar paziņojumiem ATJAUNINĀT Un IEVIETOT. Indeksus var izveidot vai dzēst, neietekmējot datus.
Indeksa izveide ietver paziņojumu IZVEIDOT INDEKSU, kas ļauj nosaukt indeksu, lai norādītu tabulu un kuru kolonnu vai kolonnas indeksēt, un norādītu, vai indekss ir augošā vai dilstošā secībā.
Indeksi var būt arī unikāli ar ierobežojumiem UNIKĀLS, lai indekss novērstu ierakstu dublikātus kolonnā vai kolonnu kombinācijā, kurā ir indekss.
Komanda CREATE INDEX
Pamata sintakse IZVEIDOT INDEKSU sekojoši:
CREATE INDEX index_name ON tabulas_nosaukums;
Vienas kolonnas indeksi
Vienas kolonnas indekss tiek izveidots tikai vienā tabulas kolonnā. Pamata sintakse ir šāda.
CREATE INDEX indeksa_nosaukums ON tabulas_nosaukums(kolonnas_nosaukums);
Unikāli indeksi
Unikālie indeksi tiek izmantoti ne tikai darbībai, bet arī datu integritātes nodrošināšanai. Unikāls indekss neļauj tabulā ievietot dublētās vērtības. Pamata sintakse ir šāda.
CREATE UNIQUE INDEX indeksa_nosaukums uz tabulas_nosaukums(kolonnas_nosaukums);
Saliktie indeksi
Saliktais indekss ir indekss divās vai vairākās tabulas kolonnās. Tās pamata sintakse ir šāda.
CREATE INDEX indeksa_nosaukums uz tabulas_nosaukums(kolonna1, kolonna2);
Neatkarīgi no tā, vai veidojat indeksu vienā kolonnā vai saliktā rādītājā, ņemiet vērā kolonnu(-as), kuras ļoti bieži varat izmantot WHERE vaicājumā kā filtra nosacījumu.
Ja tiek izmantota tikai viena kolonna, indekss ir jāizvēlas vienā kolonnā. Ja klauzulā WHERE ir divas vai vairākas kolonnas, kas bieži tiek izmantotas kā filtri, labāka izvēle būtu salikts indekss.
Netiešie indeksi
Netiešie indeksi ir indeksi, kas tiek automātiski izveidoti datu bāzes serverī, kad tiek izveidots objekts. Indeksi tiek automātiski izveidoti primārajai atslēgai un unikālajam ierobežojumam.
DROP INDEX komanda
Indeksu var izdzēst, izmantojot SQL komandu NOLIET. Dzēšot indeksu, jābūt uzmanīgiem, jo veiktspēja var būt lēnāka vai labāka.
Pamata sintakse izskatās šādi:
DROP INDEX indeksa_nosaukums;
Varat apskatīt INDEX ierobežojuma piemēru, lai redzētu dažus reālus indeksu piemērus.
Kad jums vajadzētu izvairīties no indeksiem?
Lai gan indeksi ir paredzēti, lai uzlabotu datu bāzes veiktspēju, ir gadījumi, kad no tiem vajadzētu izvairīties.
Tālāk sniegtie norādījumi norāda, kad indeksa lietošana ir jāpārskata.
- Indeksus nevajadzētu izmantot uz mazām tabulām.
- Tabulas, kurās bieži tiek veiktas lielas atjaunināšanas vai ievietošanas darbības.
- Indeksus nedrīkst izmantot kolonnās, kurās ir liels skaits nulles vērtību.
- Kolonnas, ar kurām bieži tiek manipulētas, nevajadzētu indeksēt.